非監督式學習是機器學習中的一種關鍵技術,大家還記得前兩天提到的監督式學習嗎? 非監督式學習就是跟他相反的,它不依賴於事先標記的訓練範例來進行學習。這種學習方法允許演算法自動發現和學習輸入資料中的模式和結構。非監督式學習的應用範圍廣泛,包括聚類分析、異常檢測、關聯規則學習和降維等。這些技術可以幫助識別數據集中的自然分組,發現異常行為,或者簡化數據以便於進一步分析。例如,非監督式學習可以用於客戶細分,以識別具有相似購買行為的客戶群體,或者在生物資訊學中,用於基因表達資料的分類。
為了方便大家知道監督式學習跟非監督式學習的差異,我將其幾個比較常見的定義及差異整理成表格,讓大家可以更直觀的發下他們的不同。
| 特徵 | 監督式學習 | 非監督式學習 |
|---|---|---|
| 定義 | 使用標註好的資料來訓練模型 | 使用無標註的數據來發現內部結構 |
| 目標 | 預測標籤或輸出 | 發現資料中的模式和結構 |
| 資料要求 | 標註好的資料集 (輸入-輸出對) | 無標註的數據集 |
| 輸出 | 預測結果(分類標籤或連續值) | 群集標籤、關聯規則或降維後的特徵 |
| 優點 | 可以精確預測 - 適合處理複雜問題 | 可處理無標註資料 - 有助於資料探索 |
| 缺點 | 需要大量標註資料 - 標註成本高 | 無法直接預測標籤 - 有時需要先進技術解析 |
還記得在監督式學習中有分成兩個演算法,一個是迴歸另一個是分類嗎? 同樣的,在非監督式學習也可以分成幾個,常見的功能可分為分群(Clustering)、關聯(Association)與降維(Dimension Reduction),今天會簡單介紹非監督式學習的常見演算法。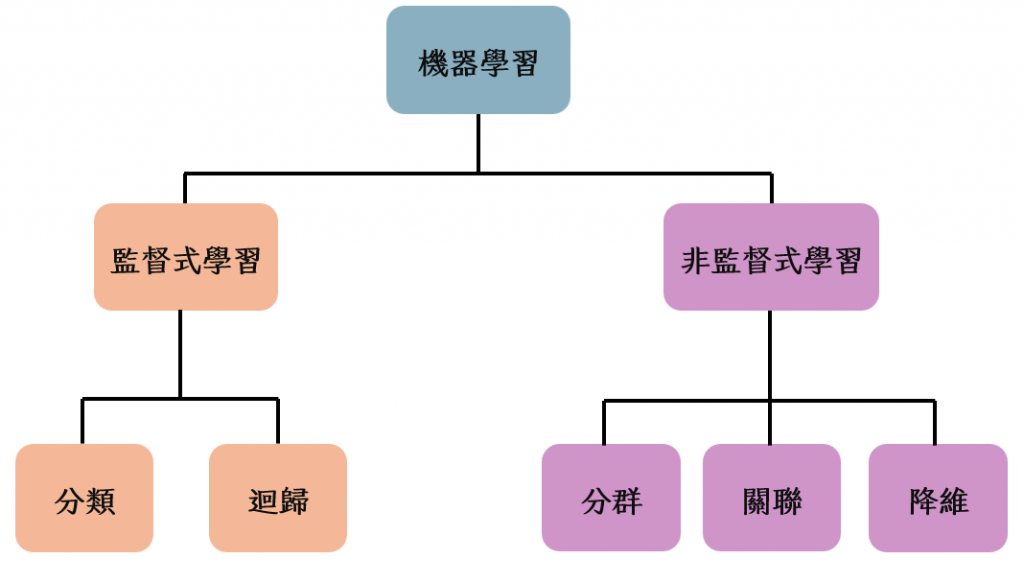
分群(Clustering),分群就是將資料依據其內部的相似性分成不同的群集。常見的算法有:
接著是關聯(Association),關聯則是從資料集中找出項目之間的關聯規則。常見的算法有:
降維(Dimension Reduction)是指將高維資料轉換為低維資料,同時保留資料的主要訊息。簡單來說就是將資料壓縮,減少計算的資源。
常見的算法有:
以上這些就是非監督式學習中常見的分群、關聯與降維演算法的簡單介紹。選擇合適的算法取決於資料的特性和具體應用需求。
以下是一些常見的應用案例及這些算法的使用時機。
分群(Clustering)應用案例:
關聯(Association)應用案例:
非監督式學習技術在許多領域都有廣泛的應用。選擇合適的算法需要根據資料特性和具體應用需求來決定。無論是分群、關聯還是降維,每種算法都有其特定的使用場景和優勢。通過合理應用這些技術,可以從無標籤資料中挖掘出有價值的訊息,提升決策和預測的準確性。


 iThome鐵人賽
iThome鐵人賽