
摘要
這篇文章主要探討了「AI 代理」領域的最新進展,以吳恩達團隊推出的 Translation Agent 開源工具為例,展現了 AI 如何革新翻譯的效率和準確性。文章首先介紹了 Translation Agent 的工作原理,它透過「反思工作流」模擬人類專業譯者的思考過程,將翻譯任務分解為三個步驟:初始翻譯、反思與改進、優化輸出。透過這種方式,Translation Agent 可以更有效地處理客製化需求,並提供更精準的翻譯結果。接著,文章深入分析了 LangGraph 翻譯助手的核心組件設計,包含狀態定義、輔助函數和核心節點,並以圖示和程式碼片段展示了 LangGraph 的工作流程。最後,文章展望了機器翻譯技術的未來發展方向,例如探索更多元的語言模型、自動生成術語表、評估翻譯質量的新指標等等。這篇文章提供了對 AI 機器翻譯技術發展的深刻見解,並展示了該技術在各行各業的應用潛力。
在這個資訊爆炸的時代,機器翻譯已不再是科幻小說中的幻想,而是我們日常生活中不可或缺的工具。從瀏覽外語網頁到跨國商務溝通,智能翻譯正悄然改變我們與世界互動的方式。然而,傳統機器翻譯在處理高度客製化需求時往往力不從心,難以適應不同場景的語言變體和專業術語。

2023年11月,人工智能巨擘吳恩達(Andrew Ng)團隊推出的開源智能翻譯系統 Translation Agent,標誌著翻譯技術的一個重要里程碑。這個系統不僅是一個翻譯工具,更像是一位能夠理解並持續優化翻譯成果的智能助手。
Translation Agent 的核心在於其創新的「反思工作流」(Reflection Workflow),這一設計巧妙地解決了傳統機器翻譯在客製化和精細控制方面的短板。
Translation Agent 的核心優勢在於其獨特的「反思工作流」,這種創新機制模擬了人類專業譯ˇ者的思考過程,將翻譯任務細分為三個精細步驟。讓我們深入探討這個智能系統的運作原理。
在這個階段,Translation Agent 利用先進的大型語言模型(LLM)進行初步翻譯。

💡 亮點提示:LLM 不僅僅是簡單的字詞對應,它能夠理解上下文,捕捉語言的細微差別。
這是 Translation Agent 最與眾不同的階段。系統會"反思"初次翻譯的結果,就像一個經驗豐富的編輯審閱稿件。

💡 最佳實踐建議:在使用 Translation Agent 時,可以提供特定領域的參考資料或風格指南,幫助系統更好地理解和適應您的需求。
這個革命性的工具不僅提高了翻譯的效率和質量,還為各行各業帶來了新的可能性。讓我們深入探討 Translation Agent 在不同領域的創新應用。
在全球化的商業環境中,Translation Agent 成為跨國企業的得力助手。
💡 亮點提示:使用 Translation Agent 進行商業翻譯時,可以預先設置公司特定的術語表和品牌指南,確保翻譯結果符合企業風格。
在娛樂產業中,Translation Agent 為內容創作者提供了強大支持。
🔍 專業術語解釋:「本地化」不僅包括語言翻譯,還涉及文化適應和用戶體驗的調整。
Translation Agent 為旅遊業帶來了全新的服務可能。
💡 最佳實踐建議:在旅遊應用中整合 Translation Agent,可以大大提升國際遊客的旅行體驗。
讓我們先按照官方 Github 實作看看摟
安裝需要 Poetry 套件管理器。如果你是第一次使用,參考官方教學,這可能有效:
pip install poetry
會用到語言模型,為此運行工作流程需要帶有 OPENAI_API_KEY 的 .env 檔案。請參閱 .env.sample 檔案作為範例。
為了使用 OpenAI API,我們需要設置 OPENAI_API_KEY 環境變數。在 Colab 中,我們可以使用 userdata 來安全地存儲和訪問 API 密鑰。
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
安全提示:請確保不要直接在代碼中暴露您的 API 密鑰。使用 Colab 的 userdata 功能是一種安全的做法。
最後是將專案環境安裝並且建置
git clone https://github.com/andrewyng/translation-agent.git
cd translation-agent
poetry install
整理要翻譯的文本
歡迎來到台灣,你可以使用北北基悠遊卡暢遊整個大台北,三天內的旅遊都可以任意搭乘交通工具,包含:高鐵、台鐵、捷運。祝你有美好的一天!
最後就是使用方法啦
import translation_agent as ta
source_lang, target_lang, country = "Traditional Chinese", "English", "Taiwan"
translation = ta.translate(source_lang, target_lang, source_text, country)
使用結果
我們先來看看專案中的一個關鍵組件:util.py。這個檔案就像是整個翻譯系統的工具箱,裡面裝滿了各種實用的輔助函數和工具。
util.py 包含了一系列支援性函數,這些函數雖然不直接參與翻譯過程,但卻是確保整個系統順暢運行的幕後英雄。從處理 API 請求,到文本分割,再到 token 計算,util.py 中的函數為主要翻譯邏輯提供了堅實的基礎支持。
one_chunk_translate_text 進行單塊翻譯。multichunk_translation 進行分塊翻譯。這個函數處理較短的文本,採用三步驟翻譯法:
one_chunk_initial_translation 獲得初始翻譯。one_chunk_reflect_on_translation 對翻譯進行反思和評估。one_chunk_improve_translation 根據反思結果改進翻譯。針對較長的文本,這個函數將文本分成多個小塊,然後對每個小塊進行三步驟翻譯:
num_tokens_in_string:計算文本的 token 數量。calculate_chunk_size:根據總 token 數和限制計算合適的塊大小。get_completion:與 OpenAI API 交互,獲取 AI 生成的內容。看圖可能方便理解些
提示:翻譯流程:整個翻譯過程遵循「翻譯-反思-改進」的模式,這模擬了專業翻譯者的工作流程。
在這個章節中,我們將深入探討 LangGraph 翻譯助手的核心組件,揭示它們如何協同工作,共同打造一個高效、靈活的翻譯系統。從狀態管理到具體的翻譯邏輯,每個組件都在整個翻譯流程中扮演著關鍵角色。
首先,我們需要安裝必要的套件:
pip install --upgrade --quiet langchain langchain-openai langgraph
為了使用 OpenAI 的服務,我們需要設置 API 金鑰:
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
提示:請確保您已經在 OpenAI 官網註冊並獲取了 API 金鑰。
在構建我們的 LangGraph 翻譯助手時,核心組件的設計至關重要。這些組件不僅決定了翻譯流程的效率,還直接影響了翻譯結果的質量。讓我們深入探討每個核心組件,了解其設計原理和實現細節。
翻譯過程的核心是 TranslationState 類,它使用 Pydantic 的 BaseModel 確保數據的一致性和類型安全。
class TranslationState(BaseModel):
source_lang: str
target_lang: str
country: Optional[str] = None
source_text: str
source_chunks: List[str] = Field(default_factory=list)
initial_translation: Optional[str] = None
initial_translation_chunks: List[str] = Field(default_factory=list)
reflection: Optional[str] = None
reflection_chunks: List[str] = Field(default_factory=list)
final_translation: Optional[str] = None
final_translation_chunks: List[str] = Field(default_factory=list)
TranslationState 類是整個翻譯過程的核心。它使用 Pydantic 的 BaseModel 來確保數據的類型安全和一致性。讓我們詳細解析其中的關鍵屬性:
使用列表存儲 chunks 允許我們靈活處理長文本,同時保持翻譯的連貫性。
💡 亮點提示:TranslationState 不僅存儲數據,還作為各處理節點間的信息傳遞媒介,確保整個翻譯過程的狀態一致性。
get_completion 函數
函數封裝了與 OpenAI API 的交互,提供了靈活的參數設置,使得在翻譯過程中能夠根據需要微調 AI 模型的行為。
def get_completion(prompt: str, system_message: str = "You are a helpful assistant.", model: str = "gpt-4-turbo", temperature: float = 0.3):
response = openai.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": prompt}
],
temperature=temperature
)
return response.choices[0].message.content
這個函數封裝了與 OpenAI API 的交互。它的設計考慮了以下幾點:
def num_tokens_in_string(input_str: str, encoding_name: str = "cl100k_base") -> int:
encoding = get_encoding(encoding_name)
return len(encoding.encode(input_str))
def calculate_chunk_size(token_count: int, token_limit: int) -> int:
if token_count <= token_limit:
return token_count
num_chunks = (token_count + token_limit - 1) // token_limit
chunk_size = token_count // num_chunks
remaining_tokens = token_count % token_limit
if remaining_tokens > 0:
chunk_size += remaining_tokens // num_chunks
return chunk_size
這兩個函數協同工作,確保我們能夠有效地處理長文本:
num_tokens_in_string 利用 tiktoken 庫準確計算文本的標記數,這對於控制 API 請求的大小至關重要。calculate_chunk_size 智能地計算最佳的文本分割大小,確保每個分割後的塊都不會超過 API 的標記限制,同時盡可能減少分割次數。🔍 專業術語解釋:「標記」(token) 在自然語言處理中指的是文本的最小單位,可能是單詞、標點符號或字符組合。API 通常限制每次請求的標記數量。
這個節點負責將長文本智能地分割成適合處理的小塊,是處理大規模文本翻譯的關鍵。
def text_splitter_node(state: TranslationState) -> TranslationState:
num_tokens = num_tokens_in_string(state.source_text)
if num_tokens < MAX_TOKENS_PER_CHUNK:
state.source_chunks = [state.source_text]
else:
token_size = calculate_chunk_size(num_tokens, MAX_TOKENS_PER_CHUNK)
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=token_size,
chunk_overlap=0,
)
state.source_chunks = text_splitter.split_text(state.source_text)
return state
這個節點負責文本的智能分割:
def single_chunk_translation_node(state: TranslationState) -> TranslationState:
system_message = f"You are an expert linguist, specializing in translation from {state.source_lang} to {state.target_lang}."
prompt = f"""Translate the following text from {state.source_lang} to {state.target_lang}.
Do not provide any explanations or text apart from the translation.
{state.source_lang}: {state.source_text}
{state.target_lang}:"""
state.initial_translation = get_completion(prompt, system_message)
return state
這個節點執行實際的翻譯操作:
這兩個節點組成了翻譯質量保證的核心:
這種雙重檢查機制大大提高了最終翻譯的質量和準確性。

source_lang = "English"
target_lang = "Spanish"
source_text = "Hello, how are you? This is a test of the translation system."
translated_text = run_translation(
source_lang = source_lang,
target_lang = target_lang,
country = "Taiwan",
source_text = source_text
)
print(f"Translated text: {translated_text}")

source_lang = "Tradiaional Chinese"
target_lang = "Korea"
source_text = "如果您要參加即將活動,您必須先完成任務。"
translated_text = run_translation(
source_lang = source_lang,
target_lang = target_lang,
country = "Taiwan",
source_text = source_text
)
print(f"Translated text: {translated_text}")

為進一步提升 Translation Agent 的性能,研究團隊正在探索以下方向:
即刻前往教學程式碼 Repo,親自動手體驗翻譯代理結合反思的魅力吧!別忘了給專案按個星星並持續關注更新,讓我們一起探索AI代理的新境界。
感謝分享,請問
[0:tasks] Starting step 0 with 1 task:
- __start__ -> TranslationState(source_lang='Tradiaional Chinese', target_lang='Korea', country='Taiwan', source_text='如果您要參加即將活動,您必須先完成任務。', source_chunks=[], initial_translation=None, initial_translation_chunks=[], reflection=None, reflection_chunks=[], final_translation=None, final_translation_chunks=[])
[0:writes] Finished step 0 with writes to 8 channels:
- source_lang -> 'Tradiaional Chinese'
- target_lang -> 'Korea'
- country -> 'Taiwan'
- source_text -> '如果您要參加即將活動,您必須先完成任務。'
- source_chunks -> []
- initial_translation_chunks -> []
- reflection_chunks -> []
- final_translation_chunks -> []
[1:tasks] Starting step 1 with 1 task:
- text_splitter_node -> ......
這些是只有使用 ipython notebook 才會 show 的嗎? 我把程式碼整理成 python script 開 debug mode 去跑都沒有 show 中間過程,只有最後的 print
Hi @老漢 感謝你的實作以及提問,花了點時間嘗試驗證這個是否只有 ipython 環境下會顯示,中間過程,目前我在以下環境中測試依然能夠顯示結果。
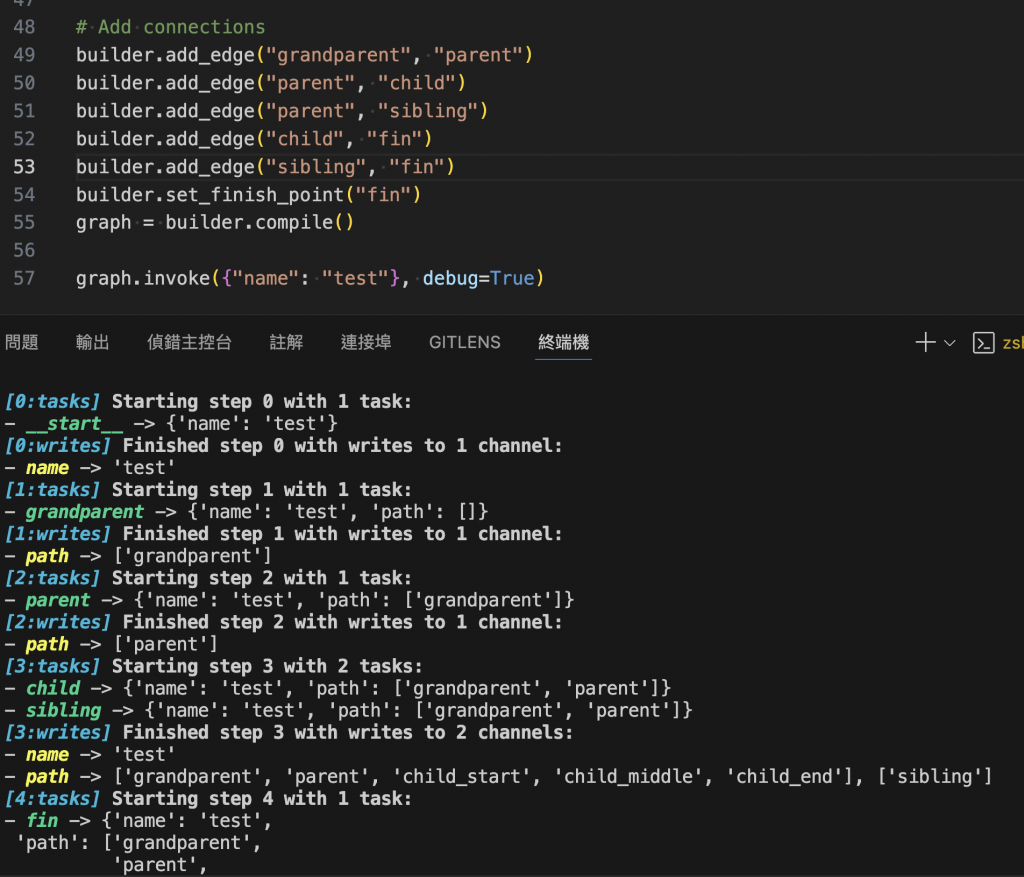
#環境同 範例
langchain==0.2.10
langchain-openai==0.1.17
langgraph==0.1.9
背後機制:IPython / Notebook 與純 Python 對輸出結果的攔截與呈現方式不同
麻煩協助檢查套件版本、專案中 logging 顯示資訊了
實作程式碼參考:https://www.baihezi.com/mirrors/langgraph/how-tos/subgraph/index.html
