上一篇文章了解虛擬環境的重要性,還有將這些工具給準備好了!今天就要開始進行簡單的程式實戰,搭配 Poetry 虛擬環境來管理 Python 環境。
這個 transformers 是 Hugging Face 開發的 Python 套件而非 NLP 的 transformer,有興趣了解 transformer 模型架構的可以點 連結 參考。我自己是覺得如果要學習生成式 AI,就不能不知道這個套件。因為每個模型的架構、參數載入方式、擅長的領域都不相同,光是進行預訓練模型的更換可能就會花費不少時間。但是透過 Transformers 這個套件,能夠將轉換成本降到最低! 使用這套框架能夠直接對多種模型進行調用,只需要了解此框架的機制,即可快速套用到 Hugging Face 的各種模型!
首先我們要來安裝必要的套件,除了 transformers 之外,Pytorch 也要裝,雖然 transformers 不依賴 Pytorch,但是在使用 Model 等的東東是需要 Pytorch 才可以跑起來。根據我們 上一篇文章 建立一個 Poetry 環境並開啟,然後我們就來安裝我們需要的套件。可以看到 transformers 有很多的依賴項。

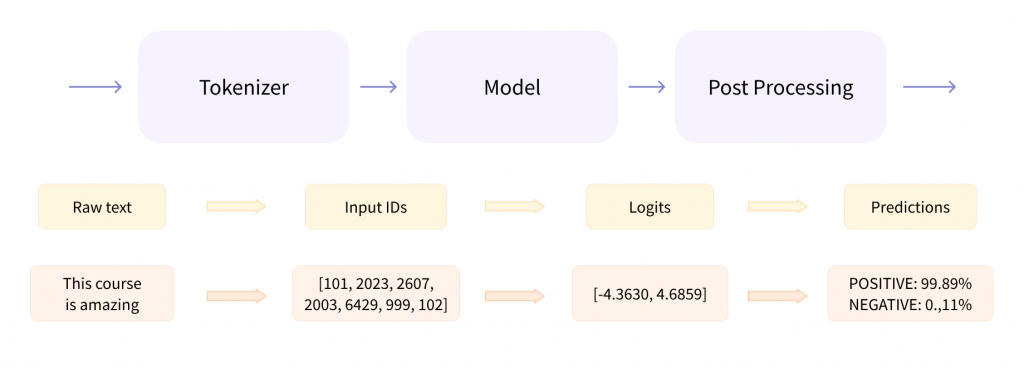
Hugging Face 有一個很強大的函數是 Pipeline,如上圖,他將 Tokenizer、Model、Postprocessing 包在一起,透過很簡單的方式就可以實現特定的任務。
# 匯入套件
from transformers import pipeline
# 指定任務(情感分析)、指定GPU(Mac:mps, Nvidia:cuda)
classifier = pipeline(task = "sentiment-analysis", device = "mps")
# Run Pipeline
res = classifier("This course is amazing!")
# 看結果
print (res)

# 匯入套件
from transformers import pipeline
# 指定任務(語句分類)、指定GPU(Mac:mps, Nvidia:cuda)
classifier = pipeline(task = "zero-shot-classification", device = "mps")
# Run Pipeline
res = classifier(
"The U.S. men's basketball team won the gold medal at the 2024 Paris Olympics.",
candidate_labels=["sport", "education", "financial"])
# 看結果
print (res)

