在前幾天我們提到過監督式學習及非監督式學習,也都有提到過他們各自的優點及缺點,那這時候我們可以想想,如果可以將兩個結合起來是不是可以表現的更好勒?讓我一起往下面得文章看下去吧!!
半監督式學習 (Semi-Supervised Learning) 是一種機器學習方法,介於監督式學習和無監督式學習之間。它利用了監督式學習的特性(全部資料有標籤)和非監督式學習的特行(全部資料沒有標籤)的結合來改進模型的學習效果。因為通常有標籤的資料的獲取成本較高,而沒有標籤的資料的獲取相對容易。因此,半監督式學習能夠充分利用大量沒有標籤的資料來提高模型的性能,尤其是在有標籤的資料稀缺的情況下。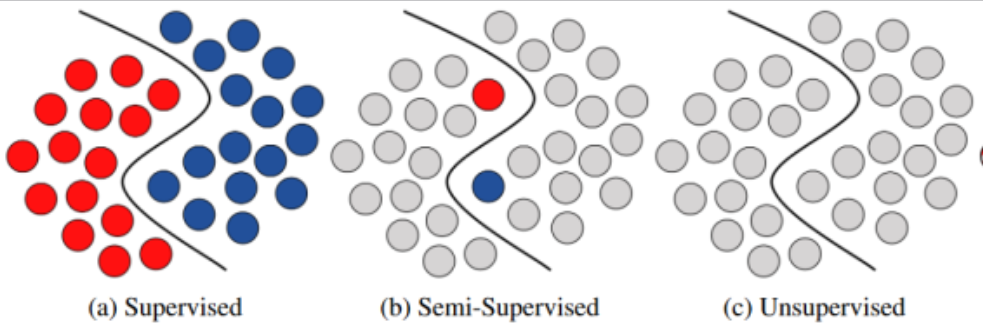
半監督式學習利用少量有標籤的資料和大量沒有標籤的資料進行訓練。其基本思路是首先利用有標籤的資料來建立初步模型,然後利用沒有標籤的資料進行模型的改進。這種方法可以通過以下幾種策略來實現:
自我訓練 (Self-Training):
協同訓練 (Co-Training):
生成模型 (Generative Models):
圖形模型 (Graph-Based Models):
在眾多的半監督學習方法中,Self-Training 是一種經典的技術。它基於模型的自我改進,不斷利用模型本身的預測結果來增強學習效果,在半監督式學習中,Self-Training 類的方法雖然常見,但存在一些局限性,特別是需要符合 Low-Density Separation 假設才能有效。這意味著模型能夠在低密度區域(數據點較少的區域)做出較為準確的分類。然而,實際應用中很多任務無法完全符合這一假設,因此 Self-Training 可能並不總是適用。
那什麼又是Low-Density Separation呢?
具體來說,Low-Density Separation 假設要求:


 iThome鐵人賽
iThome鐵人賽