前言:apply函數篇的最後一篇~今天會介紹最後的tapply函數、rapply函數、eapply函數,如果內容有哪些錯誤的地方,請多多包涵~
正文開始-->
【tapply】
一種對向量或數據依據某些分組(通常是因子)應用函數的工具。常用於將數據分組後進行彙總或計算。
語法:tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
X:向量,表示要進行操作的數據。。INDEX:一個因子或列表,指定如何將 X 進行分組。FUN:應用於每組數據的函數,如 mean、sum 等。…:其他可選的參數,將傳遞給 FUN。simplify:邏輯值,表示是否簡化結果。如果為 TRUE,則會將結果簡化為向量或數據框;否則會返回列表。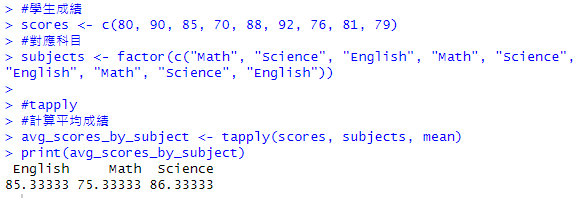
【rapply】
遞迴版的 lapply,用於遞迴地對列表的每個元素(甚至是嵌套的列表)應用函數。它可以選擇性地返回簡化結果或保持原有的嵌套結構。
語法:rapply(object, f, classes = "ANY", deflt = NULL, how = c("unlist", "replace", "list"), ...)
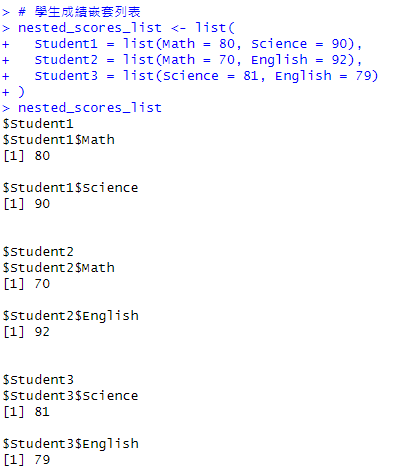
object:list資料。f:自訂的調用函數。classes:匹配類型, ANY為所有類型。deflt:非匹配類型的預設值。how:3種操作方式。
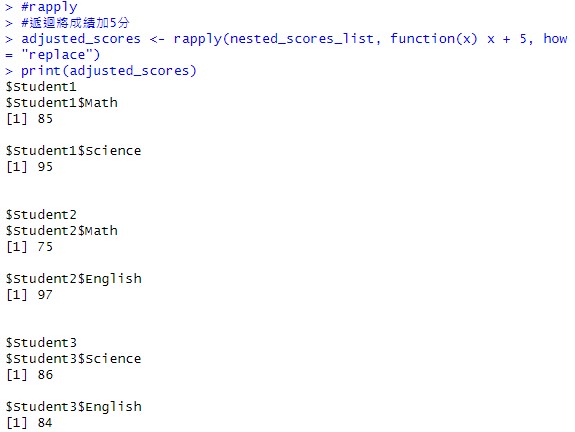
how = "replace":表替換原列表中的值。如果設為 "list",結果會返回一個新列表,保持嵌套結構。【eapply】
用於對環境中的每個對象應用函數。環境類似於 R 中的命名空間,通常包含變量和對象。適合處理某個環境中的多個對象。
語法:eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
env:環境空間。FUN:自訂的調用函數。…:更多參數,可選。all.names:匹配類型, ANY為所有類型。USE.NAMES:如果X為字串,TRUE設定字串為資料名,FALSE不設定。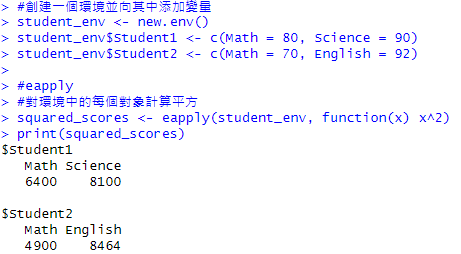
三天的apply家族函數章節結束後,最後簡述一下八個函數的定義:
apply:更適合對矩陣或陣列進行操作。lapply:則用於對清單中的每個元素進行函數應用,適合處理複雜或不規則的資料結構(如列表)。sapply:類似 lapply,但結果會自動簡化為向量或矩陣,適合處理結果類型一致的情況。。vapply:更嚴格的 sapply,需要明確指定回傳值的類型,提高程式碼安全性,適合在大規模資料處理時使用。mapply:可以同時處理多個清單或向量,適合處理需要多組輸入資料的函數呼叫。tapply:用於對向量中的數據按因子分組,應用函數。適用於分組彙總或統計。rapply:遞迴版的 lapply,用於對嵌套列表的每個元素遞迴地應用函數。適用於複雜的嵌套數據結構。eapply:用於對環境中的每個對象應用函數,適合處理環境中的數據或變量。參考:


 iThome鐵人賽
iThome鐵人賽