Feature Store 的機器學習工作流程如下:
撰寫程式將原始資料轉換成特徵,並建立包含所需特徵的 Spark DataFrame。
將 DataFrame 寫入 Unity Catalog 中的 feature table。如果您的工作區未啟用 Unity Catalog,則將 DataFrame 寫入 Workspace Feature Store 中的 feature table。
使用 feature store 的特徵訓練模型。這樣做時,模型會儲存用於訓練的特徵規格。當模型用於推論時,它會自動連接來自適當 feature table 的特徵。
註冊模型到 Model Registry。
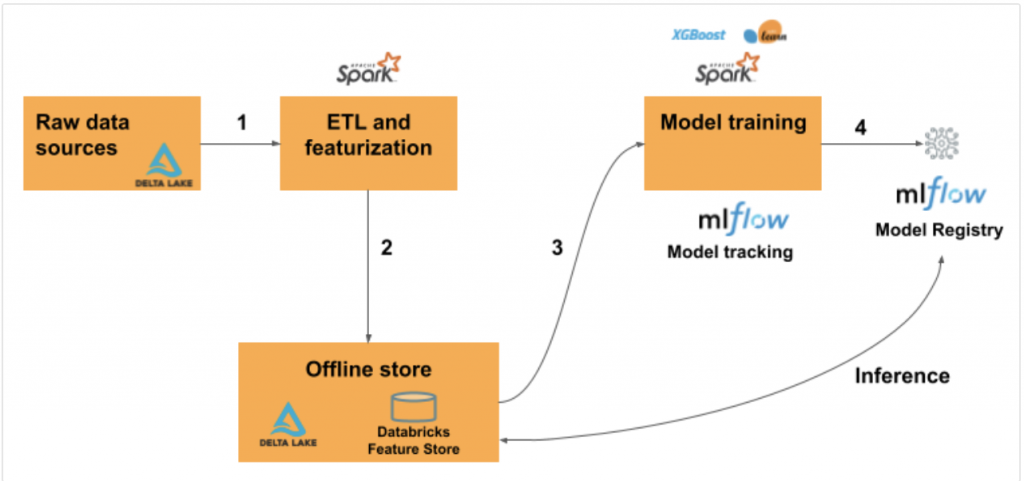
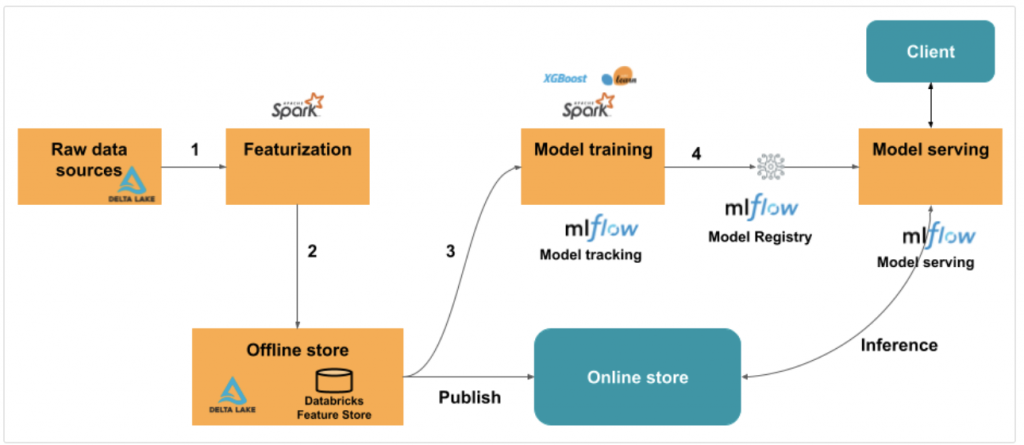
參考自這份文件,主要是示範透過 Databricks Unity Catalog 作 Feature Engineering,並將特徵寫入 Feature Store。
import pandas as pd
from pyspark.sql.functions import monotonically_increasing_id, expr, rand
import uuid
from databricks import feature_store
from databricks.feature_store import feature_table, FeatureLookup
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
raw_data = spark.read.load("/databricks-datasets/wine-quality/winequality-red.csv",format="csv",sep=";",inferSchema="true",header="true" )
def addIdColumn(dataframe, id_column_name):
"""Add id column to dataframe"""
columns = dataframe.columns
new_df = dataframe.withColumn(id_column_name, monotonically_increasing_id())
return new_df[[id_column_name] + columns]
def renameColumns(df):
"""Rename columns to be compatible with Feature Store"""
renamed_df = df
for column in df.columns:
renamed_df = renamed_df.withColumnRenamed(column, column.replace(' ', '_'))
return renamed_df
# Run functions
renamed_df = renameColumns(raw_data)
df = addIdColumn(renamed_df, 'wine_id')
# Drop target column ('quality') as it is not included in the feature table
features_df = df.drop('quality')
display(features_df)
# Create a new catalog with:
# spark.sql("CREATE CATALOG IF NOT EXISTS ml")
# spark.sql("USE CATALOG ml")
# Or reuse existing catalog:
spark.sql("USE CATALOG ml")
spark.sql("CREATE SCHEMA IF NOT EXISTS wine_db")
spark.sql("USE SCHEMA wine_db")
