Paper link | Note link | Code link | NeurIPS 2023
這項研究展示了視覺指令調整的有效性。
他們引入了一個自動化的管道來生成語言-圖像指令跟隨數據,該數據用於訓練 LLaVA,一個能夠遵循人類意圖完成視覺任務的多模態模型。
LLaVA(大型語言與視覺助理)是一種端到端的多模態模型,旨在將視覺編碼器與大型語言模型(LLM)整合在一起。
這種結合使得模型能夠全面理解視覺和文本資訊。
大型語言模型(LLMs)已經顯示出語言可以作為通用介面來支援多用途助手,各種任務指令都以文本形式明確表示,從而指導神經網絡助手在任務之間進行切換。
當LLMs與多模態的視覺與語言指令相連接時,它們進一步擴展了這一能力,使助手能夠無縫地解釋和解決涉及視覺和文本資訊的任務。
目前,多模態指令跟隨數據的可用性仍然有限。
為了解決這個問題,這項研究利用 ChatGPT/GPT-4 來收集這類數據,並使用廣泛可用的圖像對數據集。
給定一張圖片 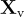 及其相關的標題
及其相關的標題 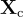 ,可以生成一組問題
,可以生成一組問題 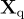 ,目的是指導助手描述圖像內容。
,目的是指導助手描述圖像內容。
將圖像-文本對轉換為指令跟隨格式的一種簡單方法如下:
人類: 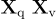 <STOP>
<STOP>
助手: 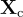 <STOP>
<STOP>
然而,這種方法在指令和回應中缺乏多樣性和深入的推理。
為了解決這一限制,這項研究利用 GPT-4 或 ChatGPT 等僅接受文本輸入的語言模型的能力,生成更為複雜的指令跟隨數據,涉及視覺內容。
下表提供了一個示例來說明指令跟隨數據的生成過程。

以下是網絡架構圖:
這個架構的主要目標是有效地利用預訓練的大型語言模型(LLM)和視覺模型的優勢,以實現更精確和全面的多模態任務處理。

他們使用Vicuna作為大型語言模型(LLM) 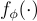 ,並使用預訓練的CLIP視覺編碼器ViT-L/14處理輸入圖像
,並使用預訓練的CLIP視覺編碼器ViT-L/14處理輸入圖像 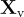 ,生成視覺特徵
,生成視覺特徵 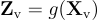 。
。
一個線性層和可訓練的投影矩陣 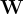 將這些特徵映射到詞嵌入空間,生成語言嵌入token
將這些特徵映射到詞嵌入空間,生成語言嵌入token 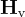 ,其維度與LLM的詞嵌入相匹配:
,其維度與LLM的詞嵌入相匹配:
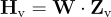
對於每個圖像 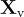 ,他們生成多輪對話數據
,他們生成多輪對話數據  ,其中
,其中 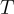 是總輪次。
是總輪次。
這些數據被組織成一個序列,所有答案作為助理的回應。
第 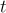 輪的指令
輪的指令 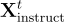 定義為:
定義為:
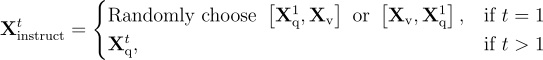
這樣生成了統一的多模態指令跟隨序列格式。
接著,他們對LLM進行指令微調,使用其原始的自回歸目標進行預測 token 的訓練。
對於長度為 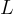 的序列,目標答案
的序列,目標答案 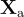 的機率計算為:
的機率計算為:
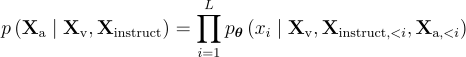
其中 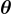 代表可訓練的參數,
代表可訓練的參數,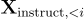 表示在當前預測 token
表示在當前預測 token 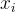 之前的所有輪次的指令 token,
之前的所有輪次的指令 token,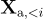 代表所有先前輪次的答案 token。
代表所有先前輪次的答案 token。
對於LLaVA模型的訓練,他們考慮了兩階段的指令微調過程:
以下是原始GPT-4論文中的示例。

他們還通過變化訓練數據集來評估不同類型指令跟隨數據的有效性。

以下是ScienceQA的結果,其中包含21,000個多模態多選題問題。


