古人云:數據分析就像做菜,如果挑選的食材不新鮮,怎麼可能煮出美味佳餚?(Gordon Ramsay或江振誠好像可以哈哈)
在大學期間,我們教授常說在進行數據分析最怕就是:「Garbage in, garbage out」,這句話聽起來不正經但實際上超辣眼睛
結論就是好的數據可以讓我們少走很多歪路哈哈
溫馨提醒:透過網路爬蟲獲得的資料在使用上必須遵守法律
當我們在進行數據分析前,我們必須先了解我們所獲得的數據的一些基本狀態,如:是否有缺失值、欄位的類別、基本的統計訊息等
這裡示範如何透過pandas進行EDA:
import pandas as pd
import numpy as np
data = pd.read_csv('/content/Titanic.csv')
data.head()
data.info()
data.describe()
pd.read_csv(file_path)讀取資料data.head() 用來看前五筆資料,對資料內容有一個初步的了解data.info() 用來看資料欄位的類別和是否有缺失值data.describe() 用來看資料欄位的統計訊息,包括:平均值、標準差、最大值、最小值等在進行分析前,對原始資料進行清理、轉換和整理的過程。
清理資料集中的異常值和缺失值
將不同來源的數據集進行合併。
將數據轉換成適合用來分析的格式,主要的內容包括:
程式碼如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 建立資料集
data = {
'A': [1, 2, np.nan, 4, 5, np.nan, 7, 8, 9, 10],
'B': [5, 15, 20, np.nan, 50, 60, 70, 80, 90, 100],
'C': [100, 200, 300, 400, 500, 600, 700, 800, 900, 10000]
}
df = pd.DataFrame(data)
# 查看數據集的基本情況
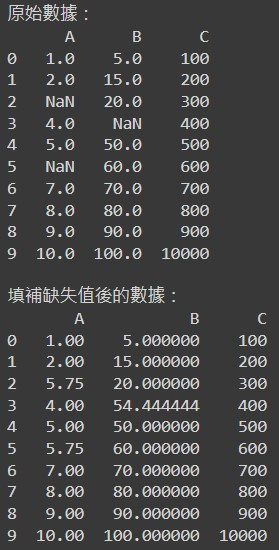
print("原始數據:")
print(df)
# 1. 處理缺失值:用平均值填補缺失值
df['A'].fillna(df['A'].mean(), inplace=True)
df['B'].fillna(df['B'].mean(), inplace=True)
print("\n填補缺失值後的數據:")
print(df)
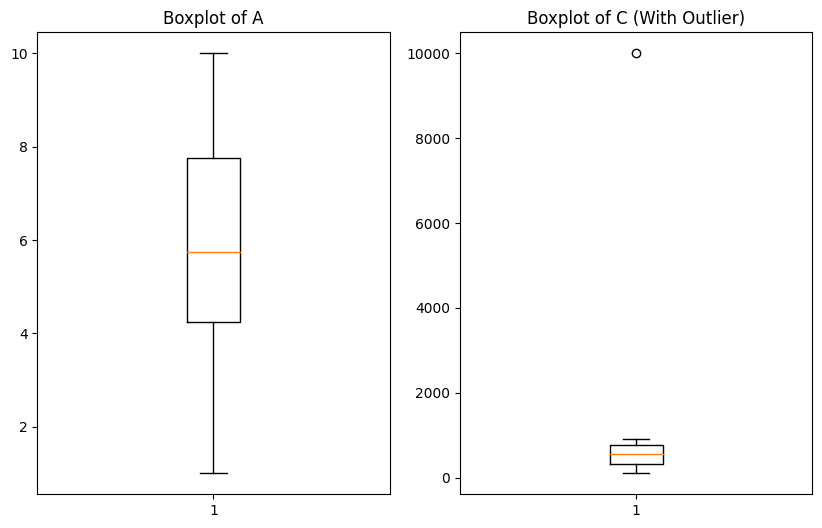
# 2. 檢測異常值:使用box plot
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
plt.boxplot(df['A'])
plt.title('Boxplot of A')
plt.subplot(1, 2, 2)
plt.boxplot(df['C'])
plt.title('Boxplot of C (With Outlier)')
plt.show()
原始資料跟資料清洗後的資料如下:
Box plot結果如下:
騎車回家最肚爛就是快到家的時候突然來一陣超爆大的雨...