# Create a unique table name for each run. This prevents errors if you run the notebook multiple times.
table_name = f"ml.wine_db.wine_db_" + str(uuid.uuid4())[:6]
print(table_name)
FeatureStoreClient 建立 feature tablefs = feature_store.FeatureStoreClient()
# You can get help in the notebook for feature store API functions:
# help(fs.<function_name>)
# For example:
# help(fs.create_table)
fs.create_table(
name=table_name,
primary_keys=["wine_id"],
df=features_df,
schema=features_df.schema,
description="wine features"
)
FeatureStoreClient 也支援 overwrite, merge 等功能fs.create_table(
name=table_name,
primary_keys=["wine_id"],
schema=features_df.schema,
description="wine features"
)
fs.write_table(
name=table_name,
df=features_df,
mode="overwrite"
)
## inference_data_df includes wine_id (primary key), quality (prediction target), and a real time feature
inference_data_df = df.select("wine_id", "quality", (10 * rand()).alias("real_time_measurement"))
display(inference_data_df)
def load_data(table_name, lookup_key):
# In the FeatureLookup, if you do not provide the `feature_names` parameter, all features except primary keys are returned
model_feature_lookups = [FeatureLookup(table_name=table_name, lookup_key=lookup_key)]
# fs.create_training_set looks up features in model_feature_lookups that match the primary key from inference_data_df
training_set = fs.create_training_set(inference_data_df, model_feature_lookups, label="quality", exclude_columns="wine_id")
training_pd = training_set.load_df().toPandas()
# Create train and test datasets
X = training_pd.drop("quality", axis=1)
y = training_pd["quality"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test, training_set
# Create the train and test datasets
X_train, X_test, y_train, y_test, training_set = load_data(table_name, "wine_id")
X_train.head()
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
try:
client.delete_registered_model("wine_model") # Delete the model if already created
except:
None
經典的 Sklearn 模型訓練,不多解釋了。
# Disable MLflow autologging and instead log the model using Feature Store
mlflow.sklearn.autolog(log_models=False)
def train_model(X_train, X_test, y_train, y_test, training_set, fs):
## fit and log model
with mlflow.start_run() as run:
rf = RandomForestRegressor(max_depth=3, n_estimators=20, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
mlflow.log_metric("test_mse", mean_squared_error(y_test, y_pred))
mlflow.log_metric("test_r2_score", r2_score(y_test, y_pred))
fs.log_model(
model=rf,
artifact_path="wine_quality_prediction",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="wine_model",
)
train_model(X_train, X_test, y_train, y_test, training_set, fs)
score_batch 來 apply 已經 packaged feature store model。然後透過指定 primary key wine_id ,其他 feature 會自動從 feature store 取得。## For simplicity, this example uses inference_data_df as input data for prediction
batch_input_df = inference_data_df.drop("quality") # Drop the label column
predictions_df = fs.score_batch("models:/wine_model/latest", batch_input_df)
display(predictions_df["wine_id", "prediction"])
## Modify the dataframe containing the features
so2_cols = ["free_sulfur_dioxide", "total_sulfur_dioxide"]
new_features_df = (features_df.withColumn("average_so2", expr("+".join(so2_cols)) / 2))
display(new_features_df)
透過 mode="merge" 來更新 feature table
fs.write_table(
name=table_name,
df=new_features_df,
mode="merge"
)
# Displays most recent version of the feature table
# Note that features that were deleted in the current version still appear in the table but with value = null.
display(fs.read_table(name=table_name))
def load_data(table_name, lookup_key):
model_feature_lookups = [FeatureLookup(table_name=table_name, lookup_key=lookup_key)]
# fs.create_training_set will look up features in model_feature_lookups with matched key from inference_data_df
training_set = fs.create_training_set(inference_data_df, model_feature_lookups, label="quality", exclude_columns="wine_id")
training_pd = training_set.load_df().toPandas()
# Create train and test datasets
X = training_pd.drop("quality", axis=1)
y = training_pd["quality"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test, training_set
X_train, X_test, y_train, y_test, training_set = load_data(table_name, "wine_id")
X_train.head()
透過 indicated key 來找到 feature table 中的資料,並轉換成 training dataset。
def train_model(X_train, X_test, y_train, y_test, training_set, fs):
## fit and log model
with mlflow.start_run() as run:
rf = RandomForestRegressor(max_depth=3, n_estimators=20, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
mlflow.log_metric("test_mse", mean_squared_error(y_test, y_pred))
mlflow.log_metric("test_r2_score", r2_score(y_test, y_pred))
fs.log_model(
model=rf,
artifact_path="feature-store-model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="wine_model",
)
train_model(X_train, X_test, y_train, y_test, training_set, fs)
透過 score_batch 來 apply 已經 packaged feature store model。然後透過指定 primary key wine_id ,其他 feature 會自動從 feature store 取得。
## For simplicity, this example uses inference_data_df as input data for prediction
batch_input_df = inference_data_df.drop("quality") # Drop the label column
predictions_df = fs.score_batch(f"models:/wine_model/latest", batch_input_df)
display(predictions_df["wine_id","prediction"])
Reference:


 iThome鐵人賽
iThome鐵人賽