傳統NLP模型比較小,只需要考慮compute bound的,但現在LLM模型很大了,基本上就是考驗memory bound的時代,這章將來介紹LLM與VRAM。
說到GPU就會想到NVIDIA,算力很高但VRAM給的很少,各位可以觀賞下面精闢的梗圖。跟GPU一樣,在剛開始學習時,也不知道要知道什麼知識,都是用到了再查,所以這邊也整理了一章關於LLM會用到VRAM需要的知識。

(圖源: reddit)
隨機存取記憶體 RAM (Random-Access Memory)
RAM是電腦中可以讀寫的記憶體,跟唯獨記憶體 (ROM)一起構成主記憶體,負責與CPU交換資料,是一種揮發性記憶體,在電腦關機後就會遺失儲存資料。
視訊隨機存取記憶體 VRAM (Video Random-Access Memory)
VRAM是GPU中使用的記憶體,也是揮發性的記憶體。與一般的RAM比較起來,可以提供更高的頻寬,所以可以讓GPU與它之間的資料傳輸速度更快,在任務運作上會有更好的性能。
如果單純跑推理的話,最常見的估計方式是用Model Parameters和Precision做推算,在Day3的部分有提過。
這邊以13B LLM為例,FP16要大概兩倍的記憶體,13b就要26GB VRAM,剩下的以此類推。
| Quantization | GPU Memory | Note |
|---|---|---|
| FP16 / BF16 | 26 GB+ | X 2 |
| INT8 | 13 GB+ | X 1 |
| INT4 | 6.5 GB+ | X 0.5 |
但其實真正Local LLM要使用多少VRAM這部分還有其他影響條件的,關於12已經在Day3學過了,3-5則會在後續的章節提到。
目前最好用的還是這一個,印象中是從李宏毅yt某一堂課程看到的,即使是去年出的顯卡也有被列在上面,且網站上面引用的GPU比較清單、推理計算所需的記憶體部分都非常詳細。
https://huggingface.co/spaces/Vokturz/can-it-run-llm
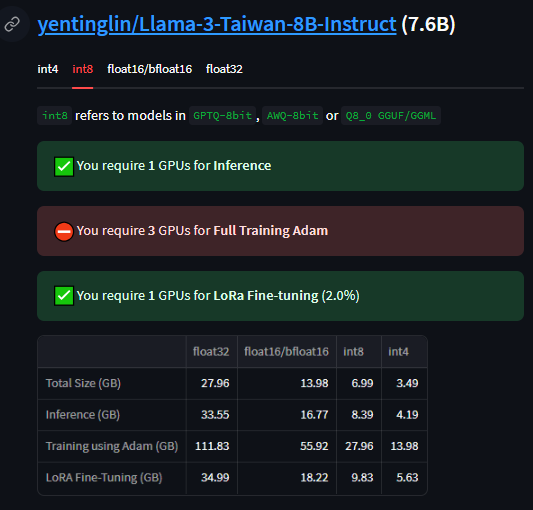
我們在Day5講解過GPU的選擇,這邊可以直接看下面推理的部分。假設筆者很可憐,只有一張GeForce RTX 2080 Ti,我們可以看到如果用FP16或BF16的模型是沒辦法推理的,會花上16.77 GB,硬要跑的話會OOM。
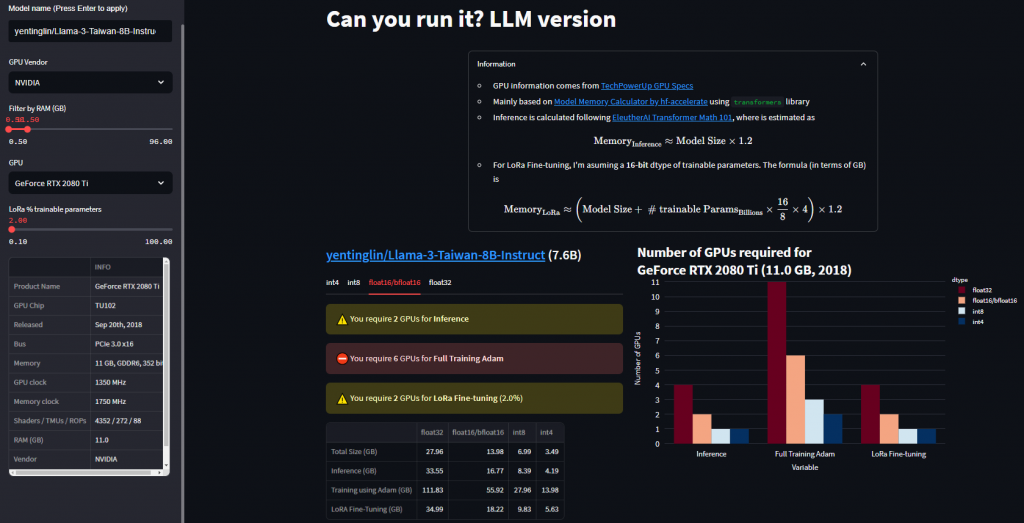
但是如果是跑Int8量化的模型像是AWQ就可以囉!因為他只要花8.39 GB。
在VRAM章節,我們簡單的複習了一下RAM和VRAM的差異,也介紹了LLM影響VRAM使用的幾個可能原因,並提供了簡單的計算網站搭配上一章選擇的GPU去做VRAM需求的估計。當然可能會有如果出現雖然有很多張GPU,每個VRAM無法完全裝下你的模型的狀況,但加起來是可以的,這個設定方法會在後面模型平行化運算的章節提到喔!
下一章將介紹台灣的超級電腦,以及雲端運算資源平台。

(圖源: facebook)
Demystifying VRAM Requirements for LLM Inference: Why It Matters and How to Optimize
https://www.linkedin.com/pulse/demystifying-vram-requirements-llm-inference-why-how-ken-huang-cissp-rqqre/
Understanding VRAM and how Much Your LLM Needs
https://blog.runpod.io/understanding-vram-and-how-much-your-llm-needs/
請問有網頁可以計算如果我要訓練一個大語言模型需要VRAM (包含考慮到一些batch_size、樣本數等參數)
不好意思這麼晚才回覆,謝謝您的留言!其實我對微調LLM的部分所知甚少,不過有看到這個網站:https://apxml.com/zh/tools/vram-calculator
它除了推理之外也有包含微調(全參數、LoRA、QLoRA)的一些參數來推估VRAM,也許您可以試試看!

