接續昨天。
切換進 models 資料夾,執行指令。我這邊使用 os.chdir 來切換資料夾,他可以都寫在一行很方便,跟 Stable Cascade 的範例學來的。
import os
os.chdir('/content/StableCascade/models')
!bash download_models.sh essential small-small bfloat16
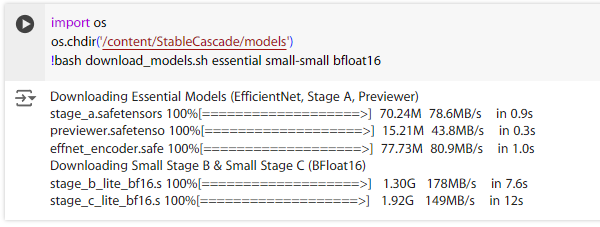
執行完後,在 models 資料夾會看到這些檔案。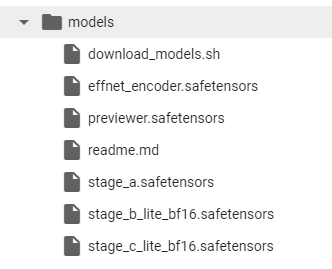
接下來我們開啟放在configs -> inderence 下的 stage_c_3b.yaml 與 stage_b_3b.yaml。
stage_c_3b.yaml:
# GLOBAL STUFF
model_version: 3.6B
dtype: bfloat16
effnet_checkpoint_path: models/effnet_encoder.safetensors
previewer_checkpoint_path: models/previewer.safetensors
generator_checkpoint_path: models/stage_c_bf16.safetensors
stage_b_3b.yaml:
# GLOBAL STUFF
model_version: 3B
dtype: bfloat16
# For demonstration purposes in reconstruct_images.ipynb
webdataset_path: file:inference/imagenet_1024.tar
batch_size: 4
image_size: 1024
grad_accum_steps: 1
effnet_checkpoint_path: models/effnet_encoder.safetensors
stage_a_checkpoint_path: models/stage_a.safetensors
generator_checkpoint_path: models/stage_b_bf16.safetensors
先看到兩份 yaml 文件中的 generator_checkpoint_path,寫的是剛剛下載下來的 stage_c 與 stage_b 的路徑,但他預設載的是大模型,我載的是 small,檔名是 stage_c_lite_bf16.safetensors 與 stage_b_lite_bf16.safetensors,我們需要把 yaml 中的路徑修掉。
接著注意到兩份 yaml 文件中的 model_version,分別是 3.6B 與 3B,small 版本的要改為 1B 與 700M。
最後是兩份 yaml 文件中的 dtype,如果載的是 float32,應該也是要修,我還沒側這個。
改完後的版本:
stage_c_3b.yaml:
# GLOBAL STUFF
model_version: 1B
dtype: bfloat16
effnet_checkpoint_path: models/effnet_encoder.safetensors
previewer_checkpoint_path: models/previewer.safetensors
generator_checkpoint_path: models/stage_c_lite_bf16.safetensors
stage_b_3b.yaml:
# GLOBAL STUFF
model_version: 700M
dtype: bfloat16
# For demonstration purposes in reconstruct_images.ipynb
webdataset_path: file:inference/imagenet_1024.tar
batch_size: 4
image_size: 1024
grad_accum_steps: 1
effnet_checkpoint_path: models/effnet_encoder.safetensors
stage_a_checkpoint_path: models/stage_a.safetensors
generator_checkpoint_path: models/stage_b_lite_bf16.safetensors
接下來就可以照著這份範例運行了。
https://github.com/Stability-AI/StableCascade/blob/master/inference/text_to_image.ipynb
我先切到 StableCascade 資料夾,原本他是寫 os.chdir('..'),記得依照自己的狀態修掉。
先把套件 import 進來,設定好 cuda。
os.chdir('/content/StableCascade')
import yaml
import torch
from tqdm import tqdm
from inference.utils import *
from core.utils import load_or_fail
from train import WurstCoreC, WurstCoreB
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
把 config 讀進來。
# SETUP STAGE C
config_file = 'configs/inference/stage_c_3b.yaml'
with open(config_file, "r", encoding="utf-8") as file:
loaded_config = yaml.safe_load(file)
core = WurstCoreC(config_dict=loaded_config, device=device, training=False)
# SETUP STAGE B
config_file_b = 'configs/inference/stage_b_3b.yaml'
with open(config_file_b, "r", encoding="utf-8") as file:
config_file_b = yaml.safe_load(file)
core_b = WurstCoreB(config_dict=config_file_b, device=device, training=False)
然後讀取模型。
# SETUP MODELS & DATA
extras = core.setup_extras_pre()
models = core.setup_models(extras)
models.generator.eval().requires_grad_(False)
print("STAGE C READY")
extras_b = core_b.setup_extras_pre()
models_b = core_b.setup_models(extras_b, skip_clip=True)
models_b = WurstCoreB.Models(
**{**models_b.to_dict(), 'tokenizer': models.tokenizer, 'text_model': models.text_model}
)
models_b.generator.bfloat16().eval().requires_grad_(False)
print("STAGE B READY")
如果遇到這類異常,可以檢查一下 yaml 檔,但照著上面的步驟做應該是不會有問題。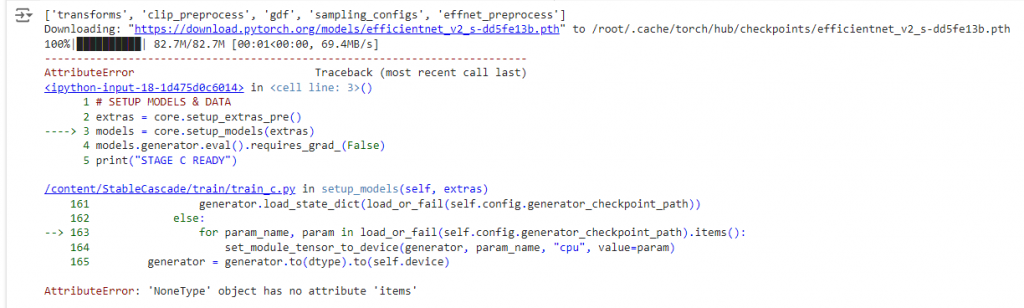
接著是 Compile model,這是 torch 的加快運行速度的方法。
Git 上寫說是選用,但我沒有測試執行與沒執行的速度差了多少,之後有測再補上。
https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html
models = WurstCoreC.Models(
**{**models.to_dict(), 'generator': torch.compile(models.generator, mode="reduce-overhead", fullgraph=True)}
)
models_b = WurstCoreB.Models(
**{**models_b.to_dict(), 'generator': torch.compile(models_b.generator, mode="reduce-overhead", fullgraph=True)}
)
到這邊基本設定就完成了,明天繼續開始使用模型。

