Ollama是個開源的模型管理服務,可以讓我們可以透過指令,快速地將模型部屬成可用的服務。進到Ollama官網就可以看到可愛的羊駝logo。
官網中點選Download下載,點擊自己開發環境的作業系統。在這裡我們選擇Linux,點擊後可以直接看到安裝的指令: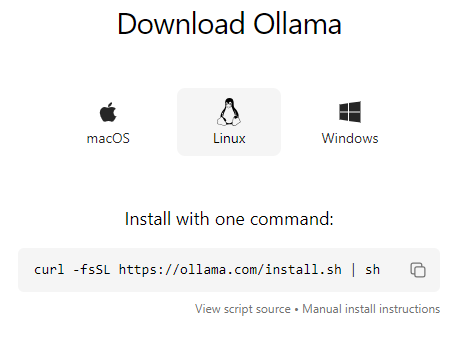
回到開發環境中的終端機,以剛才的指令安裝Ollama:
# 由於會使用到curl指令,若還沒有的話需要執行此步驟來安裝,有的話可跳過此步驟。
sudo apt install curl
# 安裝ollama
curl -fsSL https://ollama.com/install.sh | sh
安裝完Ollama,接著來選擇想要下載的模型吧,在Ollama官網的Model頁面可以看到模型列表: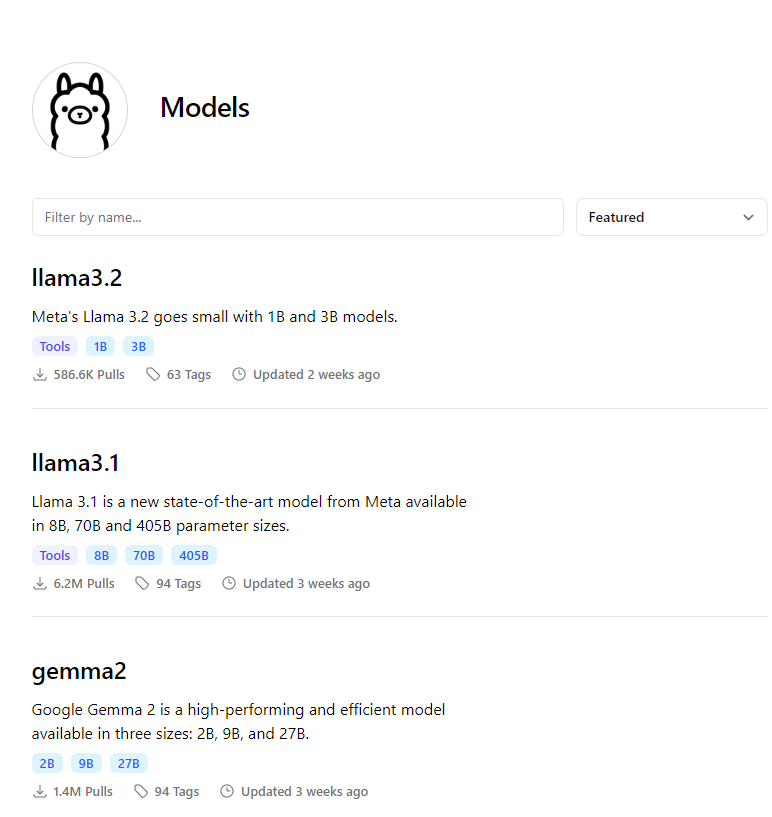
可以看到最新的LLM模型是llama3.2,這些都可以下載來使用的,不過為了文章的連貫性,這裡會選擇上一篇文章中的llama3。
執行ollama run指令,下載並運行LLM模型:
ollama run llama3
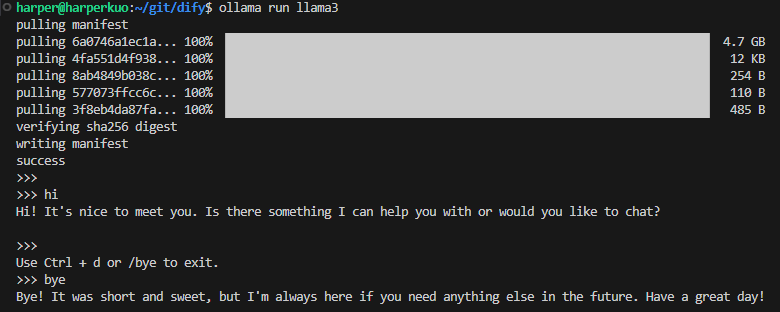
執行完成之後可以馬上和模型開始對話。
ollama run指令,下載並運行Embedding模型:# 下載並運行Embedding模型
ollama run mxbai-embed-large
# 確認下載的模型清單
ollama list
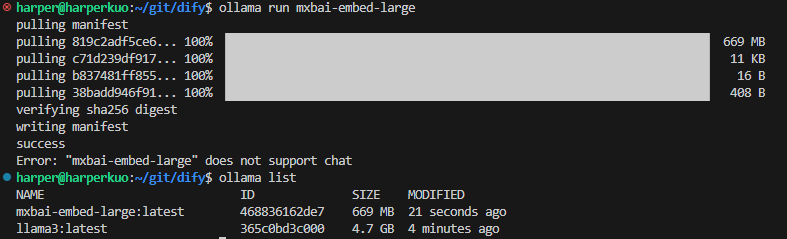
同樣執行ollama run指令,我們也可以下載指定的Embedding模型,不過因為這個不是負責生成對話的模型,所以沒辦法直接運行跟模型互動對話。接者,確認我們的模型下載清單,可以看到現在有了llama3和mxbai-embed-large兩個不同功能的模型了。
接下來,就可以依照上一篇提到的設定方式,將我們的地端模型和Dify做連接設定,這樣一來,我們的地端聊天機器人就有聊天和文字轉向量的功能啦。
啟用了地端的模型服務之後,明天我們就來使用這些模型的功能,先試試看餵文檔給聊天機器人。
Ollama官網
https://ollama.com/
How to Run Your Own Uncensored AI on Ubuntu - Mistral 7B LLM
https://www.youtube.com/watch?v=7d22hCagG0w
五分鐘上手 Ollama - 在本機跑 LLM 語言模型
https://ywctech.net/ml-ai/ollama-first-try/
不知不覺又學會了一項技能,我們現在不只成功部屬了網站服務,還學會了使用ollama來啟用模型服務。

