
在本章節中,我們將會探討各種可觀測策略,並且透過對其的理解,來學習 Grafana Cloud 的 Application Observability 的實踐方式,反向理解出 Grafana Labs 對於可觀測策略的哲學以及實踐細節,為此我們也能從中了解出為何這些經典的可觀測策略將會廣被世人流傳。
在現代分佈式系統和微服務架構中,可觀測性已成為確保系統穩定性和性能的關鍵因素。為了有效地監控、分析和診斷系統的運行狀況,業界發展出了一系列經典的可觀測策略,其中最具代表性的包括 RED 方法、USE 方法和 Golden Signals。
在本章節中,我們將深入探討這些可觀測策略,並學習 Grafana Labs 如何實踐這些方法。理解這些策略的核心理念和應用場景,我們不僅能掌握 Grafana Labs 在可觀測性領域的哲學與實踐細節,還能體會為何這些經典策略能夠在業界廣為流傳,成為維持系統穩定性和優化性能的寶貴工具。
“You can’t improve what you don’t measure.”
- Peter Drucker.
正如 Peter Drucker 所說:「你無法改善你無法衡量的事物」,因此監控是提升服務(包括性能、可靠性等)最重要的起點。我們希望進化現有的監控架構,以更好地實現以下目標:
可觀測策略的出現,正式為了解決傳統監控系統中的一些核心問題,這些常見的問題很容易造成維護人員的負擔以及疲勞,尤其在現代分佈式系統和微服務架構中更為明顯,因為這些系統通常都非常複雜且動態,導致沒有妥善規劃的監控方法無法有效應位。
傳統監控往往依賴大量的指標,但這些資料並不一定是有意義或精煉過的。沒有明確的目標和策略,監控將淪為一個純粹收集資料的過程,而不是作為有效的分析和判斷依據。這種漫無目的的監控,最終將會讓團隊難以找到真正的重要的訊號。
隨著監控需求的增加,許多團隊傾向於在儀表板上堆積大量的圖表和數據,以期全面掌握系統狀況。然而,這樣的做法往往適得其反,儀表板變得過於複雜和雜亂,超出了人類能夠有效理解和反應的範圍。
