之前我們有提到LangChain的結構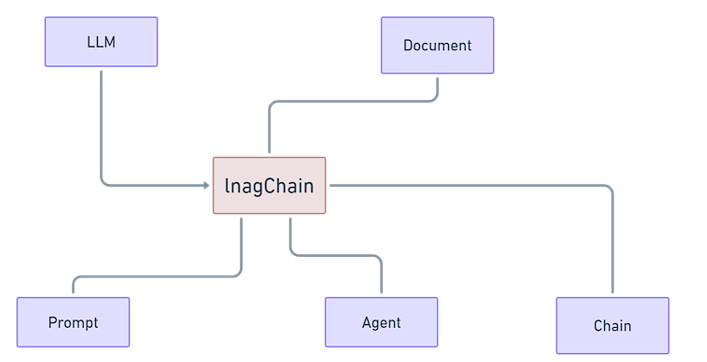
現在我們已經有Prompt、LLM、Chain
現在我們要開始介紹Document的部分,我們會介紹提示工程的RAG技術來擴充這個元件。
RAG(Retrieval-Augmented Generation)將檢索技術與生成技術結合的NLP架構,主要目的在增強生成模型,能夠生成更精確且上下文相關的回應,由檢索模型(retriever)和生成模型(generator)兩個部分組成。
檢索模型(Retriever):在生成回應之前,RAG 使用檢索模型從外部資料庫(也可以自己建立)提取相關資料。可以是文件資料庫、網頁,或者其他資料源。
生成模型(Generator):檢索模型提供的內容被傳遞給生成模型,生成模型會根據傳遞來的內容微調模型,不需要對模型進行重新訓練,並且生成更加可靠的回答,甚至還能減少幻覺(hallucination)。
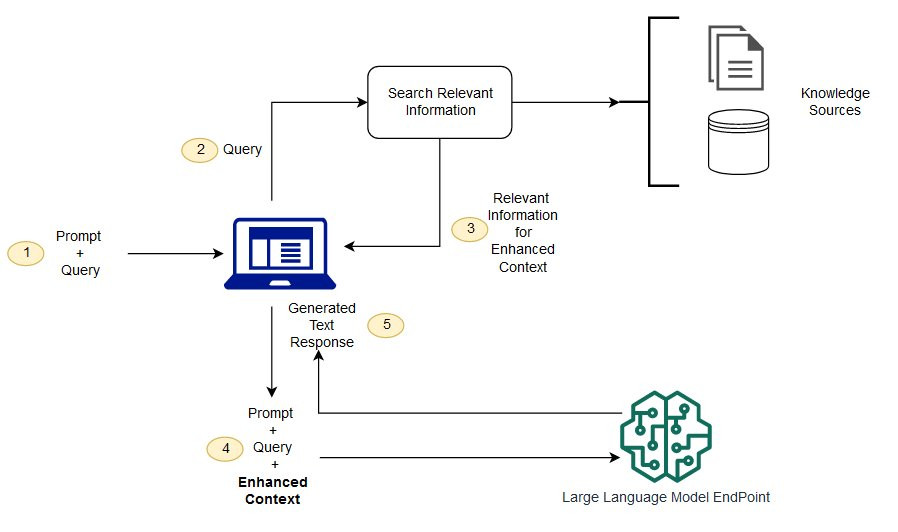
用戶輸入:
用戶提出一個查詢,例如一個問題。
檢索階段:
檢索模型會將查詢轉換為一個向量,根據這個向量從***預先建立的資料庫***中找到與查詢最相關的文檔或資料片段。
生成階段:
將檢索到的文件片段與原始查詢一起輸入到生成模型中,生成模型會基於這些資訊來生成一個回答。
回應輸出:
最終的回答會返回給用戶,通常回答會更加的準確,因為它結合了更即時而且有根據相關的檢索資料。
在檢索階段,我們之後會需要預先建立一個資料庫,因此我們會詳細的介紹我們建立資料庫的過程,另外轉換成向量的部分,我們會採用LLM所提供的embedding model,接著再進行相似度比對,比對查詢和資料庫的文件內容。
在生成階段我們會將檢索到的文件或是資料片段放入到Prompt中,來進行提示。
動態資訊獲取:RAG能從外部資料庫中檢索最新的或更全面的資料,生成模型則負責將這些資料用自然語言流暢地表達出來,RAG使得生成模型處理需要最新或是精確知識的任務中表現更好。
知識增強:對於一些訓練資料有限的生成模型,RAG可以通過檢索外部知識來增強其知識不足方面。
RAG 讓語言模型不用重新訓練就能夠獲得最新的訓練資料,並且跟現有的資料進行結合,降低成本之外,還能夠減少幻覺(hallucination)。
檢索文件品量:RAG 的表現很大程度上依賴於檢索到的文件品量。如果檢索模型沒有找到合適的文件,那麼就不會有內容傳遞給生成模型。
增加檢索成本:RAG 的雙模型結構需要更多的運算資源,因為它不僅需要運行生成模型,還需要運行一個檢索模型進行實時資料的檢索。
https://nips.cc/virtual/2020/public/poster_6b493230205f780e1bc26945df7481e5.html
https://aws.amazon.com/tw/what-is/retrieval-augmented-generation/


 iThome鐵人賽
iThome鐵人賽