
今天我們要實際上傳文檔,建立我們聊天機器人背後的知識庫。有了網頁介面,要達成這個目標變得直觀很多,不過Dify背後的運作還有使用到Celery這個技術,如果沒有啟動的話,即使上傳了文檔,資料還是沒辦法轉換成可以用的模樣,會像這樣看到Queuing的狀態: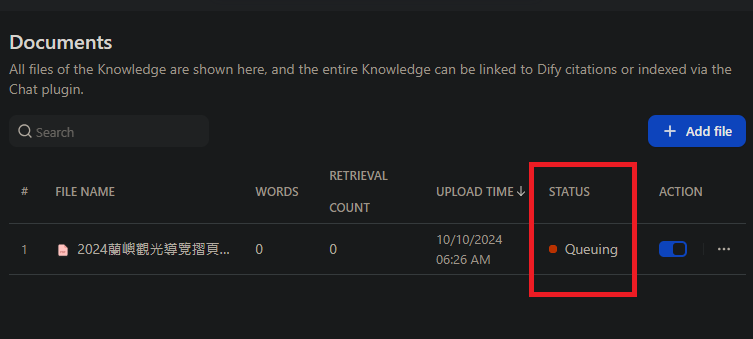
Celery是一個由Python開發的分散式任務處理系統,在Dify中用於任務管理和後台作業處理,這麼做的優點是藉由非同步處理方式,提升使用者體驗。回顧說明文件中的部屬伺服器,其實還有一個步驟我們沒有執行-Worker service。若要使用佇列中的非同步任務(例如資料集檔案匯入和資料集文件更新),就必須啟動Worker service,讓Celery使用Redis(先前我們部屬的資料庫之一)作為其代理程式來管理任務佇列。也就是說在Dify,如果只是要一個可以回話的聊天機器人,就只要串接好LLM模型就可以運作了,但RAG聊天機器人需要有資料檢索功能,所以我們必須使用Celery,讓這個功能順利運作。
