簡介
Scikit-learn 的 cheatsheet 中列舉了多種常用的機器學習演算法,涵蓋了分類、回歸、聚類和降維等多個領域。理解每種演算法的特性和適用情境,將有助於我們在面對不同的數據和需求時,能夠選擇最合適的工具進行建模。在接下來的四篇文章中,我們將詳細介紹這些演算法,包括:
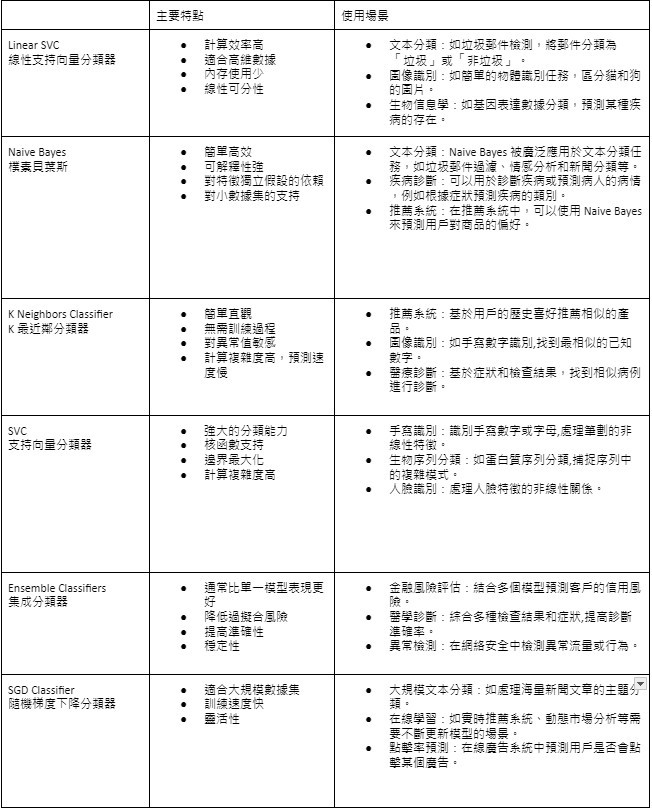
- 分類算法:Linear SVC、Naive Bayes、K Neighbors Classifier、SVC、Ensemble Classifiers、SGD Classifier
- 回歸算法:Lasso、ElasticNet、Ridge Regression、SVR、Ensemble Regressors、SGD Regressor
- 聚類算法:MeanShift、VBGMM、MiniBatch KMeans、KMeans、Spectral Clustering、Gaussian Mixture Models (GMM)
- 降維算法:Randomized PCA、Isomap、Spectral Embedding、Kernel Approximation、LLE
對於每種演算法,我們將從以下幾個方面進行介紹:
- 基本原理:簡要說明演算法的核心思想
- 注意事項:提醒使用該演算法時需要注意的問題
其中會將主要特點及使用場景整理成表格圖供比較。
通過這篇文章,我們希望能夠幫助大家更好地理解 scikit-learn cheatsheet 中的各種演算法,為後續的實際應用打下堅實的基礎。讓我們開始這段深入淺出的機器學習演算法探索之旅吧!
