一種深度學習模型,最初被設計 自然語言處理 (Natural Language Processing, NLP) 任務,例如:機器翻譯、文本摘要、問答系統。與傳統循環 神經網絡 (Recurrent Neural Network, RNN) 和 卷積神經網絡 (Convolutional Neural Network, CNN)。Transformer模型在處理序列數據時表現更強大的能力。
Encoder:負責將輸入序列編碼成包含語義信息隱含狀態Decoder:負責根據 Encoder 輸出生成目標序列Multi-Head Attention:自注意力機制核心,允許模型從不同表示空間中學習到相關信息Positional Encoding:由於 Transformer 沒有 RNN 遞歸結構,因此需要加入位置編碼來提供序列中每個位置的信息Feed Forward Neural Network:對每個位置的注意力輸出進行非線性變換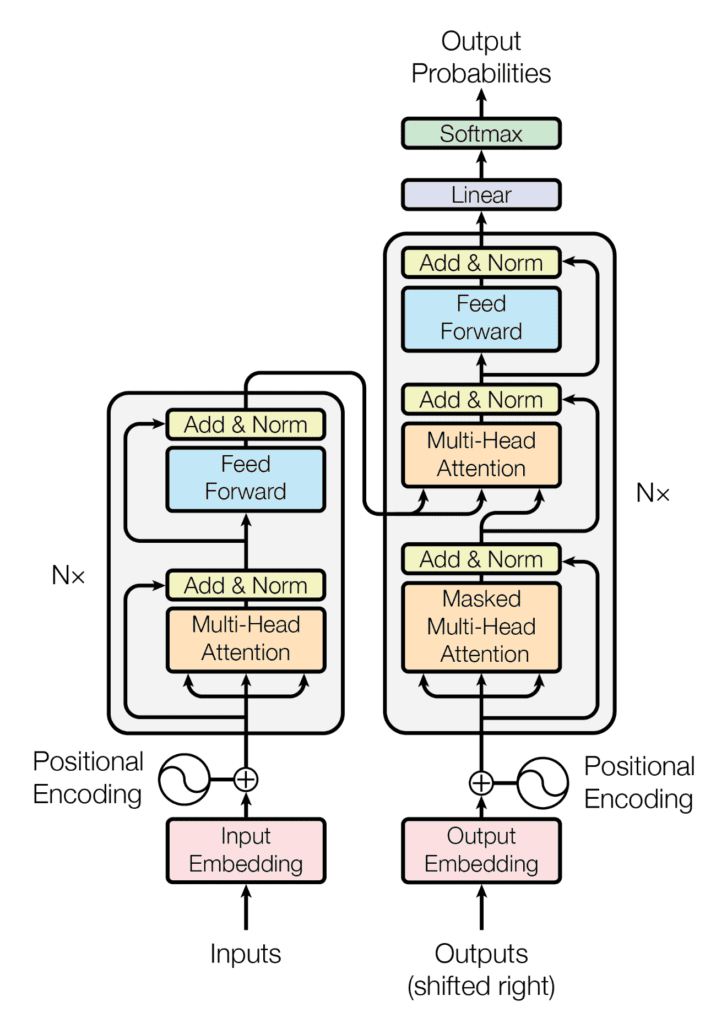
自注意力機制 (Self-Attention Mechanism):Transformer模型核心概念,允許模型在處理序列數據時,通過計算每個詞語與其他所有詞語之間的關聯性,來確定每個詞語在整個序列中重要性編碼器 (Encoder):負責將輸入序列映射到一個高維空間,模型能夠更好地捕捉序列中語義和語法信息解碼器 (Decoder):負責根據編碼器輸出生成目標序列位置編碼 (Positional Encoding):由於 Transformer 模型不具有RNN順序處理能力,因此需要引入位置編碼來提供序列中每個詞語位置信息Scaled Dot-Product Attention
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
Q |
查詢向量 (Query vector) |
|---|---|
K |
鍵向量(Key vector) |
V |
值向量(Value vector) |
d_k |
查詢向量維度 |
softmax |
計算注意力權重 |
Multi-Head Attention
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O
h |
頭的數量 |
|---|---|
W^O |
線性變換矩陣 |
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
# ... (多頭注意力機制實現)
class PositionwiseFeedForward(nn.Module):
# ... (位置前饋網路實現)
class EncoderLayer(nn.Module):
# ... (編碼器層實現)
class DecoderLayer(nn.Module):
# ... (解碼器層實現)
class Transformer(nn.Module):
# ... (整個Transformer模型實現)
import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k):
super().__init__()
self.d_k = d_k
def forward(self, q, k, v):
attn_logits = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float))
attention = nn.Softmax(dim=-1)(attn_logits)
values = torch.matmul(attention, v)
return values
import torch
import torch.nn as nn
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, dim_feedforward, dropout=0.1):
super().__init__()
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)
self.transformer_encoder = nn.TransformerEncoder(en
coder_layer, num_encoder_layers)
def forward(self, src):
src = self.transformer_encoder(src)
return srcTransformer 模型的程式碼
import torch
import torch.nn as nn
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, dim_feedforward, dropout=0.1):
super().__init__()
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)
self.transformer_encoder = nn.TransformerEncoder(en
coder_layer, num_encoder_layers)
def forward(self, src):
src = self.transformer_encoder(src)
return src
機器翻譯:Google Translate文本摘要:自動生成文章摘要問答系統:回答用戶提出問題,例如:ChatGPT文本生成:生成各種形式的文本,例如:詩歌、程式碼Transformer模型是深度學習領域一項重要突破,為自然語言處理帶來新的可能性。通過深入理解Transformer模型的原理和應用,可以更好地利用這一強大工具,解決各種NLP任務
資料來源:何謂 Transformer 模型?
Transformer模型