以監控一個服務舉例,多數人會秉持著監控最好多多益善、八面玲瓏的心態,將各種顆粒粗細、維度不一致的所能找到的 Dashboard 通通導入。導致當真正需要快速解決問題時,這些雜亂的 Dashboard 反成了另一種阻礙。
現代系統中,資料的複雜性和數量級持續增加,這讓傳統的監控系統無法滿足需求,結果是資料雜亂、重疊和冗餘的情況越來越普遍。這些問題不僅增加了系統維護的難度,也導致了監控結果的不可靠。最終我們將通過實施如 RED、USE 和 Golden Signals 這樣的策略,使團隊可以從海量的資料中提取出最重要的信號,並將其轉化為具體的、可操作的洞察。

幫我們面臨以上難題時,正是我們可觀測策略的用武之地。一個良好的策略可以用來決定哪些內容最為重要並且需要重點監控。而 Grafana Labs 也給我們以下幾項簡明扼要的指導原則:
RED 指標的概念是由目前 Grafana 的 CTO Tom Wilkie ,在 Kausal 擔任創辦人時於 2015 年提出的。Wilkie 在意識到 USE Method 不適用於服務後創建了它。
RED 專注於監控微服務架構中的關鍵指標,特別是 API 或服務端點的運行情況。它包括三個指標:
RED 的目的是快速識別和診斷微服務中的問題,幫助工程師確保服務在高負載下仍能穩定運行。
USE 主要用於監控系統資源(如 CPU、內存、磁碟等)的運行情況。它包括三個指標:
這種方法一開始幫助我們確定每種資源(CPU、記憶體等)使用哪些特定指標,但我們的下一個任務是解釋它們的值,而且它並不總是那麼明顯。
它可協助我們識別可能成為系統瓶頸的問題並採取適當的對策,但它需要仔細調查,因為系統很複雜,因此當您看到效能問題時:
這可能是一個問題,但也可能不是。
例如 100% 的使用率通常是系統瓶頸的象徵,但 50% 的使用率也可以使系統崩潰。
