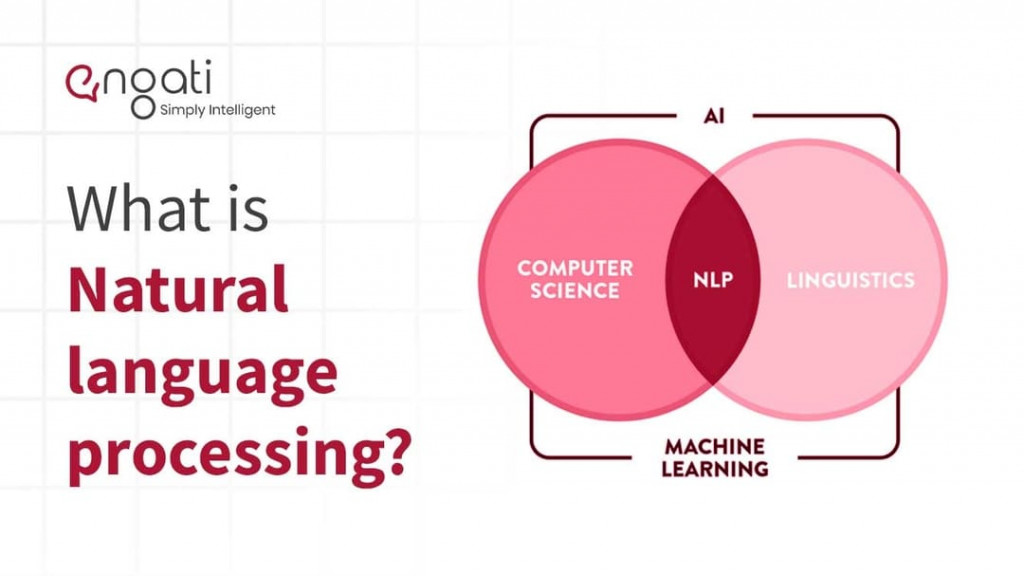
圖片來源:Natural Language Processing
簡稱 NLP,是人工智慧一個分支,研究如何讓電腦理解和處理人類語言,使用機器學習技術來建立語言模型。語言模型是一種統計模型,可以描述語言結構和規律。通過訓練語言模型,可以學習如何理解和生成人類語言。
數據層 |
存儲NLP所需數據,包括文本、語音、詞典 |
|---|---|
預處理層 |
對數據進行預處理,例如:分詞、去噪、句法分析 |
特徵提取層 |
從數據中提取特徵,例如:詞向量、句向量 |
模型層 |
使用機器學習算法訓練模型,例如: RNN、CNN、Transformer |
應用層 |
將模型實際應用,例如:機器翻譯、語音識別、聊天機器人 |
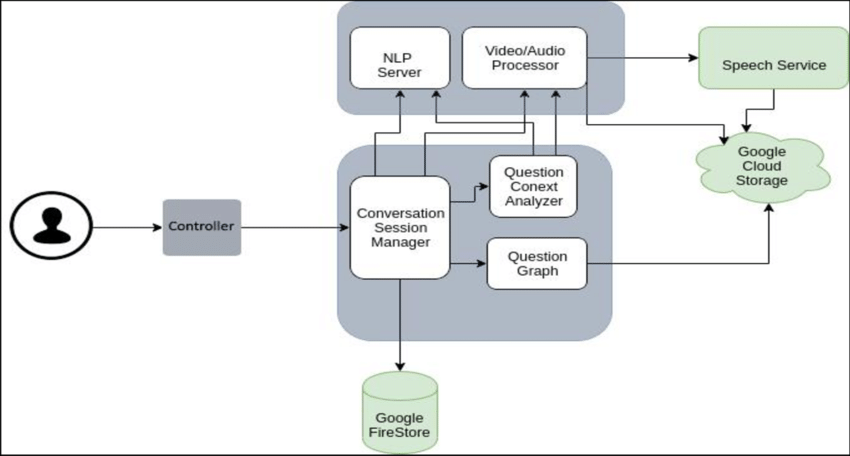
圖片來源:(https://www.researchgate.net/figure/Google-NLP-High-Level-Architecture-Diagram-12_fig1_346007397)
搜尋引擎:幫助我們更精準地找到想要資訊機器翻譯:突破語言障礙,實現跨語言交流語音助手:可以通過語音與設備進行互動聊天機器人:提供客戶服務、情感陪伴等功能文本摘要:自動生成文章摘要,提高閱讀效率情感分析:分析文本的情感傾向,應用於市場調研、輿情監測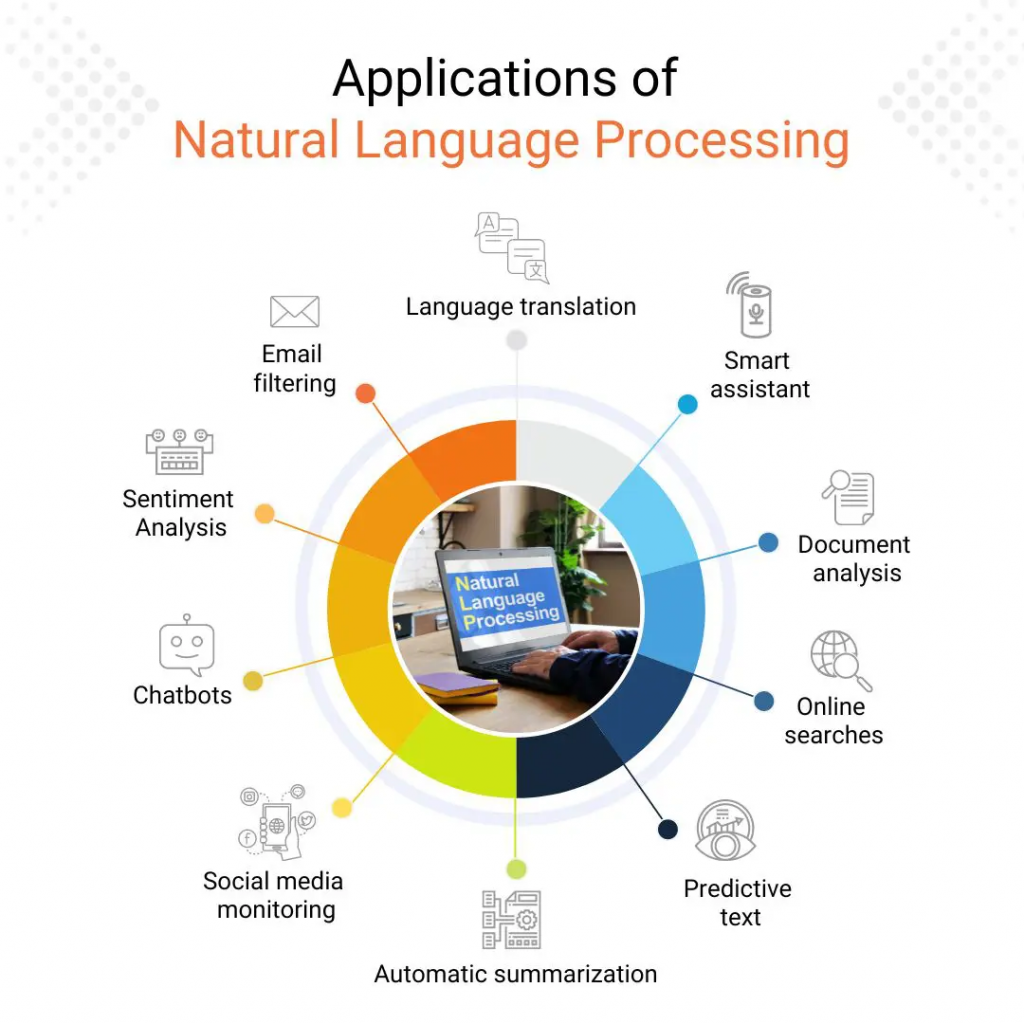
圖片來源:Applications of Natural Language Processing
文本預處理:將原始文本轉換為電腦可處理的形式,包括分詞、去除停用詞、詞性標註特徵提取:從文本中提取有意義的特徵,例如:詞頻、TF-IDF、詞向量模型訓練:使用機器學習算法,根據訓練資料訓練模型,讓模型學會如何理解和生成語言模型評估:評估模型的性能,看模型是否能準確地完成任務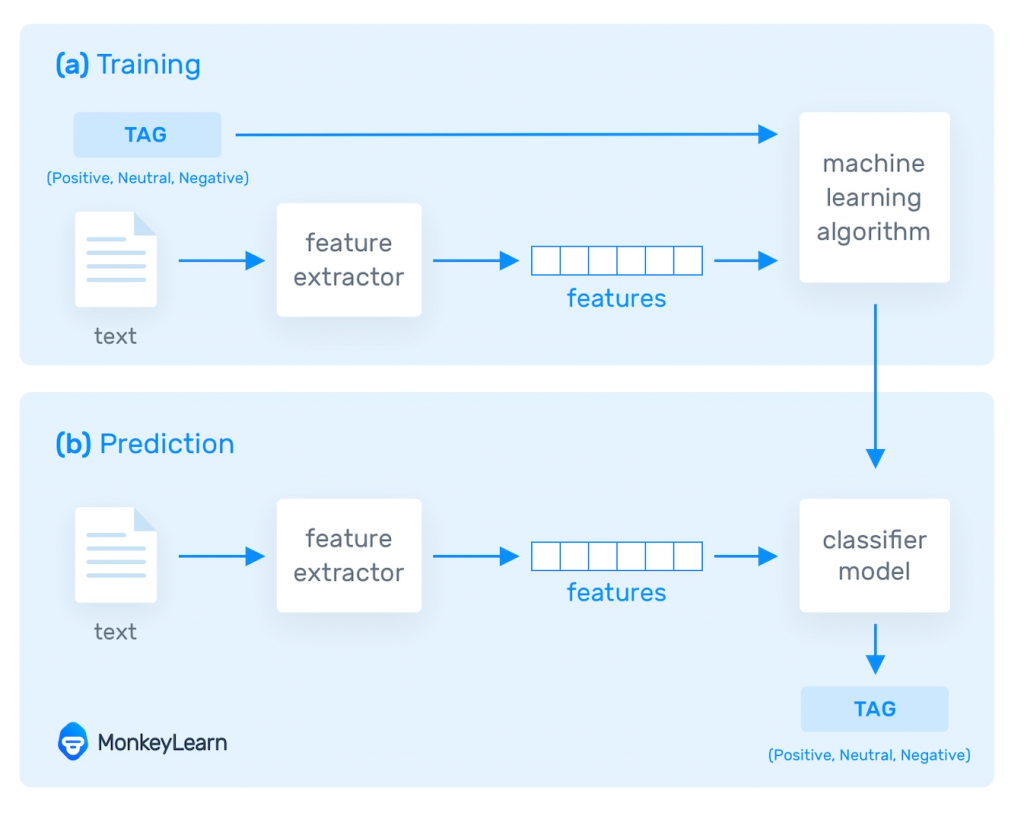