執行程式後可以看到分類的結果,也有給分數。那 Pipeline 除了以上兩個之外,還有很多 NLP 的任務可以選擇,可以參考 Hugging Face 的 Pipeline。那接下來就看一下 Pipeline 背後的 Tokenizer 和 Model,可以看到前面有指定任務但沒有指定模型,所以有提示詞顯示他這個任務預設是使用什麼模型,那所以就來拆開 Pipeline 看看。
先說明一下 Tokenizer 在幹嘛,簡單來說就是將句子、圖片等等轉換成模型可以讀懂的內容,以句子來說的話就是做分詞(斷詞)的動作,那這些內容基本上會是以一個向量 (array) 的型態呈現。
# 匯入套件
from transformers import AutoTokenizer
# 載入模型
checkpoint = "facebook/bart-large-mnli"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 測試句子
sequence = "Using a Transformer network is simple."
# 1.轉換成給模型讀的樣子,包含:input_ids, attention_mask
res = tokenizer(sequence)
print(res)
# 2.分詞的函式
tokens = tokenizer.tokenize(sequence)
print(tokens)
# 3.詞轉向量的函式
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
# 4.將向量轉換成原本的句子
decoded_string = tokenizer.decode(ids)
print(decoded_string)

程式碼結果探討 🧐:
0 和 2 代表開頭和結尾,這個是 bart 模型的 tokens 型態。每個模型的這個型態都不一樣,比如說 bert 模型的開頭和結尾分別是 101 和 102。input_ids 一致,他是一個 binary 的 list。0 是代表對應的那筆 tokens_id 可以被忽略,1 反之。Using 對應的 id 是 36949。每一個 tokens 都有一個對應的 id。了解 Tokenizer 在幹嘛之後,要來把這些東西跟 Model 做結合,那會以 Pytorch 實戰。其實就是將 Tokenizer 的結果給 Model,那 Model 會根據任務回傳結果。
# 匯入套件
import torch
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 測試句子&分類
sequence = "The U.S. men's basketball team won the gold medal at the 2024 Paris Olympics."
labels = ["sport", "global", "education", "financial"]
# 使用 Pipeline 進行 zero-shot classification
classifier = pipeline(task = "zero-shot-classification", device = "mps")
result = classifier(sequence, labels, multi_label=True)
print("Pipeline Result: ", result)
# 載入模型
device = "mps"
checkpoint = "facebook/bart-large-mnli"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
model.to(device)
# 將分類標籤一一代入
for label in labels:
hypothesis = f'This example is {label}.'
# 1.將 sequence 和 hypothesis 轉換成 tokens_ids
x = tokenizer.encode(sequence, hypothesis, return_tensors='pt', truncation_strategy='only_first').to(device)
# 2.第 0 個元素是 logits
logits = model(x)[0]
# 3.MNLI 任務會回傳三個值,分別是 entailment, contradiction, neutral,其中我們要移除 neutral 這欄
entail_contradiction_logits = logits[:,[0,2]]
# 透過 softmax 函數將值計算成 0~1 的數
probs = entail_contradiction_logits.softmax(dim=1)
# 位置 0 是 False 的機率,位置 1 是 True 的機率
prob_label_is_true = probs[:,1]
print(f"{label} scores: ", prob_label_is_true)

