
要跟LLM好好溝通之前, 有幾個專有名詞要好好認識一下如下圖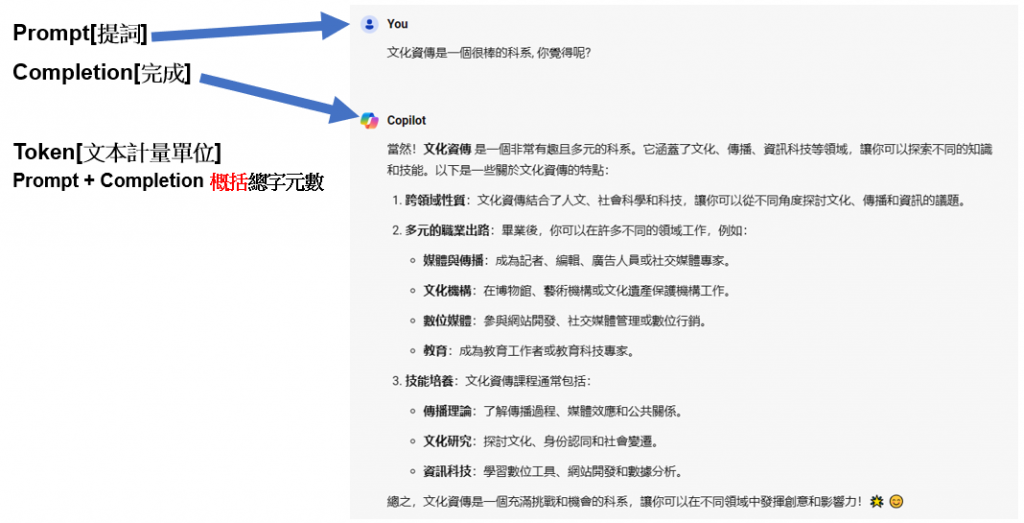
Prompt: 是指用來引導大型語言模型(LLM)生成回應的輸入文字. 當你向LLM輸入一個問題或指令時, 這個輸入文字就被稱為Prompt, Prompt的設計和內容會直接影響LLM生成的回應品質和正確性.
Completion 是指LLM根據Prompt生成的回應. 當你輸入Prompt後, LLM會根據其內部的模型和數據生成相應的回應, 這個回應就被稱為Completion。Completion的品質和正確性取決於Prompt的設計以及LLM的能力。
簡單來說Prompt就是Input text; Complete就是Output text, 而Prompt寫得好不好, 會影響Completion的結果.
Token: 是指在自然語言處理(NLP)中,將文字資料分割成較小單位的過程。這些較小單位可以是單詞或是字元。每個 token 都代表一個獨立的語言單位. 在Day04, 我們有介紹到Transformer Explainer, 在第一個部分就有提到Transformer會將單詞或是字元轉成token. 但是要特別注意的是一個字並不是一定是一個Token. 在Open AI網站上(https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them) 有提到換算規則如下
1 Token 約等於英文 4 個字元
1 Token 約等於 ¾ 個單字
100 Tokens 約等於 75 個單字
或是
1~2 句話約等於 30 Tokens
1 段文字約等於 100 Tokens
1500 個單字約等於 2480 Tokens
另外LLM也有Token的上限, 舉例如下
GTP 3.5 4,000 Tokens
GTP 4o 128,000 Tokens
128k Tokens相當於A4書本300頁左右的文字內容
若對Token的計算還是覺得很抽象, Open AI也很貼心提供了Tokenizer ( https://platform.openai.com/tokenizer )如下, 可以更直觀理解如何換算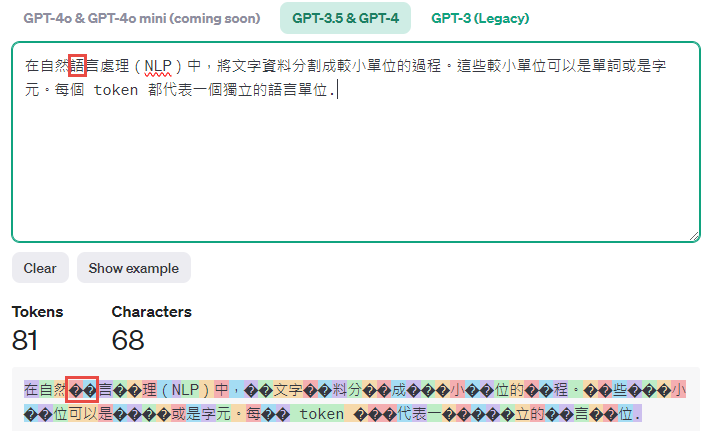
由上圖可以發現”語”這個字由兩個??代表即2個Token. 而Token則是現在閉源LLM的計費方式, 所以想要自行開發LLM應用服務, 控制好Token是眉角中眉角, 以Azure Open AI為例如下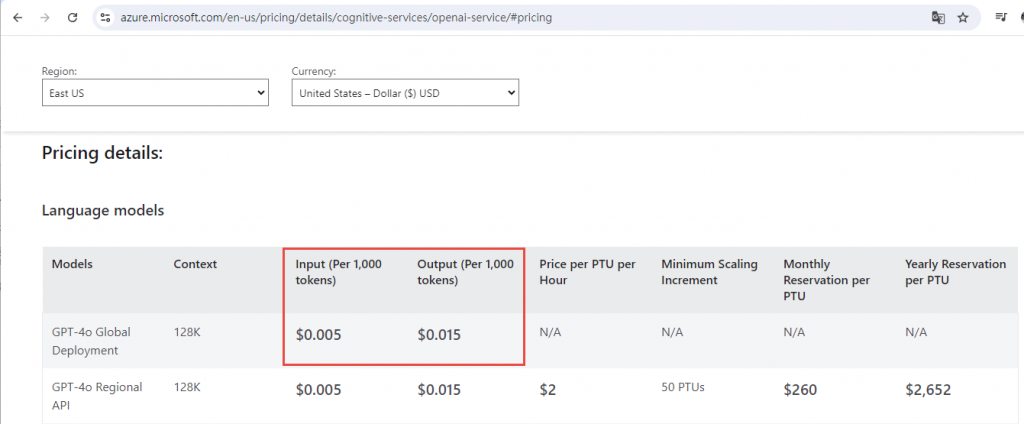
1百萬的Token大概是美金20塊, 如果Prompt寫得不好, 讓產出的結果是垃圾, 那就是在燒錢, 若又沒有好好控制, 那就是越燒越多錢了.
那要如何寫出好的Prompt與LLM溝通? 有江湖流傳的4S規則如下
• 單一目的(Single):專注於單一且明確的任務或問題.
• 具體(Specific):使用精確且詳細的指示.
• 簡短(Short):保持指示簡潔, 太多廢話與贅詞會對LLM造成負擔.
• 完整上下文(Surround):提供豐富的上下文, 簡單來說就是有前情提要.
筆者將4S擴充如下心法給大家參考, 之後有實例來印證這些心法
最重要的是AI真的不會通靈, 要給它充足且正確的資訊, 得到的結果才會越正確!

https://www.facebook.com/groups/818139776290690
今年弄了個專頁, 歡迎加入討論, 可以收到貼文的更新通知


 iThome鐵人賽
iThome鐵人賽