
前幾天我們利用外部資料的力量,來提示LLM,並且使得LLM得到更多內容的提示生成精確的回覆,那麼今天我們打算製作一個可以讓使用者自由選擇檔案的UI介面,並且可以自由輸入分析字的文件分析器chatDocument ,目標是相容多個文件格式,首先先從CSV來示範,前端部分我們使用streamlit。
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
# 1. Create model
os.environ["OPENAI_API_KEY"] = "你的OpenAI API key"
model = ChatOpenAI(model="gpt-4o")
embeddingmodel = OpenAIEmbeddings(model="text-embedding-ada-002")
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# define process file
def process_document(file_content, user_input, file_name):
# 暫存上檔案,並且得到上傳檔案的副檔名
temp_file_path = f"temp_uploaded_file.{file_name.split('.')[-1]}"
# 寫成暫存檔案
with open(temp_file_path, "wb") as temp_file:
temp_file.write(file_content)
# 1. 載入CSV檔案
loader = CSVLoader(file_path=temp_file_path, encoding="utf-8")
docs = list(loader.lazy_load())
# 2. 切分成數個chunk,自定切割大小,自訂overlap
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
# 3. 轉換成embedding,儲存進Chroma向量資料庫
vectorstore = Chroma.from_documents(
documents=splits, embedding=embeddingmodel)
retriever = vectorstore.as_retriever()
# 4. 做成chain.
template = """
你是一個人工智慧輔助系統,可以根據文件的內容進行簡單的總結,並且根據使用者需求來進行分析
以下為文件的內容:
{context}
使用者提供的額外資訊:
{user_input}
"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "user_input": lambda x: x}
| custom_rag_prompt
| model
| StrOutputParser()
)
# 5. 呼叫
result = rag_chain.invoke(user_input)
os.remove(temp_file_path)
return result
pip install streamlit
# 將streamlit import並且使用st 作為簡稱
import streamlit as st
# 設定網頁的基本資訊,像是標題和icon。
st.set_page_config()
# 顯示網頁的主標題,有著較大的字體和明顯的行距。
st.title()
# 用來顯示一般文字或元件,也可以用來排版ex: st.write("")
st.write()
# 文件上傳工具,允許用戶上傳文件。其他屬性 type 表示可以接受的檔案類型,label_visibility="visible" 讓標籤保持可見。
st.file_uploader()
# 創建一個單行的文字輸入框,讓使用者輸入額外資訊,參數的第一個字串是提示字,第二個字串是預設字
st.text_input()
# 用來創建一個按鈕,當使用者按下此按鈕時,會觸發後續的邏輯。
st.button()
# 顯示錯誤信息,可以提醒使用者或顯示其他錯誤。
st.error()
若需要streamlit的額外資訊,可以參考官方網站
https://docs.streamlit.io/develop/tutorials/llms/llm-quickstart
# streamlit
import streamlit as st
# frontend
def run_streamlit():
st.set_page_config(
page_title="文件分析與總結器", page_icon="📄")
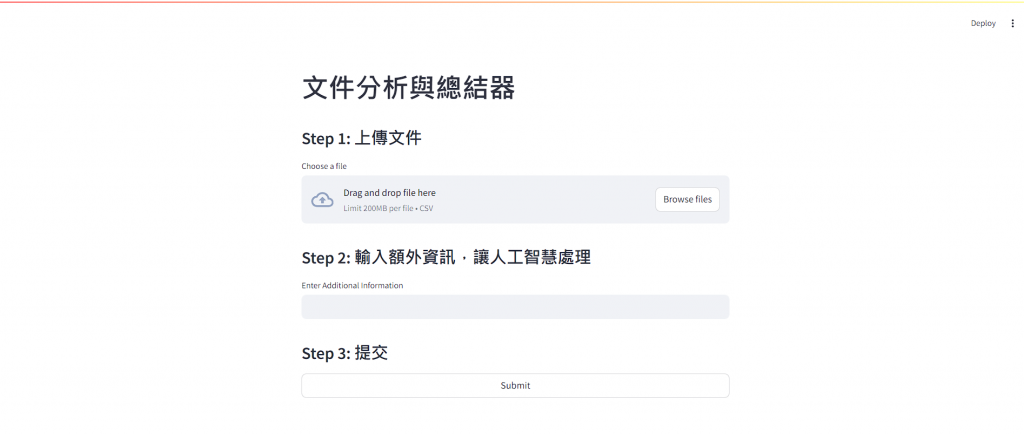
st.title("文件分析與總結器")
st.write("")
st.write("### Step 1: 上傳文件")
uploaded_file = st.file_uploader(
"Choose a file", type=["csv"], label_visibility="visible")
st.write("")
st.write("### Step 2: 輸入額外資訊,讓人工智慧處理")
user_input = st.text_input(
"Enter Additional Information", "")
st.write("")
st.write("### Step 3: 提交")
submit_button = st.button("Submit", use_container_width=True)
if submit_button:
if uploaded_file is not None:
st.write(f"**檔案名稱:** {uploaded_file.name}")