Cheatsheet 中的演算法介紹- 分類
分類是機器學習中最常見的任務之一,它的目標是將輸入數據分配到預定義的類別中。讓我們來看看這些強大的分類器:
- Linear SVC(線性支持向量分類器)
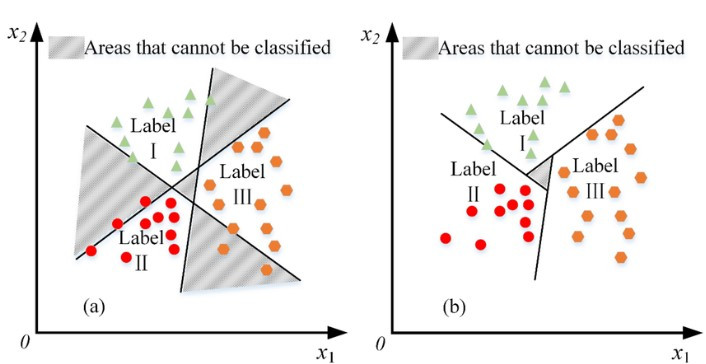
- 基本原理:Linear SVC 是一種線性分類器,其主要目的是尋找一條最佳的線(在二維空間中)或一個超平面(在更高維空間中)來將不同類別的數據點分開。這條線或超平面不僅要能夠分隔開不同的類別,還要最大化類別之間的間隔,以提高分類器對未知數據的泛化能力。具體來說,Linear SVC 會選擇使得邊界最寬的分隔線或超平面。例如,假設我們有三種類別的數據點,如下圖所示:
[source]
在這種情況下,我們希望找到一條最佳的分隔線,並且這條線需要使得各類別之間的距離最大化。這樣可以確保即使在面對新的數據點時,我們也能夠做出準確的預測。
- 注意事項:
- 對outliers較為敏感:異常值可能顯著影響決策邊界的位置。
- 對於非線性可分的數據集,Linear SVC 的性能可能會下降。在這種情況下,可以考慮使用非線性支持向量機或其他更適合的分類器。
- 當要優化模型而進行參數調整時,可能會需要額外的計算資源和時間來尋找最佳參數。
- 需要對特徵進行標準化:確保所有特徵在相同的尺度上,避免某些特徵主導分類結果。
- Naive Bayes(樸素貝葉斯)
- 基本原理:Naive Bayes 是基於貝葉斯定理的簡單機率分類器。它的基本思想是,對於每個待分類的樣本,我們計算它屬於每個類別的機率,然後選擇機率最高的類別作為最終的預測結果。Naive Bayes 的「樸素」之處在於它假設特徵之間是條件獨立的,即每個特徵對於給定類別的貢獻是獨立的,這大大簡化了計算過程。
- 注意事項:
- 特徵獨立假設的限制:在特徵高度相關的情況下,Naive Bayes 的性能可能會受到影響。雖然獨立假設簡化了計算,但實際數據中的特徵往往不是完全獨立的。
- 對缺失數據較為敏感:需要合理處理缺失值,否則可能影響分類結果。
- 數據平滑:當某些類別的特徵在訓練數據中未出現時,可能會遇到機率為零的問題。這種情況下,可以使用拉普拉斯平滑(Laplace smoothing)來解決。
- 適合於線性分類:Naive Bayes 特別適合處理線性分類問題,但在某些複雜的非線性問題上可能效果不佳。
- K Neighbors Classifier(K 最近鄰分類器)
K Neighbors Classifier 有時也被稱為 K-Nearest Neighbors (KNN)算法,這兩個名稱指的是同一個核心概念: 通過查找最接近的 K 個鄰居來進行分類或回歸。"K-Nearest Neighbors (KNN)" 是一個更通用的術語,可以指代用於分類或回歸的 KNN 算法。而 "K Neighbors Classifier" 更明確地指出這是一個用於分類任務的 KNN 實現。scikit-learn 庫中使用 "KNeighborsClassifier" 作為分類器的名稱,對於回歸任務,scikit-learn 則使用 "KNeighborsRegressor"。
- 基本原理:K Neighbors Classifier 是一種基於實例的學習方法,它通過測量數據點之間的距離來進行分類。這個方法的核心思想是:給定一個待分類的數據點,我們查找訓練集中與該數據點距離最近的 K 個鄰居,然後根據這些鄰居的類別來進行預測。它不需要訓練過程,而是在預測時直接計算距離。最常見的距離度量是歐氏距離(Euclidean distance),但也可以使用其他距離度量方法。具體來說,K Neighbors Classifier 的分類步驟如下:
選擇鄰居:選擇與待分類數據點距離最近的 K 個數據點。
投票決策:根據這 K 個鄰居的類別進行投票,將待分類數據點分配給投票最多的類別。這裡可以選擇不同的投票策略,如多數投票(Majority Voting)或加權投票(Weighted Voting)
- 注意事項:
- K 值選擇:選擇合適的 K 值是 K Neighbors Classifier 的一個重要問題。K 值過小會導致模型過擬合,過大則會使模型過於平滑,從而可能忽略數據中的局部結構。常用的方法是通過交叉驗證來選擇最佳的 K 值。