回到開發環境中,原本已經有兩個終端機,各自啟動前端和後端的服務,現在我們要新增第三個終端機,用來運作Worker service:
# 進入api資料夾
cd api
# 啟用虛擬環境
poetry shell
# 使用celery啟用Worker service
celery -A app.celery worker -P gevent -c 1 --loglevel INFO -Q dataset,generation,mail,ops_trace
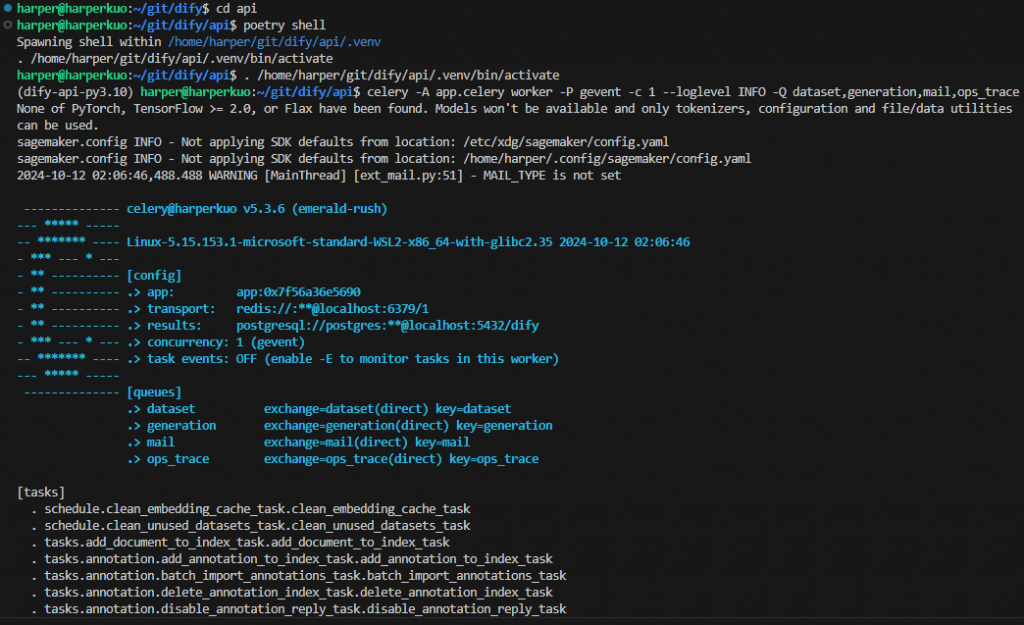
執行完上述指令後,就可以看到worker service在後台運作了。
到Knowledge頁面,Create Knowledge,選擇要上傳的檔案,注意格式以及檔案大小要按規定,這邊我們示範上傳一個國慶新聞的HTML: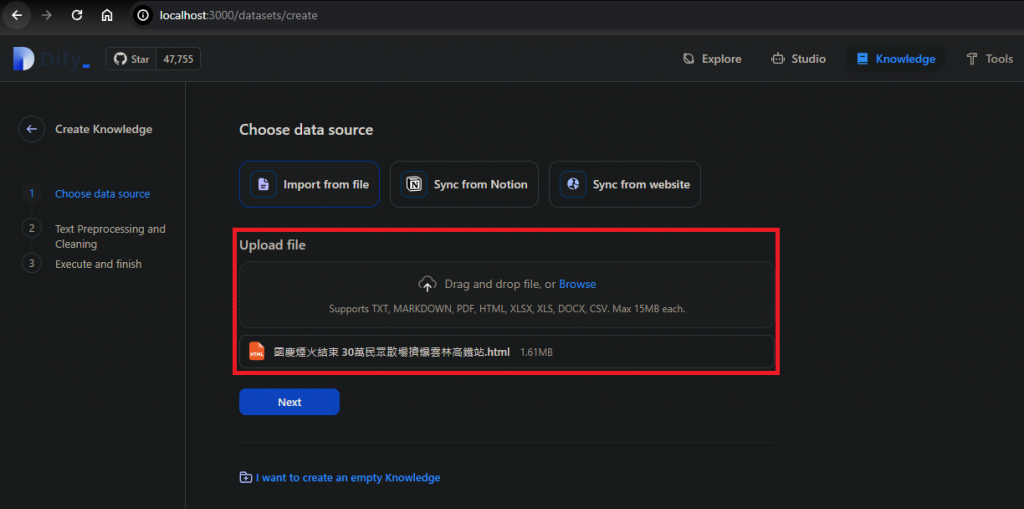
