
Paper link | Code link | EMNLP 2023
這項研究首次聯合探討了視覺語言預訓練模型(VLP)在視覺問答(VQA)任務中的壓縮和去偏差問題。
儘管視覺語言預訓練模型(VLPs)在視覺問答(VQA)任務上表現強勁,但它們面臨兩個問題:
本文探討了通過系統的訓練和壓縮管道來同時壓縮和去偏差VLPs 的可能性,旨在識別稀疏且穩健的子網路。
當視覺語言預訓練模型(VLPs)遇到分布與訓練集不同的分布外(OOD)測試數據集時,性能會顯著下降。
視覺問答(VQA)中的數據集偏差問題已被廣泛研究,許多去偏差方法已應用於傳統的小規模模型。
這些方法主要通過基於訓練樣本的偏差程度來正則化損失,以解決這一問題。
本研究以 LXMERT 為例。
LXMERT(Learning Cross-Modality Encoder Representations from Transformers)是一種學習視覺與語言連接的框架。
要被修剪的參數如下:
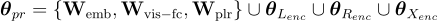
其中,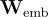 、
、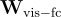 和
和 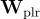 分別是嵌入層、視覺全連接層和池化層的權重。
分別是嵌入層、視覺全連接層和池化層的權重。
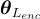 、
、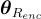 和
和 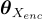 則是語言編碼器、對象關係編碼器和跨模態編碼器的參數。
則是語言編碼器、對象關係編碼器和跨模態編碼器的參數。
他們探索了兩種代表性的修剪技術:
此方法通過參數的絕對值來估計其重要性,移除那些被認為不太重要的參數。
這種方法通過優化二進制修剪掩碼( )來直接達到特定目標。
)來直接達到特定目標。
一個捕捉語言偏差的偏倚模型被用來評估訓練樣本的偏差程度。
主模型的訓練損失隨後根據這些偏差進行調整以抵消該偏差。
二元交叉熵(BCE)
計算主模型預測與每個真實標籤的軟目標分數之間的交叉熵。
Learned-Mixin +H(LMH)
在訓練過程中引入一個偏倚模型來學習並調整偏差。
RUBi
使用類似於 LMH 的策略來正則化主模型的機率,並使用標準交叉熵作為訓練損失。
LPF
測量偏差程度並相應地正則化主模型的損失。
目標是找到一個滿足目標稀疏度水平  並最大化 OOD 性能的子網路
並最大化 OOD 性能的子網路 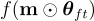 :
:
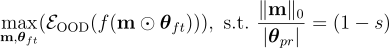
其中 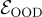 表示 OOD 評估,
表示 OOD 評估,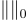 是
是 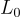 範數,
範數,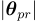 是
是 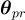 中的參數總數。
中的參數總數。
一個典型的訓練和壓縮管線包括三個階段:
階段 1:完整模型的微調
預訓練的 LXMERT 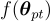 進行微調,使用損失函數
進行微調,使用損失函數 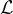 來生成
來生成 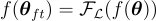 。
。
階段 2:模型壓縮
微調後的 LXMERT 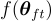 被壓縮,生成的子網路將為
被壓縮,生成的子網路將為 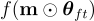 ,其中
,其中 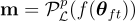 。
。
階段 3:進一步微調(可選)
子網路 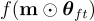 進一步使用損失函數
進一步使用損失函數 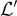 進行微調,結果將為
進行微調,結果將為 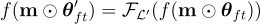 。
。
下面的圖顯示了從 BCE 微調的 LXMERT 子網路(左)和從 LMH 微調的 LXMERT 子網路(右)在 VQA-CP v2 上的結果。

下面的圖顯示了使用各種去偏差方法微調的 LXMERT 子網路在 VQA-CP v2 數據集上的結果。

