使用另外一家 anthropic 的 API 又噴錢,感覺這一家燒錢的速度比OpenAI的API 還要快啊,我的天
另外這個也是langgraph教學中的一個例子,有興趣的可以去找找。
AlphaCodium 提出了一種運用控制流程進行程式碼生成的策略。
核心概念:迭代式地構建編碼問題的答案。.
AlphaCodium 會針對特定問題,在公開和 AI 生成的測試用例上迭代地測試並改進答案。
我們將使用LangGraph從頭開始實作其中一些概念::
! pip install -U langchain_community langchain-openai langchain-anthropic langchain langgraph bs4
!pip install anthropic
import getpass
import os
from langchain_openai import ChatOpenAI
from anthropic import Anthropic
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# 替換為你的LANGCHAIN_API_KEY
os.environ["LANGCHAIN_API_KEY"] = "l替換為你的LANGCHAIN_API_KEY"
os.environ["OPENAI_API_KEY"] = "替換為你的OPENAI_API_KEY"
os.environ["ANTHROPIC_API_KEY"] = "替換為你的ANTHROPIC_API_KEY"
以載入 LangChain Expression Language (LCEL) 文件當作例子。
from bs4 import BeautifulSoup as Soup
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
# LCEL docs
url = "https://python.langchain.com/v0.2/docs/concepts/#langchain-expression-language-lcel"
loader = RecursiveUrlLoader(
url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# 根據網址對列表進行排序,並提取其中的文本。
d_sorted = sorted(docs, key=lambda x: x.metadata["source"])
d_reversed = list(reversed(d_sorted))
concatenated_content = "\n\n\n --- \n\n\n".join(
[doc.page_content for doc in d_reversed]
)
嘗試使用 OpenAI 和 Claude3 並啟用函數調用功能。
使用 OpenAI 以及 Claude 創建 code_gen_chain 並在此處進行測試。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
### OpenAI
# Grader prompt
code_gen_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are a coding assistant with expertise in LCEL, LangChain expression language. \n
Here is a full set of LCEL documentation: \n ------- \n {context} \n ------- \n Answer the user
question based on the above provided documentation. Ensure any code you provide can be executed \n
with all required imports and variables defined. Structure your answer with a description of the code solution. \n
Then list the imports. And finally list the functioning code block. Here is the user question:""",
),
("placeholder", "{messages}"),
]
)
# Data model
class code(BaseModel):
"""Code output"""
prefix: str = Field(description="Description of the problem and approach")
imports: str = Field(description="Code block import statements")
code: str = Field(description="Code block not including import statements")
description = "Schema for code solutions to questions about LCEL."
expt_llm = "gpt-4-0125-preview"
llm = ChatOpenAI(temperature=0, model=expt_llm)
code_gen_chain = code_gen_prompt | llm.with_structured_output(code)
question = "How do I build a RAG chain in LCEL?"
# solution = code_gen_chain_oai.invoke({"context":concatenated_content,"messages":[("user",question)]})
from langchain_anthropic import ChatAnthropic
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
### Anthropic
# Prompt to enforce tool use
code_gen_prompt_claude = ChatPromptTemplate.from_messages(
[
(
"system",
"""<instructions> You are a coding assistant with expertise in LCEL, LangChain expression language. \n
Here is the LCEL documentation: \n ------- \n {context} \n ------- \n Answer the user question based on the \n
above provided documentation. Ensure any code you provide can be executed with all required imports and variables \n
defined. Structure your answer: 1) a prefix describing the code solution, 2) the imports, 3) the functioning code block. \n
Invoke the code tool to structure the output correctly. </instructions> \n Here is the user question:""",
),
("placeholder", "{messages}"),
]
)
# Data model
class code(BaseModel):
"""Code output"""
prefix: str = Field(description="Description of the problem and approach")
imports: str = Field(description="Code block import statements")
code: str = Field(description="Code block not including import statements")
description = "Schema for code solutions to questions about LCEL."
# LLM
#expt_llm = "claude-3-haiku-20240307"
expt_llm = "claude-3-opus-20240229"
llm = ChatAnthropic(
model=expt_llm,
default_headers={"anthropic-beta": "tools-2024-04-04"},
)
structured_llm_claude = llm.with_structured_output(code, include_raw=True)
# Optional: Check for errors in case tool use is flaky
def check_claude_output(tool_output):
"""Check for parse error or failure to call the tool"""
# Error with parsing
if tool_output["parsing_error"]:
# Report back output and parsing errors
print("Parsing error!")
raw_output = str(tool_output["raw"].content)
error = tool_output["parsing_error"]
raise ValueError(
f"Error parsing your output! Be sure to invoke the tool. Output: {raw_output}. \n Parse error: {error}"
)
# Tool was not invoked
elif not tool_output["parsed"]:
print("Failed to invoke tool!")
raise ValueError(
"You did not use the provided tool! Be sure to invoke the tool to structure the output."
