Kubernetes 的基本執行單位 --- Pod
Kubernetes 的架構 --- Cluster
Cluster 的基本硬體單位 --- Node
Node 的必要組件:kubelet、container runtime、kube-proxy
Node 的角色:Master Node、Worker Node
Master Node 的特殊組件:kube-apiserver、etcd、kube-scheduler、kube-controller-manager
了解 HA cluster 的設計方式。
在正式開始建置、操作 Kubernetes 之前,我們得先了解 k8s 的整體架構與組件。底下會嘗試用一個船隊的比喻,來介紹 K8s 中各類組件的專有名詞。
那就讓我們從 Kubernetes 最基本的執行單位談起吧。
K8s 是一個容器編排平台,被管理的容器會在 Pod 中執行:
一個 Pod 可視為「一個功能」,例如「提供網頁功能的 Pod」、「提供資料庫功能的 Pod」。
一個 Pod 會提供「什麼功能」取決於跑在 Pod 裡的容器。
一個 Pod 能跑 1 個或多個容器,視情況選擇:
大多數情況下為確保容器運作時的獨立與穩定性,通常會採用 Single-container Pod。
Pod 被產生時會賦予一個「虛擬 IP」,用來與其他 Pod 溝通。
虛擬 IP 由 CNI (Container Network Interface) 負責分配,這裡先有個印象即可。關於這個部分這個部分會在 Day 20介紹。
當 Pod 被刪除後,裡面的容器也會被刪除。
Pod 會被調度到 Node 上執行,Node 就是一台電腦,可以是實體機 or 虛擬機。
下圖為 Pod 與 container 的關係:
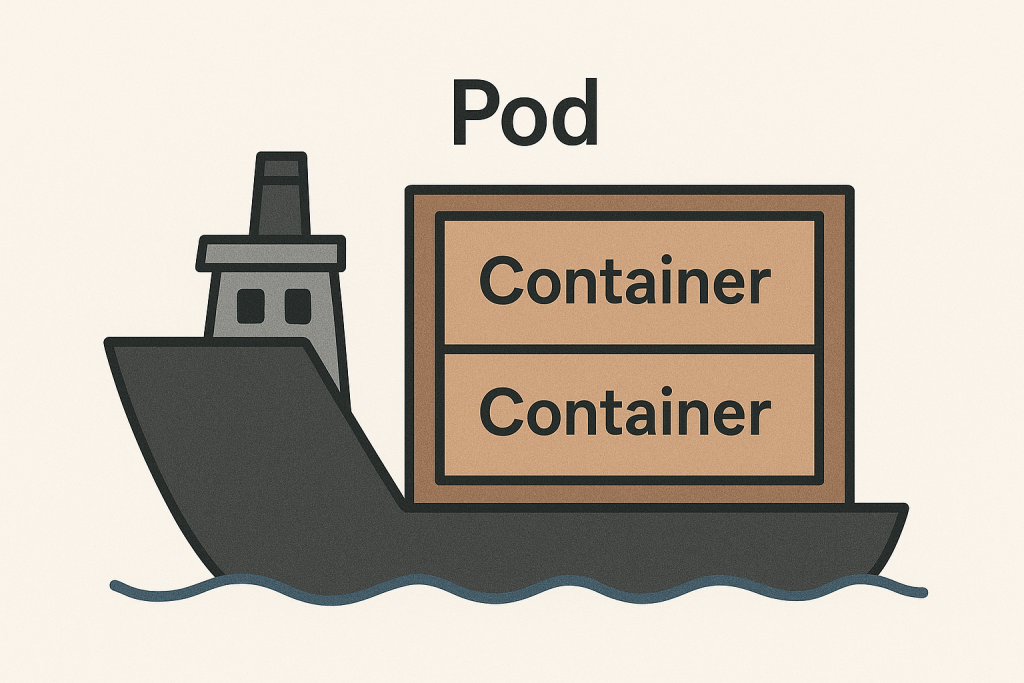
以船隊的比喻來說,Pod 就是船上的貨櫃,而容器就是貨櫃裡面的貨物。
那麼這些 Pod 又是如何被 K8s 管理呢?在回答這個問題之前,我們得先了解 K8s 的基本架構,也就是 cluster。
Cluster (叢集)是一種 topology。當你部署了 Kubernetes,一個由「Node (節點)」組成的 cluster 就形成了。
對 K8s cluster 來說,這些 Node 的功能如下:
如果 cluster 想像成一個船隊,「船」就是 Node,船上載著貨櫃 (Pod)。
現在我們知道,Node 就是一台電腦(伺服器),會提供執行環境給 Pod。
不過,並非隨便一台電腦都能直接塞進 cluster 中做為 node。想讓一台電腦有資格做為 node,必須要安裝以下組件:
Kubelet
相當於每艘船 (也就是 Node) 上的船長,負責執行總指揮 (Master Node,等等會提到) 傳遞的命令。例如執行、刪除 Pod、監控 Pod 的狀態等等。
Container Runtime
Kubernetes 透過 Container Runtime Interface 與 Container Runtime 溝通,讓 Container Runtime 執行 Pod 中的容器。這裡的歷史故事其實還蠻有趣的:
2013 年,Docker 出現帶起了一陣容器化的風潮,而也帶來了容器管理的需求,因此 Kubernetes 1.0 也在 2015 應運而生。
作為一個「編排系統」,底層「執行容器」的工作並非由 K8s 自己完成,而是依賴 Container Runtime 處理,而當時最火紅的 Docker 就是不二人選。
Docker 本身並非 Container Runtime,而是「包含」 Container Runtime 的容器管理工具。
但隨著容器技術的發展與多元化,K8s 意識到不能被單一的 Docker 綁住,因此於 2016 年推出了自己的 Container Runtime Interface (CRI) 標準,做為與底層 Container Runtime 互動的橋梁。
只要你的 Container Runtime 符合 CRI 標準,就能被 K8s 調用。
尷尬的是,由於 Docker 比較早出生,因此並不符合 CRI 標準,因此 K8s 只能先推出一個叫做「Docker shim」的墊片,充當「翻譯員」,讓 K8s 還是能用 CRI 的規範與 Docker 合作:
k8s -> <CRI> -> Docker shim -> Docker -> Container Runtime
Docker 本身一堆功能,但其實 K8s 只需要 Docker 的 Container Runtime 而已,再加上 Docker shim 這個「翻譯員」,資源的消耗就變得更多了。
2017 年,Docker 將自家核心的 Container Runtime --- containerd 捐給了 CNCF。同為 CNCF 專案的 K8s ,與 containerd 的關係就像是「同門師兄弟」。
containerd 身為「師弟」,當然得遵從「師兄」的 CRI 標準,因此 Docker shim 與 Docker 被棄用,改為了 CRI-containerd 與 containerd 的組合:
k8s -> <CRI> -> CRI-containerd -> containerd -> Container Runtime
雖然成功擺脫了 Docker,但還是有 CRI-containerd 這個 daemon 要跑,資源的消耗還有優化空間。因此後來將 CRI-containerd 的功能直接做成 plugin 整合進 containerd 裡,自此 K8s 就可以直接與 containerd 溝通了:
K8s -> <CRI> -> containerd
到了這一步,終於實現了當初的目標:K8s 不被 Docker 綁死,只要你的 Container Runtime 符合 CRI 標準,就能被 K8s 調用。
目前最主流的 Container Runtime 有 containerd、CRI-O等等。
Kube-porxy
上面已經介紹了兩個組件,分別是 kubelet 與 container runtime。這兩個組件負責讓 Pod 在 Node 上跑起來,那通訊的部分呢?