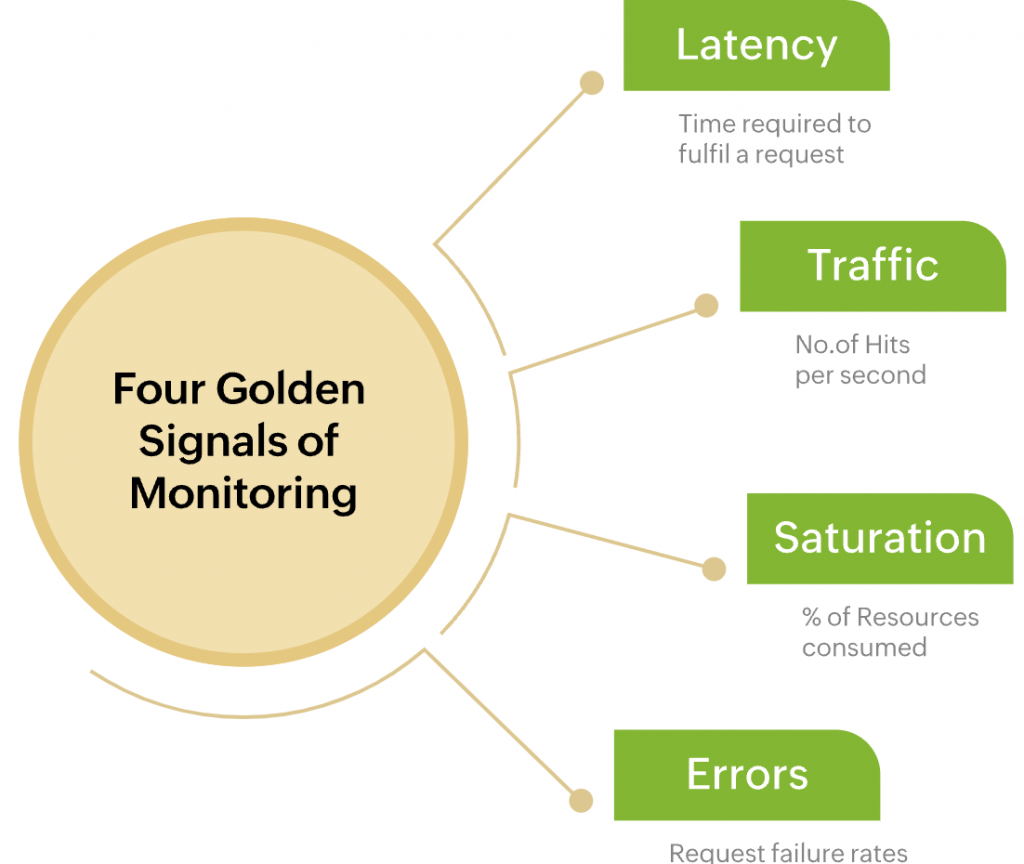
Golden Signals 是由 Google 提出的四個關鍵指標,用來監控分佈式系統和微服務架構的整體健康狀況。這四個指標包括:
Golden Signals 的目的是提供一個全面的框架,讓工程師能夠快速了解系統的整體狀態,並在出現異常時迅速作出響應。

正如 Grafana CTO Tom Wilkie 所說:「RED 指標可以很好地反映使用者的滿意度。如果我們的錯誤率很高,那麼這基本上會傳達給使用者,他們會遇到頁面載入錯誤。如果我們的持續時間很長,那麼網站就會很慢。因此,這些都是建立有意義的警報和衡量 SLA 的非常好的指標。」。
再回顧 Grafana 提供的指導原則,我們不難看出 Grafana Labs 對於 RED 指標的重視程度,為此 Grafana Labs 結合 Distributed Tracing 和 RED 指標的概念,在 Grafana Cloud 平台中打造了「Application Observability」作為監控分佈式系統和微服務的解決方案。它是一個圍繞 OpenTelemetry 語義約定和 Prometheus 資料模型構建的應用程式和效能監控解決方案。它旨在幫助您的團隊最大限度地縮短應用程式問題的平均修復時間 (MTTR)。
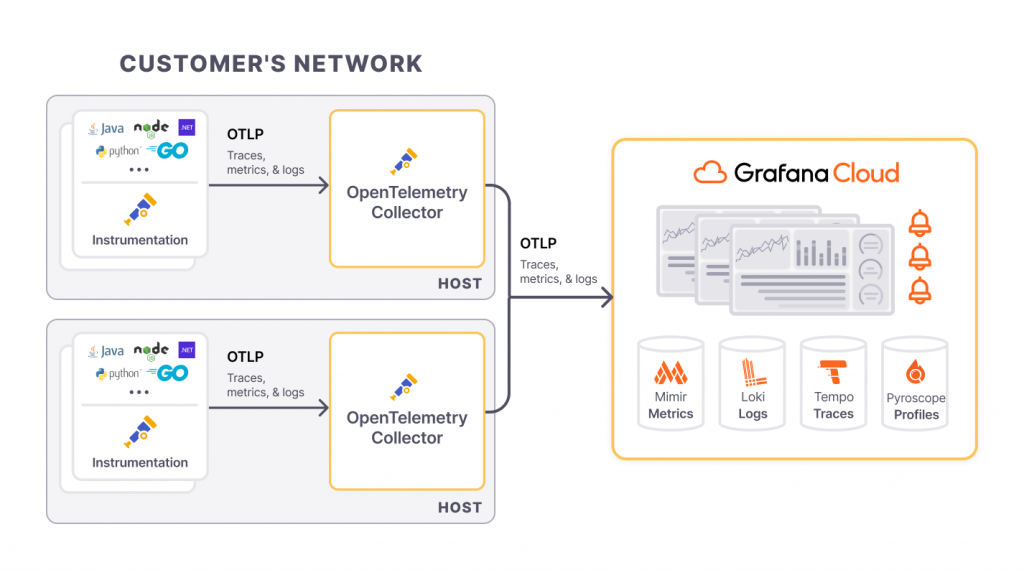
Application Observability 能夠協助開發人員和可靠性工程師減少偵測異常、識別根源和修復問題所需的時間:
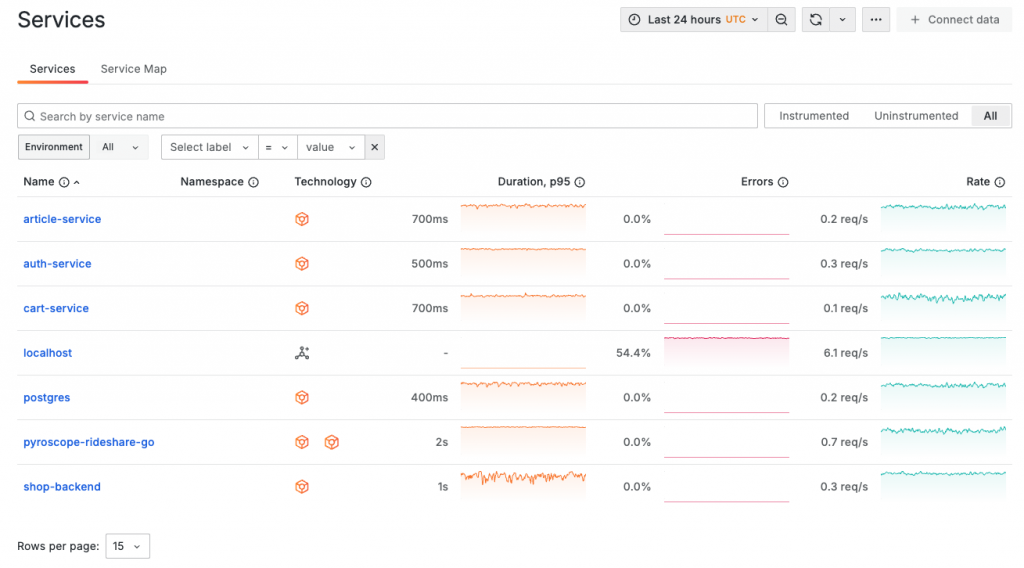
在 Service Inventory 頁面中,我們可以看到 Grafana Cloud 對於微服務監控的核心理念:
我們不應該依賴檢查數十個儀表板來確認一個服務是否正常。
