今天是第29天,有沒有給自己一點獎勵呢?堅持學習了29日,給自己加加油,打氣一下!
在day21 談Kaggle的時候,我們有學到一個花朵識別iris的用random forest演算法去做預測的時後,準確度高達99%,哪時候,你心裡有沒有這樣想?這個演算法太厲害了,幾乎百分之一百,那以後不管遇到什麼datasets,就用random forest好了,保證萬無一失!且慢,且慢,不是這樣唷!資料科學家發命這麼多演算法,是有目的的喇!每一種資料集都有最適合它的演算法,而我為什麼要用random forest classifier ,不用navie bayes,分類演算法那麼多種,為什麼會選到接近百分之一百?想到了嗎?那是因為我比各位早一點學習ML的技術,知道遇到那種datasets該適合用什麼演算法,如此而已。以後你熟悉了演算法,你也可以做到?是不是很簡單呢?
現在,問題來了,random forest 演算法幾乎達到100%的正確率,您有沒有感到害怕?你可能會想,不會阿!百分之一百不是最好嗎?這個演算法真好,就用這個就好了,保證萬無一失?來先觀察以下圖片: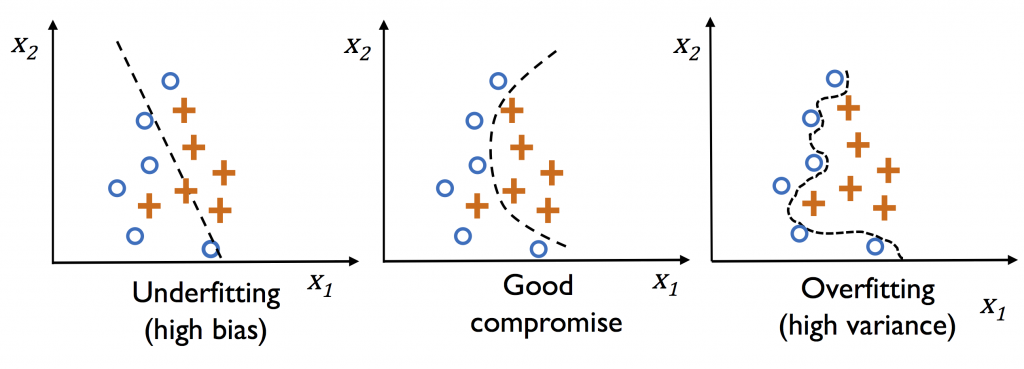
看完了以上的圖片,你有沒有覺得random forest的花朵識別的例子,正是圖片最右邊的範例!對了,你想的沒錯!正是過擬和overfitting(high variance),顯示模型的預測和實際的datasets的分佈過於吻合,這個問題該怎麼解決呢?你先想一想我們待會再解答!
想到了嗎?就是搜集更多的資料來讓模型做預測呀!對了,真聰明!其實在現實的世界,datasets得來不易,有得還要收費。那還有其他辦法嗎?沒錯!沒錯!就是降低模型的複雜度,但是,要小心不要變成最左邊的那個圖型,就是欠擬合underfitting (high bias),所以我們在做模型預測的時候,Bias and Variance trade-off ( 權衡 ),就變成我們在心中要有一把尺來衡量。
終於要到說再見的時候,明天我們將會綜合整理歸納這29日學到哪些東西,有沒有為自己又比昨天的自己進步一點,拍拍手,獎勵自己一段小旅遊呢?每天進步1%,一年後的你將強大好幾倍!敬請期待。


 iThome鐵人賽
iThome鐵人賽