我們知道容器的生命週期短,所以 IP 經常會因重啟而改變。為了讓大家能穩定的存取到 Pod,通常會使用 K8s 中的「Service」提供一個固定 IP 或存取方式:
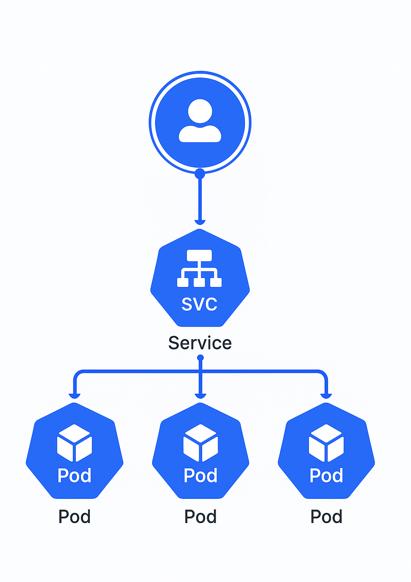
而 Service 與 Pod 之間的流量轉發,都由 kube-proxy 負責。kube-porxy 會監控 Service 與 Pod 的變化,並將使用者發送到 Service 的流量正確的轉發到 Pod。
OK,到這裡我們就介紹完 Node 上的必要組件,簡單複習一下:
kubelet 負責接收指令將 Pod 放到 Node 上執行,container runtime 負責將 Pod 中的容器跑起來,kube-proxy 負責將流量轉發到 Pod 上。
我們剛剛有說 kubelet 是每艘小船的船長,接收「總指揮」的命令。這個總指揮的正式名稱其實是「Master Node」:
Master Node
又稱為「Control Plane」,負責管理與指揮整個 cluster,例如資源調度、cluster 的狀態監控等等。
K8s 管理員可以透過 CLI (Command Line Interface) 或 API 來下達指令或任務給 Master Node。
K8s 的 CLI 是 kubectl,明天會實際安裝。
Worker Node
Pod 會被 Master Node 調度到 Worker Node 上執行,所以 Worker Node 需負責提供 Pod 的執行環境,並在 Master Node 的指揮下執行任務。
如果 cluster 想像成一個船隊,那麼其中負責管理、發號施令的主船,就稱為 Master Node,負責接收主船命令並執行的小船,就稱為 Worker Node。
Master Node 身為整個船隊的總指揮,除了擁有上述提到的三個組件(kubelet、container runtime、kube-proxy)外,還有額外四個特殊的組件:
kube-apiserver
在整個 cluster 中,任何訊息的傳遞,都必須經過 kube-apiserver 的轉介。
萬一 kube-apiserver 發生故障,就等於 cluster 的通訊系統癱瘓了,所以 kube-apisever 是一個極為重要的組件。
etcd
以 key-value 的方式存放整個 cluster 中的資料,例如 cluster 的狀態、目前存在的資源等等。
備份 etcd 是一項重要的工作,因為當整個 cluster 壞掉時,我們可以藉由還原 etcd 的備分來重建 cluster。
kube-scheduler
負責 cluster 中資源的調配,例如哪些 Pod 該放到哪個 Node 上。
kube-scheduler 幫 Pod 找到目的 Node 後,scheduler 會通知 kube-apiserver,kube-apiserver 再通知目的 Node 的 kubelet 把 Pod 跑起來。
kube-controller-manager:
Cluster 各種物件的管理者,是許多控制器(e.g. Node-Controller、Replication-Controller)的集合體。
kube-apiserver 會從各個 Node 上的 kubelet 獲取各種資源的狀態,若資源狀態與使用者期望的不一致,controller manager 會負責將資源調整至「期望狀態(Desired status)」。
以上就是關於 Node 以及其組件的大致介紹。如果還是覺得有些混亂的話,這裡再次用船隊的比喻總結一下:
如果想像整個 cluster 是一個船隊,那麼 Node 就是船、Pod 就是船上的貨櫃,容器就是貨櫃裡的貨物、貨物由 Container Runtime 產生。
所有的船 (Node) 都有這三個組件:kubelet、kube-proxy、Container Runtime。
在船隊中擔任總指揮的主船 (Master Node),則另外擁有這四個元件 : kube-apiserver、etcd、kube-scheduler、kube-controller-manager。
總指揮(Master Node)的傳達給小船(Worker Node)的各種指令,都是由 kube-apiserver 發送給船長 kubelet 來完成的。
船上的通訊系統由 CNI 負責發 IP、kube-proxy 負責轉發流量。
官網圖示:
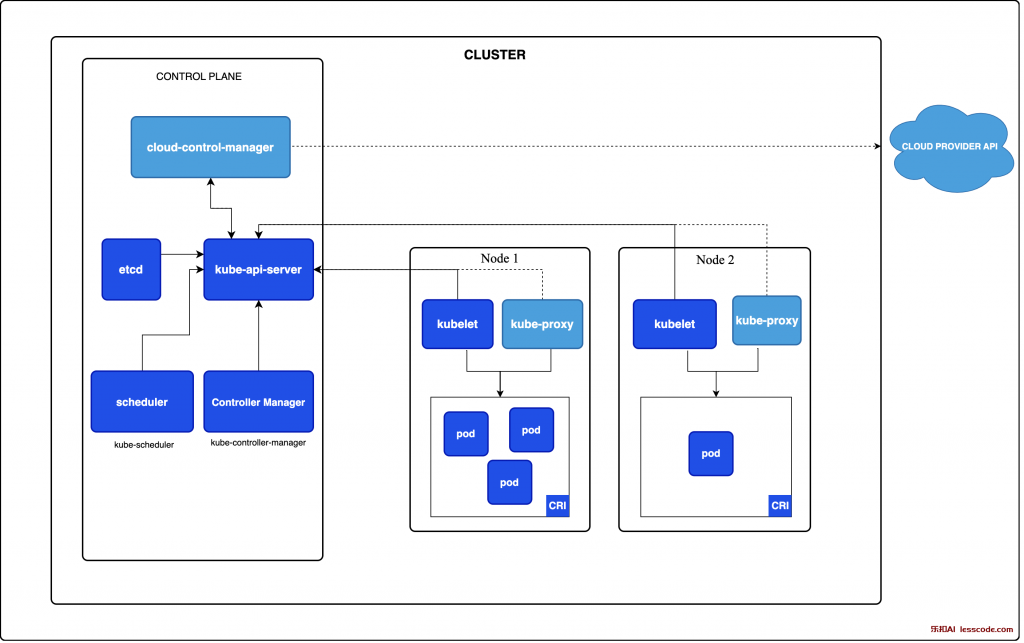
結合以上介紹,我們來看一下「當使用者告訴 kube-apiserver 要建立一個 Pod 時,會發生了什麼事?」:
使用者透過 CLI 或 API 告訴 api-server 要建立一個 Pod。
api-server 對使用者作身分驗證,確認他有建立 Pod 的權限。
api-server 將新 Pod 的資訊寫入 etcd。
api-server 告訴 scheduler 要找一個合適的 Node 來執行新的 Pod。
找到適合的 Node 後,scheduler 透過 api-server 將該 Node 寫入 etcd。
目前為止,Pod 的 spec 與該去哪裡都僅存在於 etcd 中,還沒有真正的執行。kubelet 透過 api-server 知道有 Pod 要建立,會負責拉取需要的 Image、調用 Container Runtime 建立容器、調用 CNI 來分配 IP 給 Pod。
Pod 無論是否成功跑起來,都會向 api-server 回報 Pod 的狀態,狀態會被寫回 etcd。
可以發現,任何通訊基本上都要經過 kube-apiserver,這也是為什麼 kube-apiserver 是 cluster 中最重要的組件之一。
當 cluster 中僅存在一台 Master Node 時,如果 Master Node 發生故障,雖然在 Worker Node 上的 Pod 仍能正常運作,但是 cluster 的管理功能將會癱瘓,例如:因為缺少在 Master Node 上的 kube-apiserver,管理員就無法用指令或 API 來管理 cluster。
為了避免這種情況,在實際的生產環境中通常會建立一個高可用性 (High Availability) 的 cluster,也就是 HA cluster。
所謂「高可用性」就是「提高容錯率」,HA cluster 擁有多個 Master Node,避免單點故障的情況發生。除此之外,因為多個 Master Node 的原因,etcd 儲存的資料也會有多個副本,這樣一來即使某個 etcd 發生故障,也能透過其他 etcd 的資料來恢復 cluster。
不過,多個 Master Node 上就代表著有多個 api-server,因此 HA cluster 會有一個負載平衡器 (Load Balancer) 來分配流量。
在設計 HA cluster 時,依據需求的不同,我們有兩種 topology 可以選擇:
Stacked etcd topology
Stacked etcd topology 至少需要三台 Master Node 組成。其實我們前面介紹的就是 stacked etcd,也就是 Master Node 與 etcd 部署在同一台機器上,這樣的好處是容易部署與管理,但必須承擔同時失去 Master Node 與 etcd 的風險。