st.write(f"**額外資訊:** {user_input}")
# Process the document
file_content = uploaded_file.getvalue()
summary = process_document(
file_content, user_input, uploaded_file.name)
st.write("")
st.write("### Summary:")
st.write(summary)
else:
st.error("請先上傳檔案")
最後啟動時,執行前端頁面
if __name__ == "__main__":
run_streamlit()
執行整個程式碼輸入
streamlit run day13.py
我們將整個程式碼檔案命名為day13.py
# streamlit
import streamlit as st
# langChain
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# 啟動命令 streamlit run filename.py
# 1. Create model
os.environ["OPENAI_API_KEY"] = "你的OpenAI API key"
model = ChatOpenAI(model="gpt-4o")
embeddingmodel = OpenAIEmbeddings(model="text-embedding-ada-002")
# define process file
def process_document(file_content, user_input, file_name):
# 暫存上檔案,並且得到上傳檔案的副檔名
temp_file_path = f"temp_uploaded_file.{file_name.split('.')[-1]}"
# 寫成暫存檔案
with open(temp_file_path, "wb") as temp_file:
temp_file.write(file_content)
# 1. 載入CSV檔案
loader = CSVLoader(file_path=temp_file_path, encoding="utf-8")
docs = list(loader.lazy_load())
# 2. 切分成數個chunk,自定切割大小,自訂overlap
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
# 3. 轉換成embedding,儲存進Chroma向量資料庫
vectorstore = Chroma.from_documents(
documents=splits, embedding=embeddingmodel)
retriever = vectorstore.as_retriever()
# 4. 做成chain.
template = """
你是一個人工智慧輔助系統,可以根據文件的內容進行簡單的總結,並且根據使用者需求來進行分析
以下為文件的內容:
{context}
使用者提供的額外資訊:
{user_input}
"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "user_input": lambda x: x}
| custom_rag_prompt
| model
| StrOutputParser()
)
# 5. 呼叫
result = rag_chain.invoke(user_input)
os.remove(temp_file_path)
return result
# frontend
def run_streamlit():
st.set_page_config(
page_title="文件分析與總結器", page_icon="📄")
st.title("文件分析與總結器")
st.write("")
st.write("### Step 1: 上傳文件")
uploaded_file = st.file_uploader(
"Choose a file", type=["csv"], label_visibility="visible")
st.write("")
st.write("### Step 2: 輸入額外資訊,讓人工智慧處理")
user_input = st.text_input(
"Enter Additional Information", "")
st.write("")
st.write("### Step 3: 提交")
submit_button = st.button("Submit", use_container_width=True)
if submit_button:
if uploaded_file is not None:
st.write(f"**檔案名稱:** {uploaded_file.name}")
st.write(f"**額外資訊:** {user_input}")
# Process the document
file_content = uploaded_file.getvalue()
summary = process_document(
file_content, user_input, uploaded_file.name)
st.write("")
st.write("### Summary:")
st.write(summary)
else:
st.error("請先上傳檔案")
if __name__ == "__main__":
run_streamlit()
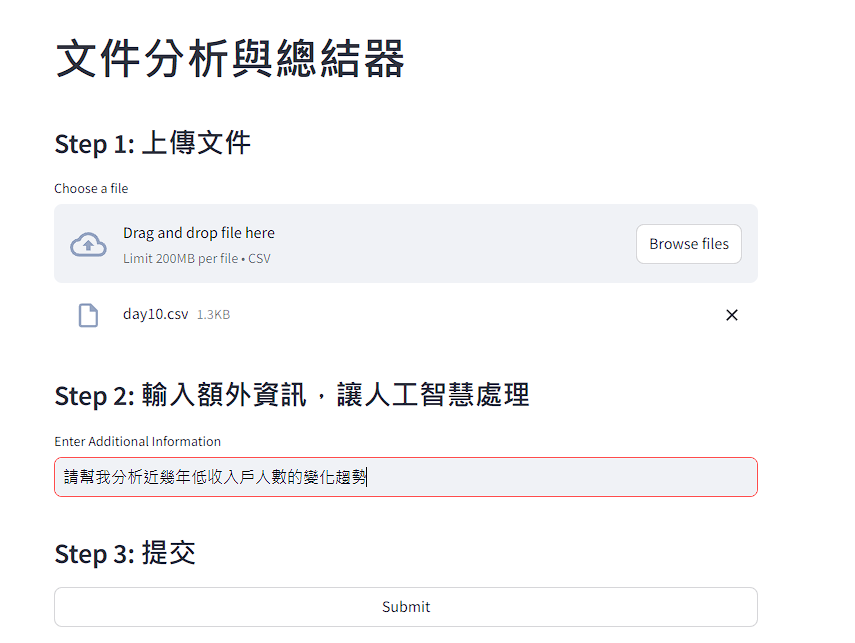
接著按下執行,結果得到回應


 iThome鐵人賽
iThome鐵人賽