昨天的文章中,實現作業系統的虛擬記憶體的其中一個步驟是page swapping 🔄,也就是將記憶體裡面的部分內容與硬碟做交換,以便在實體記憶體不足時,將不常用的資料暫時存放到硬碟中。
PagedAttention參考了其中的page table 📋概念來處理KV cache,當然同樣也有研究會想著把VRAM的KV cache丟到RAM或硬碟上面。
💡 這個技術就被稱為Offloading 🚀,基本上就是把GPU的一些儲存和計算任務移到CPU上。其中可以被分成是:
Memory Offloading
- 將不常用的weights, activations, KV cache從VRAM轉移到CPU的RAM或硬碟上,減輕GPU VRAM的負擔。
Computation Offloading
- 將計算任務分配給CPU一起協助工作。
這章以探討Memory Offloading為主。由於需要與CPU頻繁交流,因此這系列的研究的重點是在GPU和CPU之間的資料傳輸延遲時間。
而使用時機則是在整體VRAM不足的情況下,尤其是單一個GPU想要使用更大型的語言模型的狀況,效果會更加明顯💥。
電腦系統是由各種記憶體空間組成的,包括CPU的DDR、GPU的GDDR/HBM和硬碟。而這些不同的儲存空間都有不同的存取頻寬 (access bandwidth),先簡單提一下,明天的文章也會需要這個觀念。
從圖片中可以看到硬碟的傳輸速度是最慢的,再來是CPU的RAM,最快的是GPU的VRAM。
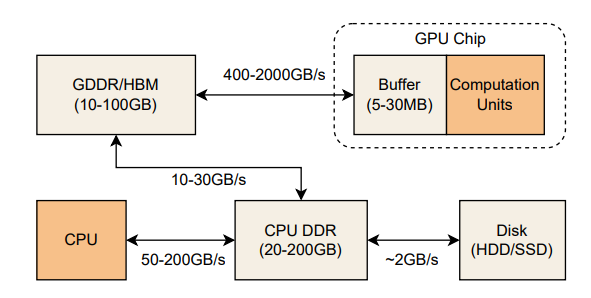
(圖源: 論文 (Yuan et al., 2024))
如果上面的圖片太複雜,FlexGen論文中的圖片會比較好懂。
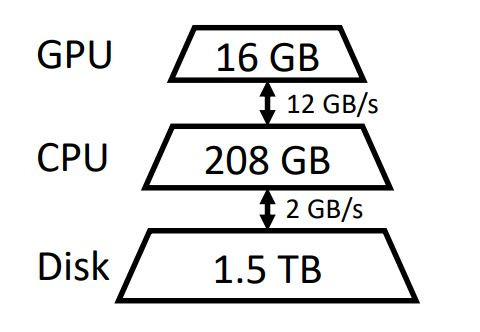
(圖源: 論文 (Sheng et al., 2023))
⚡ DeepSpeed-Inference 的 ZeRO-Inference
ZeRO-Inference主要基於DeepSpeed的ZeRO (Zero Redundancy Optimizer)原理,將模型的權重和計算分散在不同的設備上。
權重卸載 (weight offloading) 機制:
最佳化傳輸時間:
以上兩個是2022時的第一版本,在後續的版本 (DeepSpeed versions >= 0.10.3) 中,多了權重量化 (Weight Quantization) 和 KV Cache Offloading,減少記憶體空間,同時讓推理更加快速,詳細內容可以看它的Github,成功打敗了上一個版本 (version 0.1.7) 的FlexGen。
🤗 Huggingface Accelerate
Huggingface Accelerate的offload功能,相信大家可能都有用過它。其實device_map="auto"這一句就是了!
device_map="auto"可以自動將模型的不同部分分配到適當的設備上(GPU、CPU、硬碟)。如果你有多張GPU,它也會自動將模型分配到多個GPU上來加快推理速度;如果CPU有足夠的RAM,它則優先使用RAM而不是讀取速度較慢的硬碟。
🧠 FlexGen
FlexGen的Github上次commit時間真的已經是非常久之前了,目前pip install的版本是0.1.8,不過它曾經是2023當時的SOTA,打敗以上兩個2022年提出的版本,這邊也簡單介紹一下。
在這章中看到了幾個著名的offloading框架和它們的方法。雖然這是一個可以讓自己的電腦更優雅使用大型語言模型的經典方法,然而資源和資金的充裕往往可以避免使用這些offloading技術 💰。如果擁有足夠的GPU和VRAM 🖥️,或者面臨商業需求時 📊,這類offloading方法可能反而變得不太實用或必要。
另外像是ZeRO-Inference中將RAM的模型權重一層一層載入計算,這種layered inference的技術近期也有被提出一個新的框架,也就是AirLLM,它可以在8GB VRAM上運作最新的Llama3.1(405B),非常之酷炫,這對想要在自己電腦中跑超大型語言模型玩的人也是一個新的選擇!
這一章雖然沒有非常詳細的技術介紹,但提供了幾種不同選擇供讀者們參考。在更後續的章節中,筆者也會來比較其他適合在自己電腦/做成服務的推理加速框架,敬請期待XD

(圖源: 自製)
LLM Inference Unveiled: Survey and Roofline Model Insights
https://arxiv.org/pdf/2402.16363
ZeRO-Inference: Democratizing massive model inference
https://www.deepspeed.ai/2022/09/09/zero-inference.html