)
return tool_output
# Chain with output check
code_chain_claude_raw = (
code_gen_prompt_claude | structured_llm_claude | check_claude_output
)
def insert_errors(inputs):
"""Insert errors for tool parsing in the messages"""
# Get errors
error = inputs["error"]
messages = inputs["messages"]
messages += [
(
"assistant",
f"Retry. You are required to fix the parsing errors: {error} \n\n You must invoke the provided tool.",
)
]
return {
"messages": messages,
"context": inputs["context"],
}
# This will be run as a fallback chain
fallback_chain = insert_errors | code_chain_claude_raw
N = 3 # Max re-tries
code_gen_chain_re_try = code_chain_claude_raw.with_fallbacks(
fallbacks=[fallback_chain] * N, exception_key="error"
)
def parse_output(solution):
"""When we add 'include_raw=True' to structured output,
it will return a dict w 'raw', 'parsed', 'parsing_error'."""
return solution["parsed"]
# Optional: With re-try to correct for failure to invoke tool
code_gen_chain = code_gen_chain_re_try | parse_output
# No re-try
code_gen_chain = code_gen_prompt_claude | structured_llm_claude | parse_output
# Test
question = "How do I build a RAG chain in LCEL?"
solution = code_gen_chain.invoke(
{"context": concatenated_content, "messages": [("user", question)]}
)
solution
code(prefix="To build a RAG (Retrieval Augmented Generation) chain in LangChain Expression Language (LCEL), you can compose a prompt template, retriever, and language model together. Here's an example of how you can build a basic RAG chain in LCEL:", imports='from langchain_core import llms\nfrom langchain_core.chains.retrieval_qa import vec_prompt\nfrom langchain.retrievers.multi_query import MultiQueryRetriever\nfrom langchain.retrievers import VectorStoreRetriever\nfrom langchain_openai import ChatOpenAI', code='# Load retriever\nretriever1 = VectorStoreRetriever.from_existing_index(...)\nretriever2 = VectorStoreRetriever.from_existing_index(...)\nretriever = MultiQueryRetriever([retriever1, retriever2])\n\n# Define prompt\nprompt = vec_prompt.PROMPT\n\n# Load LLM\nllm = ChatOpenAI()\n\n# Build RAG chain\nrag_chain = prompt | retriever | llm\n\n# Run RAG chain\nquestion = "What is the capital of France?"\nresult = rag_chain.invoke({"query": question})\nprint(result["result"])', description='Schema for code solutions to questions about LCEL.')
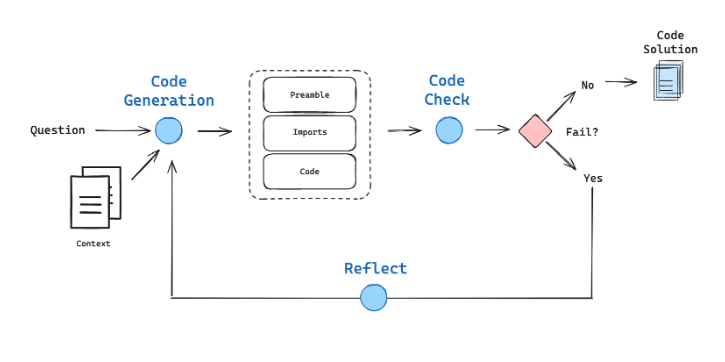
我們的狀態是一個字典,它將包含與程式碼生成相關的鍵(錯誤、問題、程式碼生成)。
from typing import List, TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
error : Binary flag for control flow to indicate whether test error was tripped
messages : With user question, error messages, reasoning
generation : Code solution
iterations : Number of tries
"""
error: str
messages: List
generation: str
iterations: int
我們的Graph展示了上圖所示的邏輯流程。
from langchain_core.pydantic_v1 import BaseModel, Field
### Parameter
# Max tries
max_iterations = 3
# Reflect
# flag = 'reflect'
flag = "do not reflect"
### Nodes
def generate(state: GraphState):
"""
Generate a code solution
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation
"""
print("---GENERATING CODE SOLUTION---")
# State
messages = state["messages"]
iterations = state["iterations"]
error = state["error"]
# We have been routed back to generation with an error
if error == "yes":
messages += [
(
"user",
"Now, try again. Invoke the code tool to structure the output with a prefix, imports, and code block:",
)
]
# Solution
code_solution = code_gen_chain.invoke(
{"context": concatenated_content, "messages": messages}
)
messages += [
(
"assistant",
f"{code_solution.prefix} \n Imports: {code_solution.imports} \n Code: {code_solution.code}",
)
]
# Increment
iterations = iterations + 1
return {"generation": code_solution, "messages": messages, "iterations": iterations}