- 對特徵的尺度敏感,通常需要標準化:由於 K Neighbors Classifier 基於距離進行分類,因此需要對特徵進行標準化處理,以避免某些特徵的尺度影響結果。常見的標準化方法有 Z-score 標準化和 Min-Max 正規化。
- 計算複雜度:對於大規模數據集,K Neighbors Classifier 的計算複雜度高,可能需要使用 KD-Tree 或 Ball-Tree 等資料結構來加速鄰居搜索。
- 需要大量存儲空間來保存訓練數據:因為預測時需要用到所有訓練數據。
- SVC (支持向量分類器)
- 基本原理:SVC 的基本思想是,通過將數據映射到更高維度的空間,使得在這個空間中數據點能夠被分開,與 Linear SVC 類似,只是 SVC 支持線性和非線性分類。它可以使用不同的核函數(如徑向基函數(RBF)核、多項式核等)將數據映射到更高維度的空間,以處理非線性問題。這使得 SVC 能夠解決複雜的分類問題,特別是當數據在原始空間中不可線性分隔時。具體來說,SVC 的分類過程可以分為以下幾個步驟:
選擇超平面:在原始空間中,選擇一個超平面來分隔數據點。這個超平面需要滿足最大化類別之間的間隔(Margin)的條件。
數據映射:如果數據在原始空間中無法被線性分開,SVC 會使用核函數(Kernel Function)將數據映射到更高維度的空間,使得在這個新空間中數據點可以被線性分開。
支持向量:支持向量是距離分隔超平面最近的數據點。SVC 模型主要依賴這些支持向量進行分類,支持向量確定了分類邊界的位置。
- 注意事項:
- 選擇核函數:選擇合適的核函數對於 SVC 的性能至關重要。不同的核函數適合不同的數據特徵和問題類型。通常需要通過交叉驗證來選擇最佳的核函數和其參數。
- 對大規模數據集不太適用:SVC 在處理大規模數據集時可能需要較高的計算資源,尤其在計算核矩陣可能很耗時。對於非常大的數據集,因為計算複雜度隨樣本數量快速增長,可以考慮使用線性支持向量機(Linear SVM)或其他優化技術來提高計算效率。
- Ensemble Classifiers(集成分類器)
- 基本原理:集成分類器(Ensemble Classifiers)通過結合多個基礎模型來提高預測性能。集成方法的核心思想是利用多個模型的優勢來彌補單一模型的不足,最終得到比任何單一模型更強的分類性能。例如,在一個醫療診斷系統中,我們可能結合多個專家(分類器)的意見。每個專家根據不同的症狀和檢查結果給出診斷,最後系統綜合所有專家的意見得出最終診斷結果。集成分類器通常基於以下幾種方法進行模型融合:
Bagging(Bootstrap Aggregating):
- 方法:通過從訓練數據集中隨機抽取若干個樣本子集(有放回抽樣),訓練多個基礎模型。每個基礎模型在不同的數據子集上進行訓練,最後將所有模型的預測結果進行平均(對於回歸)或投票(對於分類),以獲得最終預測結果。
- 優勢:能夠降低模型的方差,減少過擬合的風險。
Boosting:
- 方法:以序列的方式訓練一系列基礎模型,每個模型的訓練過程中會重點關注前一個模型中預測錯誤的樣本。最終,所有基礎模型的預測結果按照一定的權重進行加權,以獲得最終預測結果。
- 優勢:能夠提高模型的準確性,尤其在處理不平衡數據集時效果良好。
Stacking(Stacked Generalization):
- 方法:將多個不同的基礎模型進行訓練,然後用這些模型的預測結果作為新特徵來訓練一個更高層次的模型(稱為元模型)。最終,元模型會基於這些基礎模型的預測結果給出最終預測。
- 優勢:能夠結合不同模型的優勢,充分利用各模型的特點。
以下是一些常見的集成分類器:
- SGD Classifier (隨機梯度下降分類器)
結論
無論是處理簡單的線性分類問題,還是面對複雜的非線性數據,我們都能夠依賴這些強大的工具來實現精確的預測。未來的文章中,我們將繼續探討 scikit-learn cheatsheet 中其他重要的演算法,涵蓋回歸、聚類和降維等領域。希望通過這一系列的介紹,能夠幫助大家在機器學習的旅程中,選擇和應用最合適的演算法,提升模型的性能和應用效果。


 iThome鐵人賽
iThome鐵人賽