圖片來源:Natural Language Processing
詞彙分析:將文本分割成單詞,並標註詞性語法分析:分析句子語法結構,理解詞與詞之間關係語義分析:理解文本深層含義,包括情感、意圖、實體統計方法:基於概率統計的方法,例如:N-gram模型、隱馬爾可夫模型(HMM)
深度學習:深度學習模型在NLP領域取得巨大成功,利用深度學習模型,例如:循環神經網路(RNN)、長短期記憶網路(LSTM)、Transformer
機器學習:利用大量訓練資料,讓電腦學習語言模型,提高NLP準確性。也使用機器學習算法,例如:支持向量機(SVM)、隨機森林、神經網路
預訓練模型: 預訓練模型(BERT、GPT-3) 能夠在各種NLP任務上取得SOTA效果多模態學習: 將文本與圖像、聲音等其他模態的資料結合起來,實現更複雜任務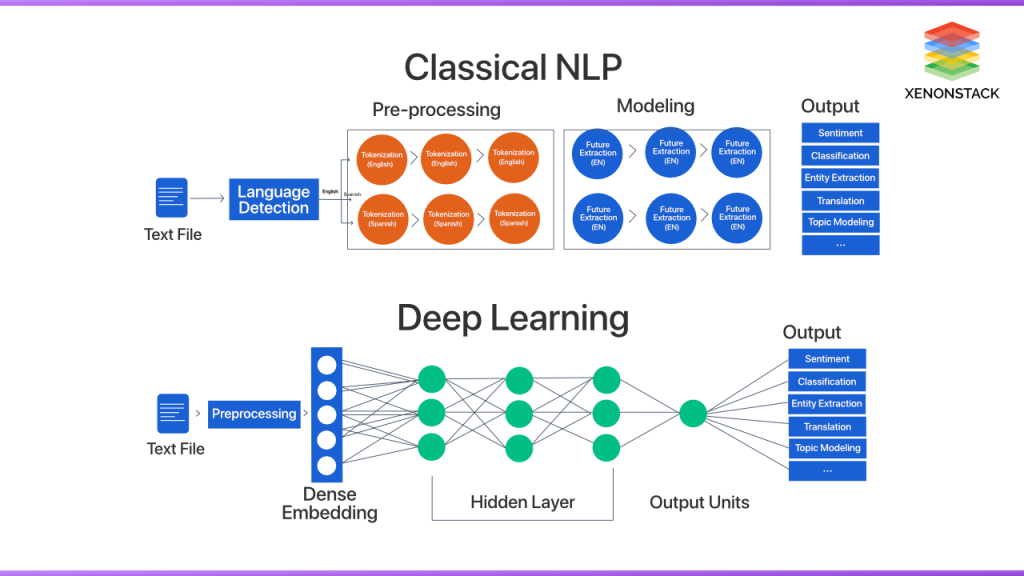
更強大語言理解能力:未來NLP模型將能夠更深入地理解人類語言,甚至具備一定的推理能力更廣泛的應用場景:NLP將在更多的領域得到應用,例如:醫療、法律、教育人機共存:NLP將促進人與機器之間的更自然、更深入的互動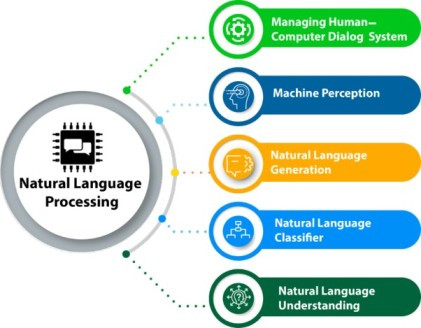
P(y | x) = \prod_{t=1}^T P(y_t | x, y_{t-1})P(w | x) = \argmax_w P(x | w) P(w)P(r | u) = \prod_{t=1}^T P(r_t | u, r_{t-1})
機器翻譯import tensorflow as tf
def seq2seq(encoder_inputs, decoder_inputs, target_outputs):
# 編碼器
encoder = tf.keras.layers.GRU(128)