def code_check(state: GraphState):
"""
Check code
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, error
"""
print("---CHECKING CODE---")
# State
messages = state["messages"]
code_solution = state["generation"]
iterations = state["iterations"]
# Get solution components
imports = code_solution.imports
code = code_solution.code
# Check imports
try:
exec(imports)
except Exception as e:
print("---CODE IMPORT CHECK: FAILED---")
error_message = [("user", f"Your solution failed the import test: {e}")]
messages += error_message
return {
"generation": code_solution,
"messages": messages,
"iterations": iterations,
"error": "yes",
}
# Check execution
try:
exec(imports + "\n" + code)
except Exception as e:
print("---CODE BLOCK CHECK: FAILED---")
error_message = [("user", f"Your solution failed the code execution test: {e}")]
messages += error_message
return {
"generation": code_solution,
"messages": messages,
"iterations": iterations,
"error": "yes",
}
# No errors
print("---NO CODE TEST FAILURES---")
return {
"generation": code_solution,
"messages": messages,
"iterations": iterations,
"error": "no",
}
def reflect(state: GraphState):
"""
Reflect on errors
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation
"""
print("---GENERATING CODE SOLUTION---")
# State
messages = state["messages"]
iterations = state["iterations"]
code_solution = state["generation"]
# Prompt reflection
# Add reflection
reflections = code_gen_chain.invoke(
{"context": concatenated_content, "messages": messages}
)
messages += [("assistant", f"Here are reflections on the error: {reflections}")]
return {"generation": code_solution, "messages": messages, "iterations": iterations}
### Edges
def decide_to_finish(state: GraphState):
"""
Determines whether to finish.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
error = state["error"]
iterations = state["iterations"]
if error == "no" or iterations == max_iterations:
print("---DECISION: FINISH---")
return "end"
else:
print("---DECISION: RE-TRY SOLUTION---")
if flag == "reflect":
return "reflect"
else:
return "generate"
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("generate", generate) # generation solution
workflow.add_node("check_code", code_check) # check code
workflow.add_node("reflect", reflect) # reflect
# Build graph
workflow.add_edge(START, "generate")
workflow.add_edge("generate", "check_code")
workflow.add_conditional_edges(
"check_code",
decide_to_finish,
{
"end": END,
"reflect": "reflect",
"generate": "generate",
},
)
workflow.add_edge("reflect", "generate")
app = workflow.compile()
question = "How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?"
app.invoke({"messages": [("user", question)], "iterations": 0})
---GENERATING CODE SOLUTION---
---CHECKING CODE---
Why was the cat sitting on the computer?
Because it wanted to keep an eye on the mouse!
---NO CODE TEST FAILURES---
---DECISION: FINISH---
{'error': 'no',
'messages': [('user',
'How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?'),
('assistant',
'To pass a string directly to a runnable and use it to construct the input for a prompt, you can use a PromptTemplate with the input variable in the template string. Then pass the resulting PromptValue to the runnable\'s .invoke() method. Here\'s how: \n Imports: from langchain_core.prompts import PromptTemplate\nfrom langchain_openai import ChatOpenAI \n Code: prompt_template = PromptTemplate.from_template("Tell me a {adjective} joke about {topic}")\n\nchat_model = ChatOpenAI()\n\nquery = "funny cats"\nprompt_value = prompt_template.invoke({"adjective": "funny", "topic": "cats"})\n\nai_message = chat_model.invoke(prompt_value)\nprint(ai_message.content)')],
