Paper link | Note link | Code link | ICLR 2024
這項研究使用背誦相關段落來解決知識密集型任務。
然而,我認為在「基於段落提示的多樣化背誦」部分,他們仍然依賴外部資料庫,如維基百科,來檢索知識(提示),這有助於通過提供更好的上下文和準確性來提高性能。
與大多數檢索方法在生成輸出之前嘗試檢索相關文檔不同,本研究「RECITation-augmented gEneration (RECITE)」從LLM自身的記憶中取樣一個或多個相關段落並背誦它們。

像我們之前討論的工作一樣,最近的大型語言模型依賴外部資料庫並使用檢索增強來解決知識密集型任務。
本研究探索了另一種方法:少量示例提示(few-shot prompting)。
在特定任務的自然語言處理(NLP)中,少量示例提示可以幫助大型語言模型(LLMs)表現得更好。
這篇論文的目標是模仿人類在回答知識密集型問題之前背誦相關事實知識的能力,以實現更準確的答案。
這種方法有兩個組件:
而他們如何實現這個方法?
他們通過以下步驟來實現這種方法:
提示設計:他們將背誦的段落附加在原始問題-答案示例的開頭,形成一個單一的提示,然後生成最終的答案。
多路徑解碼技術:由於事實知識可能出現在多個地方,他們使用多路徑解碼技術。對於任意問題,他們使用 top-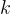 采樣獨立生成幾個背誦,然後根據這些背誦貪婪地解碼問題的答案。
采樣獨立生成幾個背誦,然後根據這些背誦貪婪地解碼問題的答案。
選擇最佳答案:通過對生成的答案進行多數投票來選擇最佳答案。
此外,他們將這種方法應用於多跳問題(multi-hop questions),通過使用 top- 采樣生成多個背誦,然後進行多數投票來確定最終答案。
在這一部分,他們的目標是讓證據背誦模塊達到以下兩個目的:
他們為每個段落找到獨特的提示,通過將段落的章節標題和段落內的順序進行拼接來實現。
這些段落的來源是結構良好的文本知識庫,如維基百科。
受到 多段檢索的問題回答 啟發,本研究使用聚合的多樣化背誦作為單一上下文,並通過少量示例問題-答案對來生成答案。

在訓練過程中,他們進行了額外的微調階段,以使大型語言模型(LLMs)學習從問題到段落提示,進而到完整段落的映射,僅通過少量示例提示。

訓練細節:
本研究在三個不同的問題回答資料集上進行實驗:
以下是不同資料集上的性能比較:

本研究還比較了 PaLM-62B 在 Natural Questions (NQ) 資料集上的不同提示策略的性能:


