簡介
隨著機器學習技術的快速發展,如何選擇和建立合適的演算法成為了打造高效模型的關鍵步驟。機器學習中的演算法種類繁多,每種演算法都有其獨特的特性和適用場景。scikit-learn 提供的演算法選擇圖是實用工具,幫助我們根據具體需求選擇合適的演算法。接下來將針對如何看圖進行演算法的選擇考量因素及建立演算法的基本流程進行解釋。
演算法選擇的考量因素
Scikit-learn 官方網站提供的 cheat-sheet 可以看到,從 START 的地方開始走流程。在開始之前,我們需要先知道有三大項目是需要考量的,包含想要解決的問題類型、資料集特性以及模型解釋性。
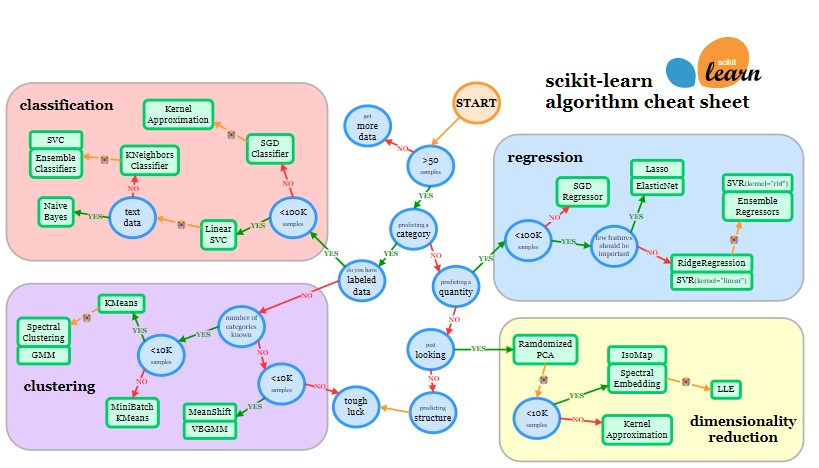
[source]
- 問題類型:主要可以分成兩種類型(監督和非監督式學習),而在流程圖中也可以清晰看到分為四項任務(分類、回歸、聚類、降維)。
- 監督式學習:有標註(Label)的資料
- 非監督式學習:沒有標註(Label)的資料
- 聚類:自動將相似的東西分組
- 降維:簡化資料,保留重要資訊
- 資料集特性:主要包括資料量大小、資料質量及特徵數量。資料的數量和品質會影響我們選擇哪種演算法。有些演算法適合大量資料,有些則可以處理有缺失或不精確的資料。
- 資料量的大小:有多少筆資料可以用
- 資料的質量:資料是否完整、準確
- 特徵數量:可能需要考慮降維技術
- 模型解釋性:有些模型很容易解釋它們是如何做決定並進行預測的,有些則比較難理解,就像黑盒子一樣。根據我們的需求,可能需要選擇容易解釋的模型,或者選擇難以解釋但效果更好的模型。
了解這三個因素,可以幫助我們更好地使用 scikit-learn 的流程圖,為我們的問題找到最合適的演算法。在接下來的內容中,我們會更詳細地解釋如何根據這些因素來選擇演算法。(請搭配流程圖一起看喔~)
演算法流程圖該怎麼使用-四大任務判斷法
在選擇演算法流程圖中,我們可以從 START 的位置開始,按照以下步驟進行先行判斷是哪一種任務型:
- 確認資料量:首先判斷您手上經過數據清理後的資料量是否超過 50 筆(樣本數)。
- 若不超過 50 筆數據,請繼續努力收集更多數據,因為數據量過少會導致模型效果不佳。
- 若超過 50 筆數據,則進入下一步判斷。
- 判斷問題類型:確認您要解決的問題是否屬於類別型問題。
- 若是類別型問題,進一步確認資料是否為有標註(Label)。
- 若有標註資料,則進入分類(Classification)區塊,表示您要解決的問題為分類問題。例如,若要預測一張照片是貓還是狗,需要有標註的貓和狗的照片。
- 若沒有標註資料,則進入聚類(Clustering)區塊,表示您要解決的問題為分組問題,不會知道預測結果具體會是哪一類別。例如,若只有一堆貓和狗的照片,但沒有標註,在聚類分析中只能將照片分為兩類,而無法確定哪類是貓哪類是狗。
- 若非類別型問題,則判斷要預測的結果是否為數值型。
- 若是數值型問題,則進入回歸(Regression)區塊,表示您要解決的是回歸問題。例如,要預測房屋的售價,需要用數值型資料進行預測。
- 若問題既不是類別型也不是數值型,請深入探討是否需要預測。
- 若問題不需要預測,可能不需要使用機器學習方法。
- 若需要簡化資料,則會使用降維(Dimensionality Reduction)方法。例如,將高維度資料轉換為低維度資料,以便於後續的分析和建模。
演算法流程圖該怎麼使用-演算法的選擇
在判斷完任務類型後,我們可以進一步細化選擇適合的演算法。接下來,我們會針對回歸、分類、聚類和降維四大類任務,繼續介紹演算法流程圖中的判別方式及常見的演算法。
監督式學習:分類(Classification)
當您判斷問題為分類問題時,接下來依據數據量選擇合適的演算法:
- 數據量小於 10 萬筆:
- 首先選擇 Linear SVC。
- 若訓練結果不如預期,判斷數據是否為文本類型:
- 是:選擇 Naive Bayes。
- 否:選擇 K Neighbors Classifier。
- 若結果仍不符預期,嘗試 SVC 或 Ensemble Classifiers。
- 數據量超過 10 萬筆:
- 首先選擇 SGD Classifier。
- 若結果不符預期,可嘗試採用 Kernel Approximation。
監督式學習:回歸(Regression)
當您判斷問題為回歸問題時,接下來依據數據量選擇合適的演算法:
- 數據量小於 10 萬筆:
- 判斷是否有重要特徵:
- 是:嘗試 Lasso 或 ElasticNet。
- 否:嘗試 Ridge Regression 或 SVR (kernel='linear')。
- 若結果不符預期,嘗試 SVR (kernel='rbf') 或 Ensemble Regressors。
- 數據量超過 10 萬筆:
非監督式學習:聚類(Clustering)
當您判斷問題為聚類問題時,首先問自己是否知道您要分類的數量有幾類別,並依據數據量選擇合適的演算法:
- 不知道要分幾類別 (數量):
- 數據量少於 1 萬筆:嘗試 MeanShift 或 VBGMM。
- 數據量多於 1 萬筆:不適用機器學習方法解決。
- 知道要分幾類別 (數量):
- 數據量少於 1 萬筆:嘗試 MiniBatch KMeans。
- 數據量超過 1 萬筆:
- 首先嘗試 KMeans。
- 若結果不符預期,嘗試 Spectral Clustering 或 Gaussian Mixture Models (GMM)。
非監督式學習:降維(Dimensionality Reduction)
當您需要進行降維時,依據數據量選擇合適的演算法:
- 首先:嘗試 Randomized PCA。
- 若結果不如預期:
- 數據量少於 1 萬筆:嘗試 Isomap 或 Spectral Embedding。
- 數據量多於 1 萬筆:嘗試 Kernel Approximation。
- 若結果仍不如預期:嘗試 LLE 方法。
結論
我們介紹了如何使用 scikit-learn 官方的 cheatsheet 來選擇適合的演算法。這個方法提供了一個很好的起點,但請記住,這只是一個基本框架。隨著 AI 技術的快速發展,新的演算法和改進版本不斷出現。本章節列舉了一些演算法名稱,但尚未深入介紹它們的特性與適用場景,而除了上述這些,實際上也還有許多其他方法可供選擇。在實際應用中,嘗試不同的演算法往往是必要的。
在 2019 年實習時,筆者的主管常說:「當你開始做機器學習回歸演算法時,第一個要嘗試的永遠都是線性回歸模型。即使它不一定是最佳選擇,但它能幫助我們理解特徵之間的關係,也是理解更複雜演算法的好起點。」因此,筆者至今仍會在每一次的回歸問題中先用線性回歸試試。這不僅是一種習慣,也是一種學習和理解數據的方法。在後續的文章中,我們將詳細介紹一些常見的演算法,探討它們的原理、優缺點以及應用場景。這將幫助你在實際問題中更好地選擇和應用這些演算法。
參考資料:
https://scikit-learn.org/stable/machine_learning_map.html
https://howtolearnmachinelearning.com/articles/what-is-scikit-learn/


 iThome鐵人賽
iThome鐵人賽