選擇文字轉向量要用的Embedding Model: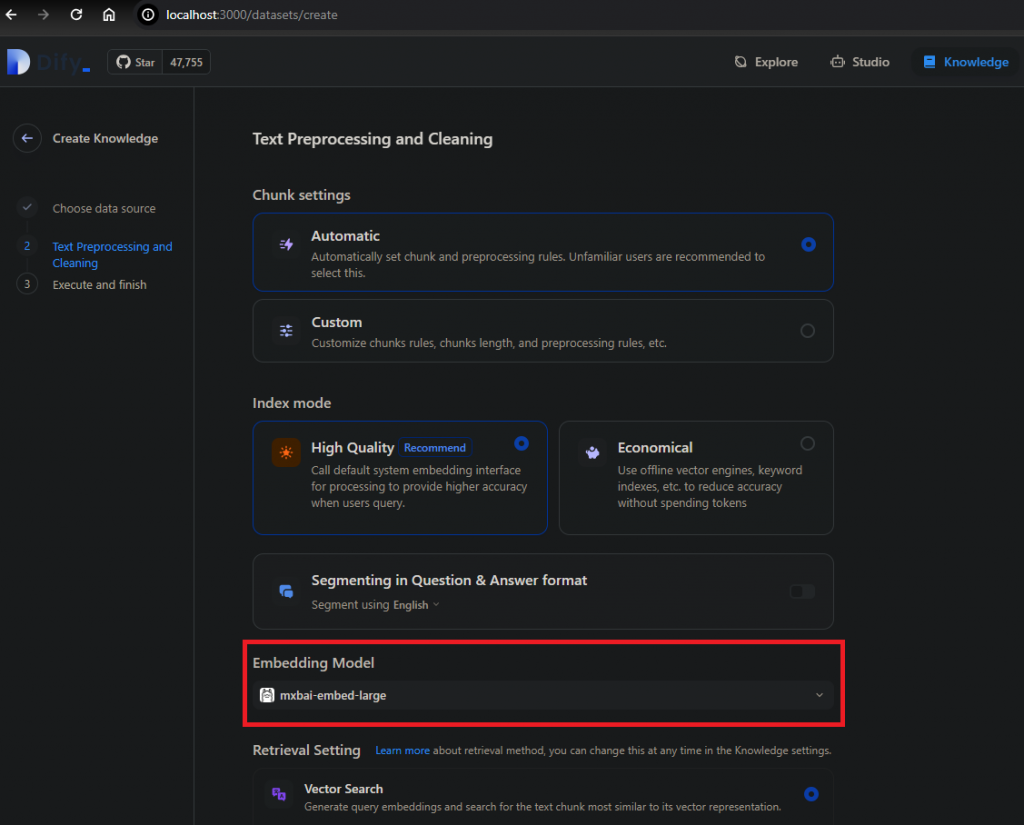
選擇搜尋引擎的檢索方式,推薦選用Hybrid Search,結合文字與向量搜尋: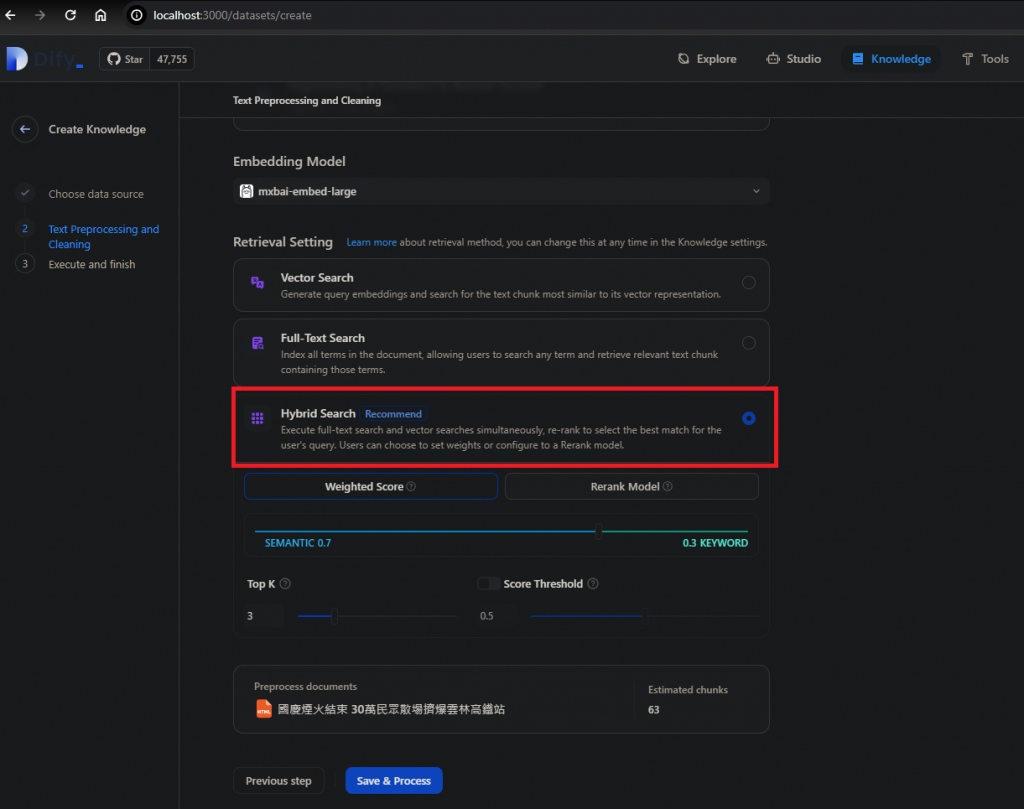
設定好送出,就會告訴我們知識庫建立好了: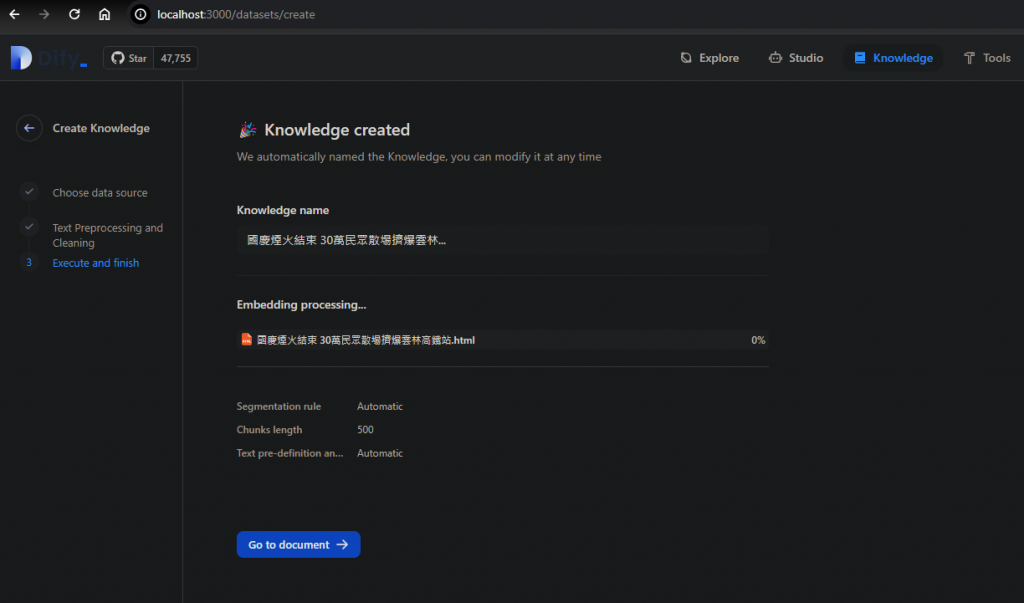
檢查文件的STATUS,狀態要是Available才可被使用,如果沒有啟用Worker service,這裡會顯示Queuing: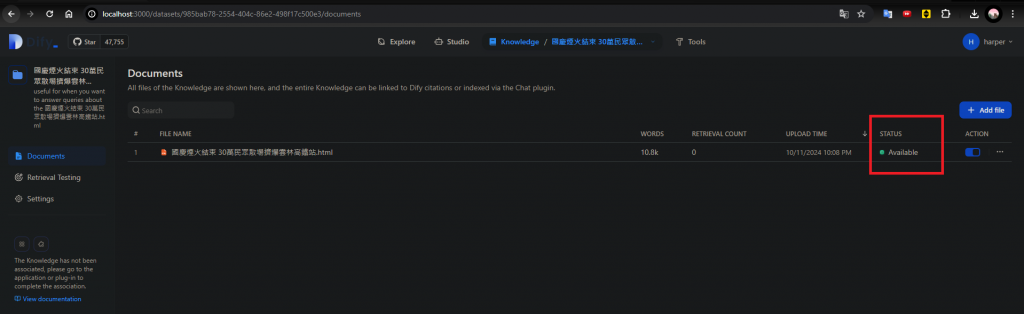
同理,我們可以再add file,替知識庫新增第二個文檔: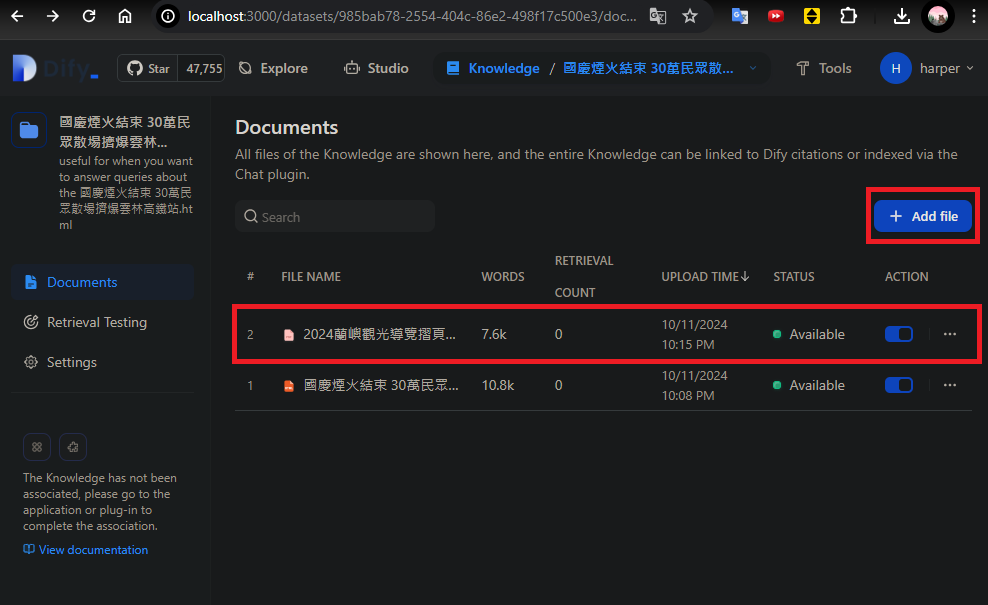
最後,到setting,設定這個知識庫的名稱與說明:
現在,我們成功建立了簡易的台灣旅遊知識庫,內含國慶煙火新聞和蘭嶼的旅遊資訊,聊天機器人可以從這裡找到回答的依據。
明天我們將在Dify建立一個聊天機器人,並和他實際對答,來看看是不是真的能從我們餵的檔案回答相關資訊。
部屬伺服器(Dify官方文件)
https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#server-deployment
What redis/celery is used for?(Dify Github)
https://github.com/langgenius/dify/issues/4825
Day 27 Celery(2021IT鐵人賽文章)
https://ithelp.ithome.com.tw/m/articles/10273022
明天是鐵人賽的最後一天,也是我們Part2實作篇的成果發表會,來看看自己部屬的地端聊天機器人成效如何吧!

