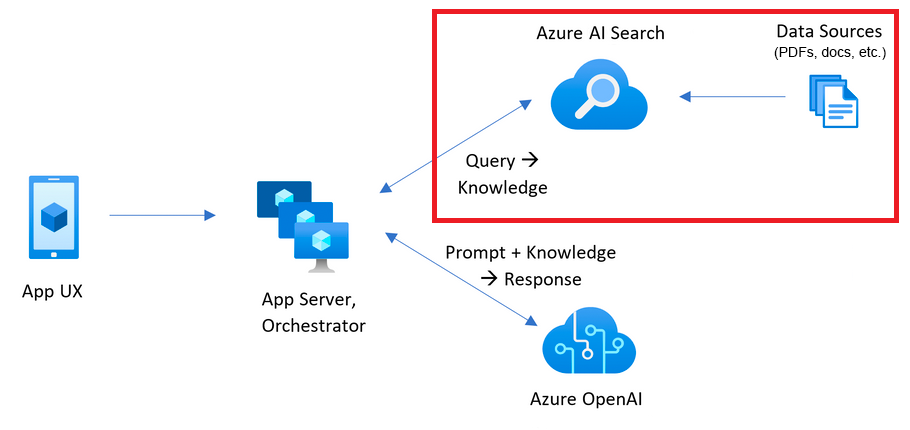
延續並更深入地討論架構圖上方的知識庫搜尋引擎,如果你是開發者或是深度使用者,也許會想知道更多READ ME上面沒寫的事,所以今天的文章會以上傳文檔並將文檔內容存入資料庫為例,分享筆者當時自己從程式碼解讀出來的程式運作流程。
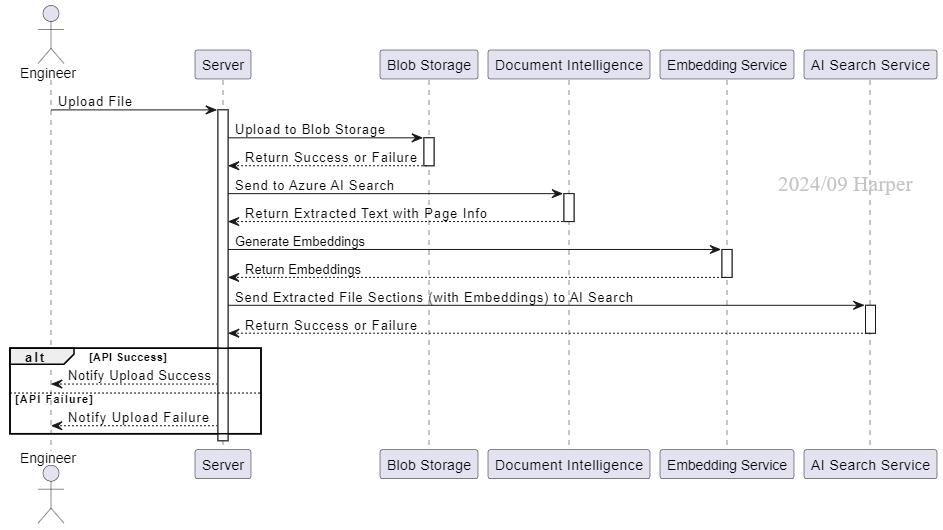
文檔上傳流程圖
從流程圖的左上角開始,你將扮演一個想要餵文檔給聊天機器人的工程師。沿著箭頭往右,把檔案送到執行程式的Server端,如果你在個人電腦執行,就是本地的應用程式。當然,也可以直接佈署上雲,讓聊天機器人完全成為雲端上的服務。
Azure Blob Storage是Azure儲存空間服務,把前一步準備好的文檔,存放在此,未來需要的時候都可以隨時來取用。
但前面的文章有說過,機器人不會像人類一樣直接閱讀文件,會需要做些轉換。首先,轉換的第一步,我們需要把各類檔案中的文字擷取出來,Azure Document Intelligence就有提供這個服務,如果是像PDF一樣,多頁式的文檔,透過這個服務,我們可以萃取出每一頁的文字,並且知道這些內文分別在哪分文檔的哪一頁。
取得文字內容之後,轉換還沒結束。此時雖然已經從各式文檔,統一格式成為相對好讀的文字了,但再多做一個關鍵步驟,可以有效提升資料查找成果,也就是將文字像量化。文字向量化,這個步驟讓資訊內容不再是人類可以閱讀的文字形式,而是以向量的方式儲存資訊,透過多組數字組成的向量,反而讓機器人可以查找到字面意義以外的相關性,進而提高搜尋成效。
有了向量化的資訊內容、儲存位置(來源文檔名稱、頁數)後,我們已經把所需的元素都消化得差不多了,接下來透過先前介紹過的Azure AI Search,把相關資訊都儲存到這個服務後,以後需要什麼資訊,就可以來到這裡,查找到對應的內容!
最後,回到流程圖的左下角,在經歷中間這些消化之旅時,有時候也可能會消化不良而導致出錯阿,所以無論檔案上傳成功與否,身為工程師,傳送成功或失敗的結果通知給自己,絕對就像飯後甜點一樣,是一餐完美的結尾。如果有開發上傳介面給使用者的話,使用者也可以透過操作介面,達成上述的檔案上傳任務,讓聊天機器人餵食秀,變得更廣為親民,家家戶戶都有機會使用。
查找資料的兩篇文章中,我們其實提到了一些特別的名詞,這些都是生成式聊天機器人的關鍵字之一,接下來我們會用一些篇幅,和大家科普一下,這些名詞到底是什麼意思。
azure-search-openai-demo
Azure Blob Storage
Azure Document Intelligence
Azure AI Search
今天提供的流程圖,是筆者挖出2023年下半年,初次使用Azure聊天機器人時的研究手稿,經過複習與查找資料後再製而成的,感謝鐵人賽的契機才能有這個機會,不過也提醒大家閱讀的同時,要注意到這個github程式是不斷地在更新改版的。希望能透過這篇分享,幫助到大家更快速地理解使用當下的程式版本內容。


 iThome鐵人賽
iThome鐵人賽