是一種機器學習方法,介於 監督式學習(Supervised learning) 和 非監督式學習(Unsupervised learning) 之間。在監督式學習中,所有訓練資料都已標記有正確的答案。在非監督式學習中,所有訓練資料都沒有標記。在半監督式學習中,部分訓練資料已標記,部分訓練資料沒有標記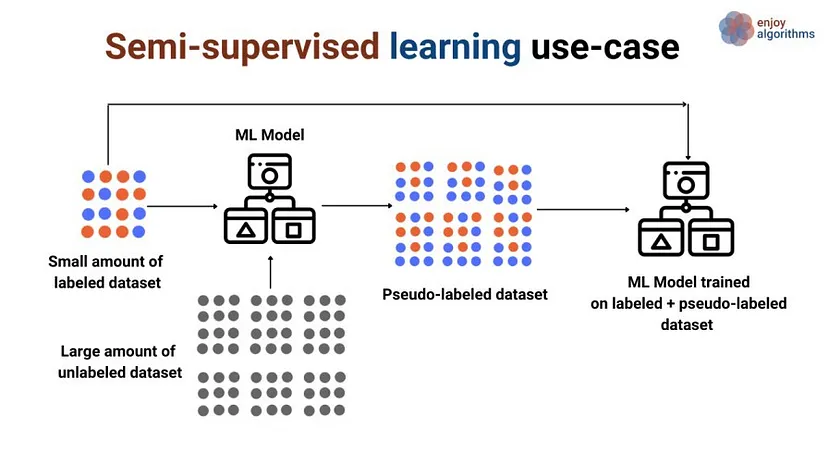
圖片來源:AGentle Introduction to Semi Supervised Learning
自訓練 (Self-training)
生成模型 (Generative Models)
半監督支持向量機 (Semi-Supervised Support Vector Machine)
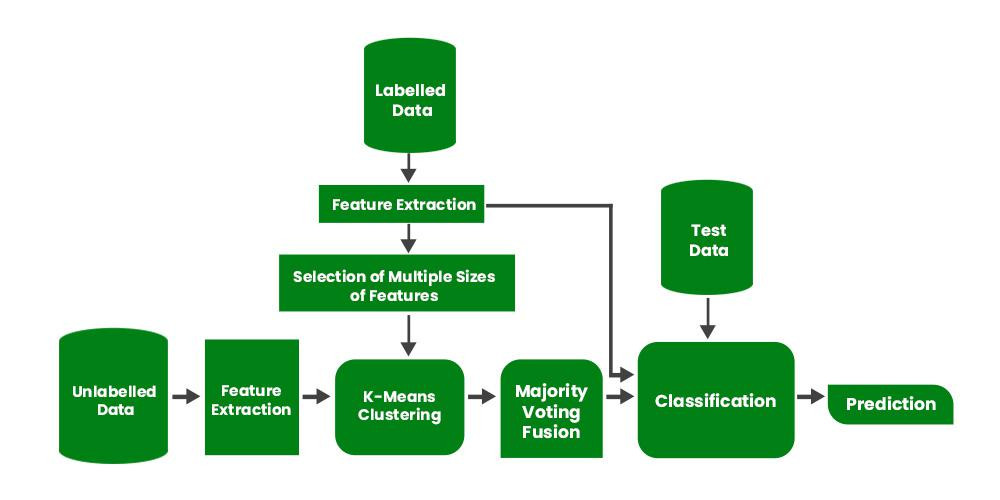
共訓練(Co-training)
期望最大化(Expectation-maximization,EM)
圖像識別:使用未標記圖像來提高圖像識別準確率自然語言處理:使用未標記文本來提高機器翻譯和文本分類準確率語音識別:使用未標記語音來提高語音識別準確率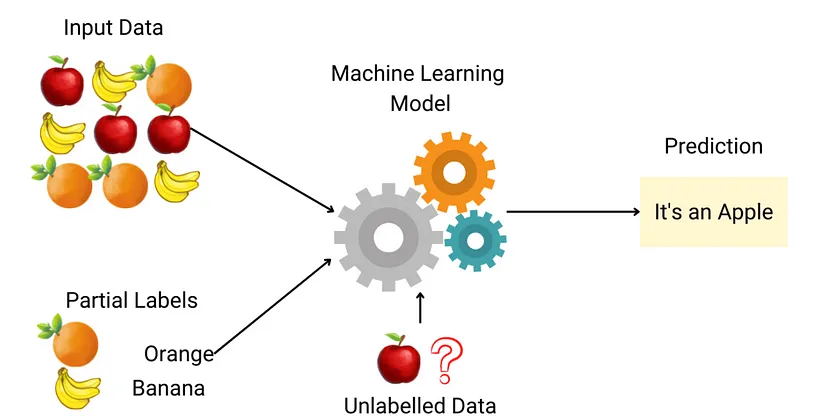
自訓練假設有一個分類問題,使用softmax函數作為分類器
初始模型p(y|x; θ) = softmax(θ^T x)
θ |
模型參數 |
|---|---|
x |
輸入樣本 |
y |
預測類別 |
自訓練過程from sklearn.semi_supervised import LabelPropagation
import numpy as np
# 生成隨機數據
X = np.random.rand(100, 2)
y = np.array([0, 0, 1, 1, -1, -1, -1, -1, -1, -1]) # -1表示未標籤數據
# 創建LabelPropagation模型
label_prop_model = LabelPropagation()
# 訓練模型
label_prop_model.fit(X, y)
# 預測所有數據點的標籤
y_pred = label_prop_model.predict(X)
半監督式學習是一種具有廣泛潛力的機器學習方法。隨著研究的深入,半監督式學習理論和方法將會得到進一步的發展,並在更多的領域得到應用