encoder_outputs, encoder_states = encoder(encoder_inputs)
# 解碼器
decoder = tf.keras.layers.GRU(128)
decoder_outputs, _ = decoder(decoder_inputs, initial_state=encoder_states)
# 輸出層
output_layer = tf.keras.layers.Dense(len(target_outputs))
outputs = output_layer(decoder_outputs)
return outputs
# 訓練
model = seq2seq(encoder_inputs, decoder_inputs, target_outputs)
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit(x=[encoder_inputs, decoder_inputs], y=target_outputs, epochs=10)
# 使用
outputs = model.predict(x=[encoder_inputs, decoder_inputs])
語音識別import speech_recognition as sr
# 建立語音識別器
r = sr.Recognizer()
# 錄音
with sr.Microphone() as source:
audio = r.listen(source)
# 識別
text = r.recognize_google(audio)
print(text)
聊天機器人from rasa.core.agent import Agent
# 建立聊天機器人
agent = Agent.load('models/dialogue')
# 對話
while True:
text = input('你:')
response = agent.predict(text)
print('機器人:', response)
統計語言模型import nltk
# 訓練一個 n-gram 語言模型
n = 3
model = nltk.ngram_language_model(train_data, n)
# 使用語言模型生成句子
sentence = model.generate()
神經網路語言模型import tensorflow as tf
# 定義一個 RNN 語言模型
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(input_dim, output_dim),
tf.keras.layers.LSTM(hidden_dim),
tf.keras.layers.Dense(output_dim)
])
# 訓練語言模型
model.fit(train_data, epochs=10)
# 使用語言模型生成句子
sentence = model.predict(start_token)
Transformer模型import tensorflow as tf
# 定義一個 Transformer 模型
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(input_dim, output_dim),
tf.keras.layers.Transformer(num_layers=6, d_model=512, num_heads=8),
tf.keras.layers.Dense(output_dim)
])
# 訓練語言模型
model.fit(train_data, epochs=10)
# 使用語言模型生成句子
sentence = model.predict(start_token)