程式碼結果探討 🧐:
先講一下 zero-shot classification 這個分類任務是 MNLI (Multi-Genre Natural Language Inference Corpus),就是給定一個句子和假設來預測這個假設正確和錯誤的機率。所以如果要從 Pipeline 函式中使用的話,要設定 multi_label=True。
可以看到與 Pipeline 的結果是一模一樣的,模型可以參考 facebook/bart-large-mnli。
前面都偏向是 NLP 任務,用 NLP 的任務比較好懂 Pipeline、Tokenizer、Model 這些東西在幹嘛,那接下來就將前面學到的部分套用在文本生成,Pipeline 的部分是一樣的,只要任務指定為 text-generation 就好,那我會以我自己 【Day 02】生成式 AI 入門指南 文章中的範例程式碼來分析,這是 TAME 他們 Hugging Face 上的 Code,其實 Hugging Face 的模型幾乎都有寫使用的方式和簡單的例子。(這個模型因為需要比較大的 GPU 容量,所以在 Colab 上執行)
# 匯入套件
import torch
from transformers import pipeline, StoppingCriteria
# 1. Define a custom stopping criteria class
class EosListStoppingCriteria(StoppingCriteria):
def __init__(self, eos_sequence=[128256]):
self.eos_sequence = eos_sequence
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
last_ids = input_ids[:, -len(self.eos_sequence):].tolist()
return self.eos_sequence in last_ids
# 2. Initialize the model with automatic device mapping
llm = pipeline("text-generation", model="yentinglin/Llama-3-Taiwan-8B-Instruct", device_map="auto", token="your hugging face token")
tokenizer = llm.tokenizer
# 3. use the chat template
chat = [
{"role": "system", "content": "你是一位道地的台灣人,了解台灣的社會文化和俚語。"},
{"role": "user", "content": "台灣8+9是什麼?"}
]
flatten_chat_for_generation = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 4. Generate a response using the custom stopping criteria
output = llm(flatten_chat_for_generation, return_full_text=False, max_new_tokens=128, top_p=0.9, temperature=0.7, stopping_criteria=[EosListStoppingCriteria([tokenizer.eos_token_id])])
print(output[0]['generated_text'])
程式碼結果探討 🧐:
convert_tokens_to_ids 來找出句號 ("。") 的 id 是多少,並將這個 id 加入 eos_sequence 就可以讓模型在自定義的斷點停止生成。但我自己在試的時候,中文的句號往往沒有對應的 id,所以如果想嘗試使用英文會是較好的選擇。text-generation 文本生成。指定模型為 yentinglin/Llama-3-Taiwan-8B-Instruct。device_map="auto" 就是會自動判斷有沒有 GPU,沒有的話就 CPU。最後有些 Model 會需要輸入 Hugging Face 帳號的 token 才可以使用。apply_chat_template,tokenize 設定 False 是因為沒有要將其轉換成 tokens_id,下圖看出 True 跟 False 的差異。如果 role 有設定 system 的話,add_generation_prompt 就要設定為 True,反之。
return_full_text 如果設定為 True,那就是連前面 chat_template 的部分都會顯示出來,False 的話只會產出文本生成的結果。max_new_tokens 代表模型輸出的 tokens 數上限。top_p 和 temperature 後續會在帶到這些比較細節的參數,最後的 stopping_criteria 放一個有斷點和沒斷點的範例如下。可以看到我設定遇到 "." 就停止生成,模型回傳的結果只有一句話,若沒設斷點可以看到模型生成的內容就會很長。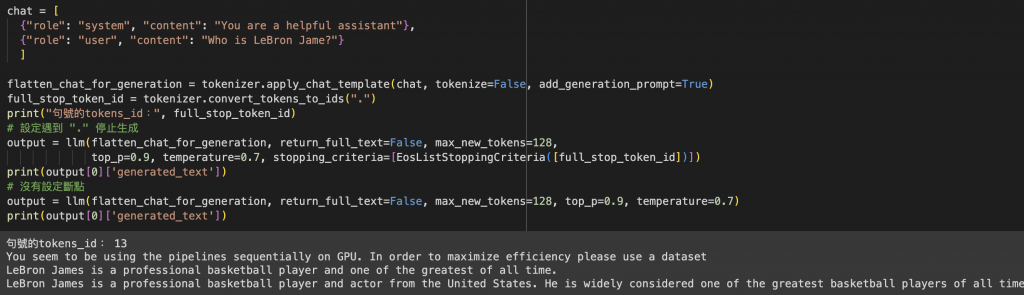
今天實作了 Hugging Face 文本生成不能不知道的部分,最後也透過文本生成的實戰將 Pipeline、Tokenizer、Model 都納入應用。知道怎麼使用 system_prompt 或是使用聊天模板,甚至是設置中斷點,讓模型回覆的內容不至於過於冗長。
今天跟女朋友去喜來登飯店的十二廚吃情人節大餐,會今天才吃是因為台北的假日真的是到哪都是人 🫠。必須說十二廚是相當的夠水準,前菜、海鮮、熟食、啤酒飲料、甜點一應俱全,真的很讚,超級推推!


 iThome鐵人賽
iThome鐵人賽