
這篇再來聊聊LLM的本質, 在Day02有提到LLM透過Transformer用大量的文字訓練出來的, Transformer會在向量的空間中找出相似的字或詞, 這個聽起來很抽象, 簡單的來說收集網路大量的文字資料如下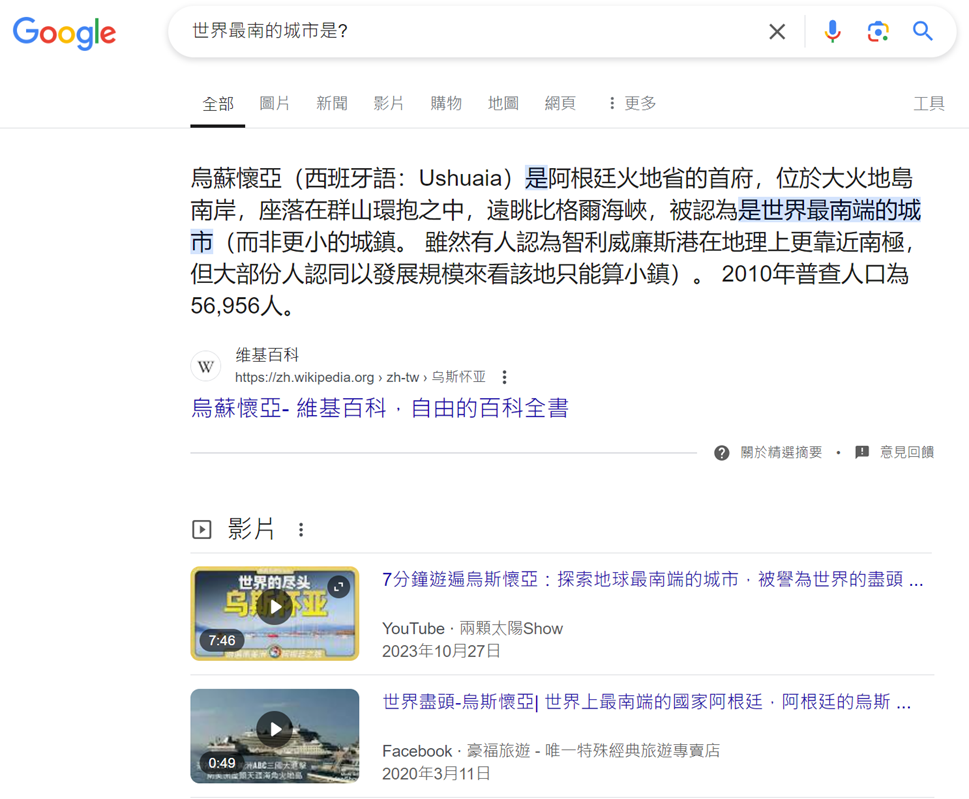
而LLM推論的過程如下
Round1: 世界最南的城市是?
Round2: 世界最南的城市是? 烏
Round3: 世界最南的城市是? 烏蘇
Round4: 世界最南的城市是? 烏蘇懷
Round5: 世界最南的城市是? 烏蘇懷亞
所以常有人說, LLM的本質就是文字接龍, 而且每一回合都會將前一回合的文字加上這一回合的文字再傳回去給LLM做推論, 這也是所謂的上下文(Context), 這個對LLM來說非常重要, 它是用來作為產生文字的依據.
最近有大神發表了Transformer可視化解釋工具即Transformer Explainer如下
https://github.com/poloclub/transformer-explainer
真的是非常酷炫, 可以用來理解Transformer的運作原理, 不再是硬核的數學方程式, 截圖如下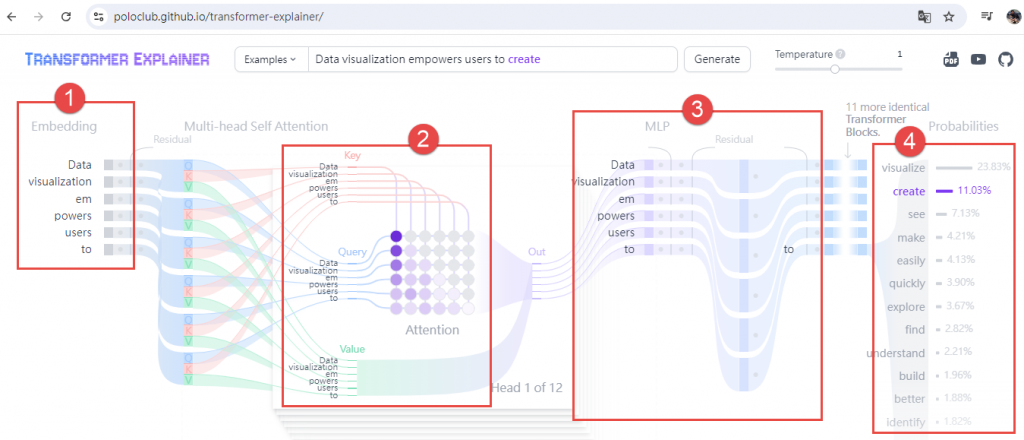
https://poloclub.github.io/transformer-explainer/
就來簡單說明一下:
第一個部分是將文字轉換為可以用來表示它們的字詞向量即Embedding, 每一個單詞或字稱為tokens, 展開之後如下圖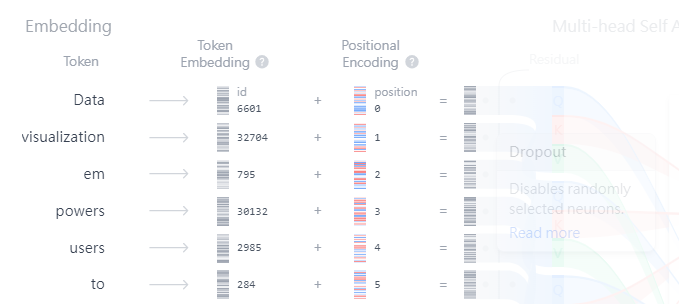
第二個部分是最關鍵的部分, 透過Query, Key與Value去找出字詞位置間的相對關係類似於空間定位概念, 就是輸入Embedding(query)、和Embedding(key)所有位置比對、用比對結果加權Embedding(value), 這也是Day02提到GPT的Embedding搜索應用
第三個部分是透過神經網路運算萃取特徵值
第四個部分透過Softmax得到輸出字詞機率如下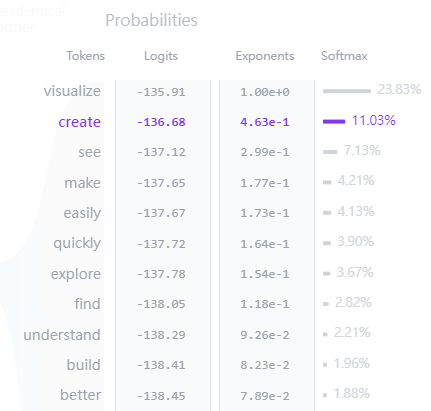
Transformer Explainer真的是為我們輕易地解開LLM的黑盒子啊

https://www.facebook.com/groups/818139776290690
今年弄了個專頁, 歡迎加入討論, 可以收到貼文的更新通知


 iThome鐵人賽
iThome鐵人賽