今天我們要介紹的是詞頻統計bag of words(bow),tf-idf,vec2word。
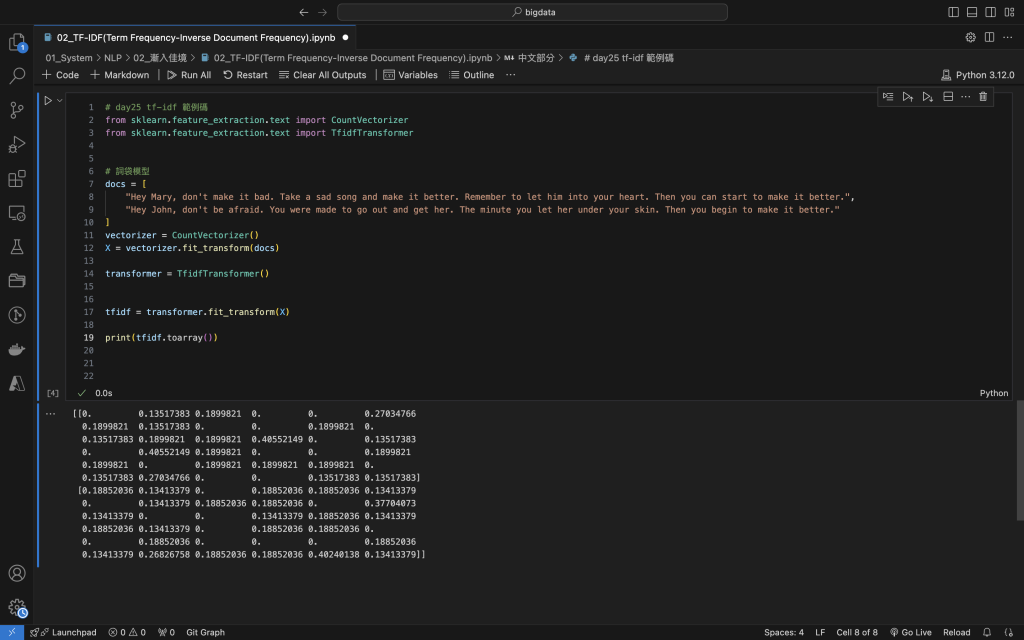
from sklearn.feature_extraction.text import CountVectorizer
# 詞袋模型
docs = [
"Hey Mary, don't make it bad. Take a sad song and make it better. Remember to let him into your heart. Then you can start to make it better.",
"Hey John, don't be afraid. You were made to go out and get her. The minute you let her under your skin. Then you begin to make it better."
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(docs)
載入sklearn CountVectorizer套件。
vectorize.fit_transform(docs) 模型配飾。
fit_transform 表示先 配飾fit再轉換transform。
[ hey, mary, don’t, make, it, bad, take, a, sad, song, and, better, remember, to, let, him, into, your, heart, then, you, can start] 對應的向量就是
[1, 1, 1, 3, 3, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
-(23個詞組向量)
第二段文件
[ hey, mary, don’t, be, afraid, you, were, made, to, go, out. and, get, her, the, minute, let, under, your, skin, then, begin, make, it, better]對應的向量就是
[1, 1, 1, 1, 1, 3, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]-(25個詞組向量)
tf-idf = tf x idf
詞頻tf(term frequency) = \frac{該詞句在文件的出現的數量}{該文件的總辭組數}
逆向文件頻率idf (inverse document frequency) = log(\frac{該語料庫文檔總數}{包含該詞句的文章個數 +1})
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
# 匯入套件
from gensim.models import Word2Vec
# 英文文本
sentences = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 向量維度
vector_size = 100 ## 1 token 100 dime
model = Word2Vec(
sentences,
vector_size = vector_size
)
在此補上我們提過的label encoding 和 one hot encoding:
概念很簡單:label encoding 就是假如我們現在有三原色(紅黃藍)要編碼,(忘記的同學可以到day18看一下何謂catagory與numbers): 直覺上,是不是就是red = 0,yellow = 1,blue = 2。但是這樣會有一個問題:電腦會認為blue > yellow,但這是錯誤的,因爲catagory不能比較,這時候聰明的你是不是想到了那就用向量表示:
red = [1,0,0],yellow = [0,1,0],blue = [0,0,1],這樣資料具有識別的唯一性,也不會誤會顏色可以比較。缺點是:當我手上有上百種顏色要表示時,會產生一個巨大的稀疏矩陣,佔據電腦大量空間與計算資源,這就是one hot encoding。是不是很簡單易懂呢?
明天我們將會介紹ML的環境建置Python 與 Anaconda 安裝,敬請期待。


 iThome鐵人賽
iThome鐵人賽