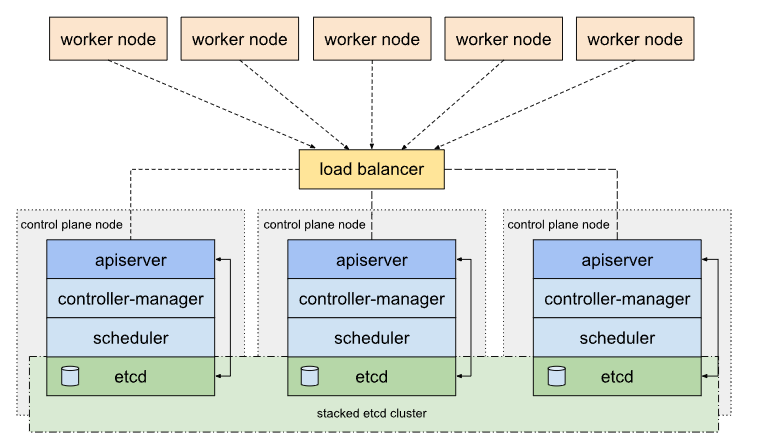
External etcd topology
External etcd topology 至少需要三台 Master Node 與三台 etcd server。 將 etcd 獨立部署在另一台機器上,這樣一這樣的好處是可以避免同時失去 Master Node 與 etcd,但部署複雜度較高,且需額外負擔 etcd server 的成本,比起 Stacked etcd 所需的 server 數量多出一倍。
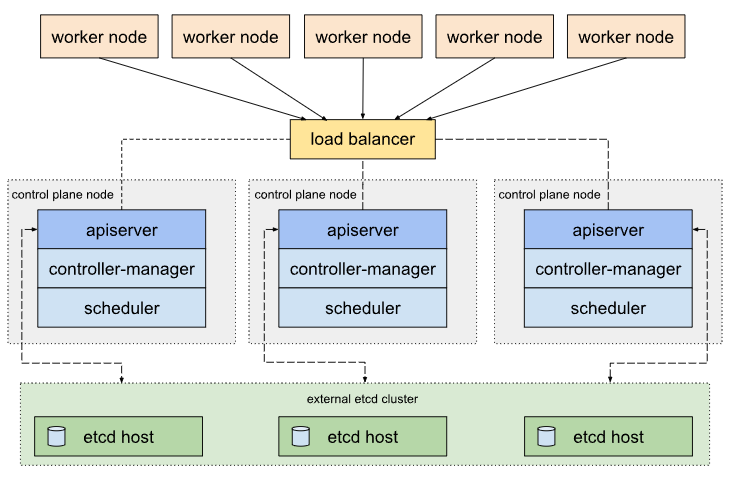
也就是說,「成本與風險」之間的考量決定了我們選擇哪一種 topology。
你可能會好奇,為什麼兩種 topology都至少需要三個 etcd,而不是兩個、四個或其他數字?這是因為 K8s 採取了 RAFT 演算法來保證 etcd 的高可用性與資料一致性,該演算法會從 N 個 etcd 中選出一個作為 Leader,選舉過程大致如下:
在沒有 Leader 的情況下,每個 etcd 都是 Candidate(候選人)。
每個候選人都會設有隨機的倒數計時器,等待時間到後,候選人會向其他人發送投票請求。
他人收到投票請求後,若當下還沒有產生 Leader,則投票給該候選人。
若某候選人收到超過半數的選票,則成為 Leader,其餘的則成為 Follower。
新 Leader 會定期發送「心跳訊息」給所有 Follower,用來重置倒數計時器,以免 Follower 重新變成 Candidate。
若 Leader 故障,Follower 沒收到「心跳訊息」會認為沒有 Leader,則回到步驟一重新選舉。
可以看出,誰的倒數計時器最快結束,獲選為 Leader 的機率較高。
決定好 Leader 與 Follower 後,當使用者送出「寫入資料的指令」時,會經歷以下步驟:
Leader 將該指令寫入自己的 Log 中。
Leader 將指令複製並傳送給所有 Follower。
Follower 收到指令後,將指令寫入 log 中,並向 Leader 回覆確認。
當 Leader 收到「大多數」,也就是「(N/2) + 1」個 Follower 的確認後,Leader 才會執行該寫入指令,並向使用者回覆確認。反之,若 Leader 收到的確認數量小於「(N/2) + 1」,則該指令失效,無法進行資料同步!
在這樣的情況下,若 etcd 的個數為偶數,就算只損失一個 etcd,在寫入資料時就不可能滿足「步驟四」的條件,所以 etcd 的個數必須為大於 1 的奇數,通常會以 3 ~ 5 個 Master 來設計 HA cluster。
簡單來說,為了避免單一 Master 的風險,我們在權衡風險與成本後,選擇 Stacked etcd 或 External etcd 來設計 HA cluster。又因為 RAFT 演算法,HA cluster 會有奇數個 Master Node,實務上以 3 ~ 5 個為佳。
HA cluster 的建置會比較複雜,這裡以附錄的形式提供給有興趣的讀者:
如果是初學者的話,現階段先了解 HA cluster 的概念即可,因為明天就會介紹如何建置一個「普通」的 cluster,在熟悉建置 cluster 的基本流程後,之後建立 HA cluster 就會更加順手。
今天是 K8s 基礎概念的第一篇,用船隊的比喻,介紹了 K8s cluster 中的基本組件,以及這些組件的功能究竟為何,也另外介紹了 HA cluster 的設計原理,來避免單一 Master 的風險。
了解了 K8s cluster 的架構與組件後,明天我們就會來實際建立一個 cluster !
參考資料