'generation': code(prefix="To pass a string directly to a runnable and use it to construct the input for a prompt, you can use a PromptTemplate with the input variable in the template string. Then pass the resulting PromptValue to the runnable's .invoke() method. Here's how:", imports='from langchain_core.prompts import PromptTemplate\nfrom langchain_openai import ChatOpenAI', code='prompt_template = PromptTemplate.from_template("Tell me a {adjective} joke about {topic}")\n\nchat_model = ChatOpenAI()\n\nquery = "funny cats"\nprompt_value = prompt_template.invoke({"adjective": "funny", "topic": "cats"})\n\nai_message = chat_model.invoke(prompt_value)\nprint(ai_message.content)', description='Schema for code solutions to questions about LCEL.'),
'iterations': 1}
這裡 LCEL 問題數據集。
我已將其保存為 test-LCEL-code-gen。
您還可以在這裡 csv 檔案。
import langsmith
client = langsmith.Client()
# Clone the dataset to your tenant to use it
public_dataset = (
"https://smith.langchain.com/public/326674a6-62bd-462d-88ae-eea49d503f9d/d"
)
client.clone_public_dataset(public_dataset)
特定方向的評測
from langsmith.schemas import Example, Run
def check_import(run: Run, example: Example) -> dict:
imports = run.outputs.get("imports")
try:
exec(imports)
return {"key": "import_check", "score": 1}
except Exception:
return {"key": "import_check", "score": 0}
def check_execution(run: Run, example: Example) -> dict:
imports = run.outputs.get("imports")
code = run.outputs.get("code")
try:
exec(imports + "\n" + code)
return {"key": "code_execution_check", "score": 1}
except Exception:
return {"key": "code_execution_check", "score": 0}
LangGraph 跟 Context Stuffing的對比
def predict_base_case(example: dict):
"""Context stuffing"""
solution = code_gen_chain.invoke(
{"context": concatenated_content, "messages": [("user", example["question"])]}
)
solution_structured = code_gen_chain.invoke([("code", solution)])
return {"imports": solution_structured.imports, "code": solution_structured.code}
def predict_langgraph(example: dict):
"""LangGraph"""
graph = app.invoke({"messages": [("user", example["question"])], "iterations": 0})
solution = graph["generation"]
return {"imports": solution.imports, "code": solution.code}
from langsmith.evaluation import evaluate
import pandas as pd
# Evaluator
code_evalulator = [check_import, check_execution]
df = pd.read_csv('https://raw.githubusercontent.com/langchain-ai/lcel-teacher/main/eval/eval.csv')
# Dataset
dataset_name = "test-LCEL-code-gen"
dataset = client.upload_dataframe(
df=df,
name=dataset_name,
input_keys=["question"],
output_keys=[], # If no labeled outputs are present.
data_type="kv" # The default
)
# Run base case
experiment_results_ = evaluate(
predict_base_case,
data=dataset_name,
evaluators=code_evalulator,
experiment_prefix=f"test-without-langgraph-{expt_llm}",
max_concurrency=2,
metadata={
"llm": expt_llm,
},
)
# Run with langgraph
experiment_results = evaluate(
predict_langgraph,
data=dataset_name,
evaluators=code_evalulator,
experiment_prefix=f"test-with-langgraph-{expt_llm}-{flag}",
max_concurrency=2,
metadata={
"llm": expt_llm,
"feedback": flag,
},
)
https://smith.langchain.com/public/78a3d858-c811-4e46-91cb-0f10ef56260b/d
下面為實際運作的環境
感覺這邊的每個 function 也是 prompt 模板+llm 問答輸出+程式碼+多個迴圈(可設定)
類似自問自答或根據輸入不斷地調整,另外langchain 的 github 項目真的很多程式碼可以參考,包括教學。
這類很耗token的工作模式,我想可能要弄個本地的開源方案我才能承受得起,或者是直接使用別人家的軟體用。
教學:
基礎:
將外部資訊導入到 Agent 的運作中
5. 建立檢索增強生成 (RAG) 應用程式
6. 建立會話式 RAG 應用程式
7. 基於 SQL 資料建構問答系統
8. 建構查詢分析系統
9. 建立本地 RAG 應用程式
10. 透過圖形資料庫建立問答應用程式
11. 建構 PDF 攝取和問答系統
特定的任務或功能
12. 建構抽取資料的方法
13. 產生合成資料
14. 將文字用標籤分類
15. 總結文本
快速入門:
聊天機器人:
RAG:
4.自適應 RAG
5.使用本地的LLM進行自適應 RAG
6.自主檢索 RAG(Agentic RAG)
7.自修正 RAG(Corrective RAG)
8. 使用本地的LLM進行自修正 RAG
9.自我詢問RAG(Self-RAG)
10.使用本地的LLM自我詢問RAG(Self-RAG)
11.SQL Agent
Agent 架構:
評估與分析:
22. 基於代理的評估
23. 在LangSmith中的評估
實驗性項目:
24. 網路搜索Agent(STORM)
25. TNT-LLM
26. Web導航 Agent
27. 競賽中的程式設計
28. 複雜資料抽取

