壓榨硬體系列的技術,這章要來提到大魔王FlashAttention!👾
雖然它也是Attention演算法上的改進 🔄,不過它的初衷也是為了改善硬體設備的bottleneck,因此也被算在 系統/硬體層面最佳化 (System-level / Hardware-Level Optimization) 當中 🖥️⚙️。
這是筆者看最久的一章,FlashAttention-1到3的演化一篇比一篇難(っ °Д °;)っ

(圖源: makeameme)
昨天的文章中有稍稍提到不同設備之間的傳輸頻寬並不相同,而在GPU的組成中,記憶體其實也被分成了很多種,其中與FlashAttention有關的是以下兩種:
在GPU的Global Memory上通常會使用HBM當成主要的儲存空間,容量通常是幾十GB,也就是大家常常拿來存模型參數和KV Cache的VRAM。
SRAM算是GPU計算單元內部的快取記憶體(如L1 and L2 Caches),它的速度極快,但容量非常少,如下圖可見約20 MB。因為SRAM比HBM更接近GPU的計算核心,所以傳輸速度比HBM要快得多。
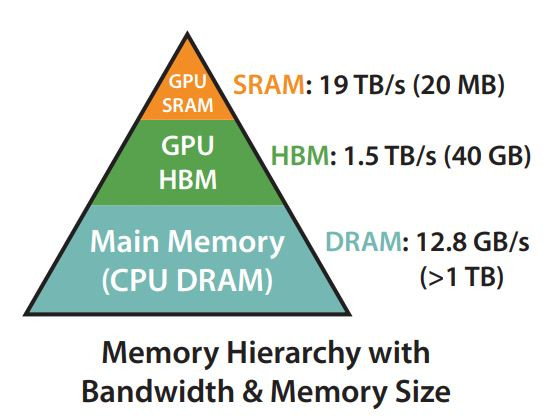
(圖源: 論文 (Dao et al., 2022))
Day6 時提到的重要觀念,在Transformer模型中,Self-Attention為了計算輸入序列中每個token與其他tokens之間的關聯性,會導致計算的複雜度隨著輸入長度以平方級增加,也就是有 O(n^2) 的時間複雜度,對於LLM長序列的輸入,除了很慢之外還超級耗記憶體。
傳統的Self-Attention計算包含四步驟,在計算了Query, Key, Value之後:
S = QK^T。S 進行 softmax 操作,得到矩陣 P。P 和 Value 矩陣,進行矩陣乘法 O = PV。O。然而,這個過程中的兩個瓶頸 🍾 在於:
且最糟糕的是,過程中所有的資料載入都是在HBM上 📂:

(圖源: 論文 (Dao et al., 2022))
在GPU的計算中,資料從HBM加載到計算單元進行處理,需要頻繁的資料移動 🔄。然而,HBM的傳輸延遲較高,頻繁讀寫HBM會導致計算效率的降低 🐢。相較之下,SRAM雖然容量小,但傳輸速度非常快......
💡 那就減少對HBM的頻繁讀取就好了啊!
如果可以充分利用SRAM,就能夠大幅提升計算效率了。 🚀🚀
FlashAttention 1由Dao等人在2022年提出,他們重新設計了Self-Attention的計算過程,在必要時才用HBM,大部分資料處理都在SRAM中進行,讓整體的效率更好。
Kernel Fusion
Tiling
原本注意力機制會有的大型矩陣計算問題。Tiling將Attention計算拆成更小的block,在每個block內做Softmax計算,最後再將結果合併。
這邊將資料放在SRAM中處理,而不是一次將整個Self-Attention矩陣存在HBM裡面。充分利用SRAM的高速資料傳輸特性,以減少HBM的資料傳輸。
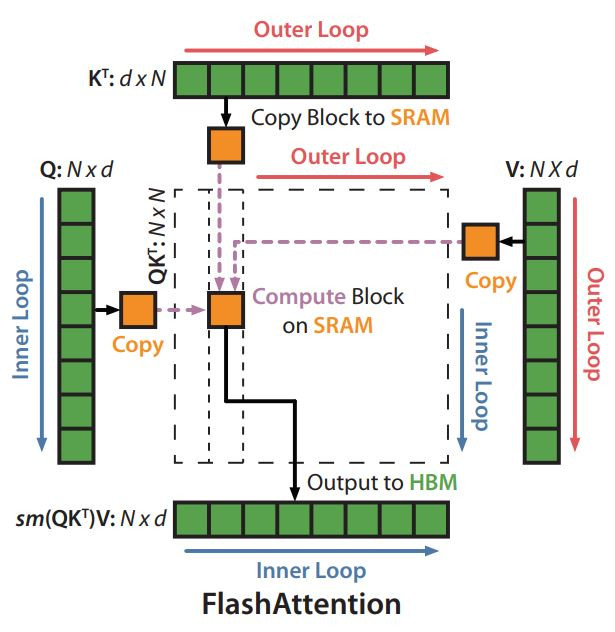
(圖源: 論文 (Dao et al., 2022))
Recomputation
雖然在論文中的主要速度計算是以訓練為主,不過也有提到FlashAttention-1能夠在相同硬體環境下,將GPT-2的context length增加到4倍,在增加序列長度的同時保持模型的準確性。
在FlashAttention-1的基礎上,FlashAttention-2更進一步優化了Self-Attention的計算流程。
Algorithm
Parallelism
Work Partitioning Between Warps
𝑑和設備的shared memory大小,調整FlashAttention-1當中Tiling的block size,進一步提升了計算效率。看到這裡時可能會有點累了,但......再撐一下就結束了! 💪
FlashAttention-3是目前最新的版本,特別針對新一代硬體Hopper GPU進行了優化。FlashAttention-2在H100 GPU上僅達到了35%的使用率,而FlashAttention-3採用了三大技術來提升性能:
Warp-specialization 和 Pingpong Scheduling

