BM25 可以說是 TF-IDF 的進階版,BM 是 Best Matching 的縮寫,25 則是修改的版本,由於它在檢索上的表現非常出色而被廣泛使用。
這個是它的完整公式,其中 D 代表文章,Q 代表使用者輸入的提問:
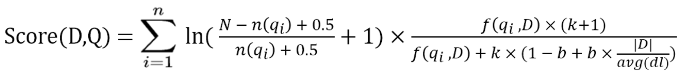
和原始的 TF-IDF 公式相比,BM25 已經有了很大的變化,而且看起來超複雜的,不過修改了這麼多還加了一堆參數肯定是有道理的,我們先從 TF 的部分開始討論吧。
先來看其中一部份:
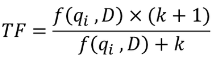
f 就是原本的 tf 值,K 是我們設定的參數,它的作用是決定 TF 的重要程度,我們可以從這張圖來觀察:
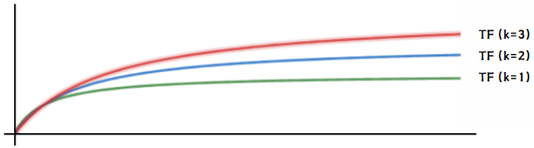
當 K 很小,曲線很快就平穩下來,表示 TF 被抑制程度較大,即便單詞出現的頻率比較高也沒有用。反之,如果 K 設定的比較大,代表在單詞出現的頻率比較高的時候,TF 仍然有影響力。
接下來,我們把 TF 公式變得更複雜一點:
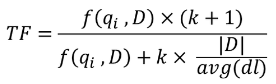
我們加入了兩個變數,|D| 代表這一篇文章的長度,avg(dl) 代表所有文章的平均長度,加入這兩個變數的原因是要抑制文章太長帶來的不公平現象。
舉例來說,如果文章的長度沒有上限的話,我們可以把所有的單詞都放進去或重複無數次,這樣一來,不管使用者輸入什麼關鍵字,因為都包含在裡面,所以提高了找到這篇文章的機會。
而這個漏洞對於搜尋引擎而言是需要避免的問題,不然會搜到一堆篇幅極長又沒什麼內容的文章,但是在加上這兩個變數之後,篇幅越長的文章會被賦予較小的權重,排名就會下降。
最後,我們再加入一個參數:
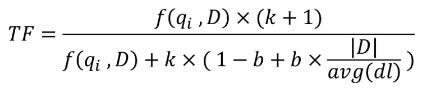
參數 b 的作用是動態調整 |D| / avgdl 的程度,當 b 等於 0 的時候,不對文章篇幅進行任何限制,當 b 等於 1 的時候,就和剛剛第二步的公式效果一樣了。
我們可以對 TF 的公式來做個整理:
我們來看看 IDF 修改後的公式長怎樣:
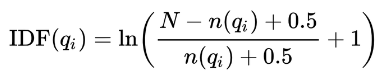
其中,N 代表所有的文檔總數,n 代表包含該單詞的文檔數。
我在讀這一段的時候並沒有找到明確的解釋說為什麼要這樣修改,不過我照著畫了曲線的對比圖:
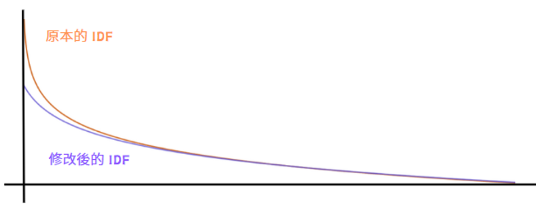
觀察這張圖可以發現,對新的公式而言,稀有單詞之間的 IDF 差距變小了。
以上就是對於 BM25 的介紹,不同版本的 Best Matching 公式調整的位置和權重也有所不同,有興趣的可以去查查看。
明天會介紹如何實作 BM25,並且實際用一個例子來試試看檢索起來的效果如何。
推薦文章
[译] Practical BM25 - Part 2: BM25算法和它的变量们 (farer.org)
白話圖解 - 什麼是 BM25 · YWC 科技筆記 (ywctech.net)


 iThome鐵人賽
iThome鐵人賽