Intra-warpgroup overlapping GEMMs and softmax
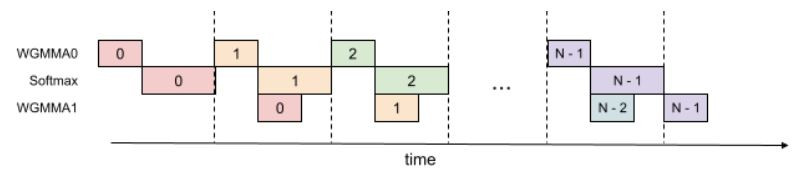
Low-precision with FP8
這些技術讓FlashAttention-3在H100 GPU上的FP16計算速度提高了1.5-2倍,達到75%的硬體使用率。另外,Hopper GPU是CUDA Compute Capability 9.x,可以參考 Day5 的整理。
由於整系列的演算法十分複雜,如果有非常熱情的讀者想要深入研究,筆者看到兩位大神的文章有將整個演算法介紹的超詳細,這邊附上給有興趣的讀者們參考。
如果忘記的人可以先複習一下Self-attention系列。
這篇對1怎麼做切小塊的softmax計算寫得簡單好懂!
如果想更了解FlashAttention-1,可以閱讀它。
這篇從1-3的所有改進方法都寫得超級詳細,搭配論文看,可以感覺作者研究了非常久!推薦所有讀者睡前閱讀,可以感受到腦袋被壓榨的感覺。
如果覺得筆者Day15寫得過於簡潔,希望可以深入研究的話,非常推薦閱讀這一篇。
整體而言,FlashAttention的設計用在訓練上面的效果理論上可以比推理更明顯 📈。然而,FlashAttention-1的改進也提升了LLM推理的效果,特別是在長序列的推理場景中 📜。隨後的FlashAttention-2和FlashAttention-3在此基礎上進一步優化,特別是在新型硬體設備上,表現會更加突出 ✨。
推理的使用上HuggingFace有支援1和2 🤗。
需要先查看模型是否有支援,接著針對NVIDIA或AWD硬體做安裝 🛠️,最後在模型載入時加上attn_implementation="flash_attention_2"就好囉!
不過需要注意FlashAttention-2 can only be used when the model’s dtype is fp16 or bf16.
🔍 簡單總結一下優點:
- 減少Self-Attention計算中的記憶體占用 ✅
- 提高計算速度 ⚡
- 長序列推理效果更好 📜
- 在特殊的硬體設備(Hopper GPU)上表現更佳 💻
看完這篇,這30天加速技術系列的 系統/硬體層面最佳化 (System-level / Hardware-Level Optimization) 就到此結束啦!在這幾天內我們已經看到了許多經典的硬體壓榨方法,每一種的發想原理其實都很簡單,但非常有創意,而且充滿著細節,就像是很多人類有趣的發明一樣!
明天開始是 模型/參數層面最佳化 (Model-level / Parameter-Level Optimization) 的新系列囉。
FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness
https://proceedings.neurips.cc/paper_files/paper/2022/file/67d57c32e20fd0a7a302cb81d36e40d5-Paper-Conference.pdf
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
https://arxiv.org/abs/2307.08691
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
https://arxiv.org/abs/2407.08608
Flash Attention
https://huggingface.co/docs/text-generation-inference/conceptual/flash_attention
有請GPT-4o各種幫忙QA修稿