因此,Grafana Cloud 強調應該從終端使用者的角度出發,聚焦於最相關的監控指標——也就是 RED 指標。通過收集和分析 Span 所提取的 SpanMetrics,我們可以完整獲取關鍵的請求量、狀態碼和延遲等指標。最終,RED 指標的實踐將幫助我們擺脫監控疲勞,提升系統監控的有效性。
在 Application Observability 的 Overview 頁面中,我們可以清晰地看到生產環境中的服務列表。最重要的是,每個服務並不依賴繁雜的 Dashboard 或不同角度的服務狀態視圖,而是專注於純粹反映使用者真實體驗的 RED 指標(Request Rate、Errors、Duration)。這意味著我們只關注與使用者最直接相關的三個指標,而這三個維度無論服務的大小或複雜度如何,皆不會改變,從而使我們能夠遵循統一的原則來確保良好的服務品質。
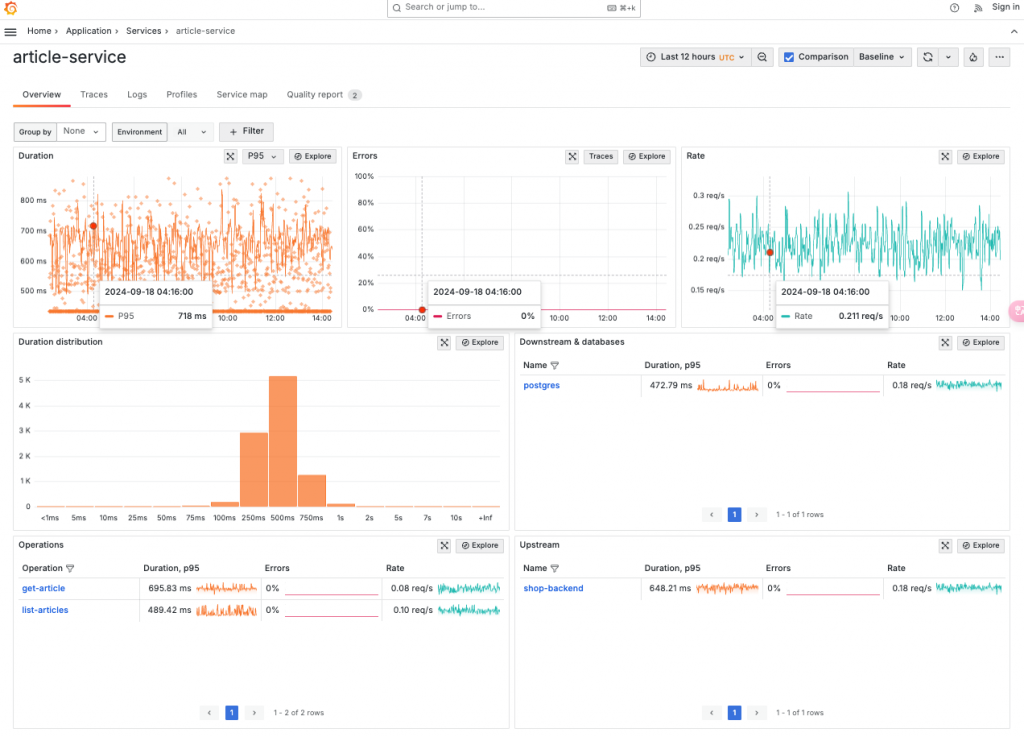
Grafana Cloud 堅持貫徹 RED 方法實踐,當我們想要深入關注特定服務時,只需直觀地點擊服務名稱,即可進入 Service Detail 頁面。在這個頁面中,我們可以通過 Taggle 切換來快速查看所選服務的所有可觀測性指標資料,幫助我們聚焦在特定時間區間內的一切可能問題。Grafana 通過巧妙的階層式維度設計,使我們能夠輕鬆滿足縱向和橫向的探索需求,不僅限於服務本身,還能快速了解與之相關的所有上下游資源狀態。
在 Service Detail 頁面中,系統自動將服務請求鏈路中的上下游關聯服務標示出來,幫助我們在進行深層探索時能夠一目了然地掌握整體服務的依賴關係。這種清晰的鏈路視圖,結合直觀的數據切換,讓我們能夠快速定位服務的性能瓶頸和潛在問題,從而有效提升問題排查和解決的效率。
另一個得益於完整分佈式追蹤的好處,是我們能夠輕易實現對複雜微服務之間的請求拓樸(ServiceGraph)進行可視化。Service Map 直觀地呈現了各個服務之間的依賴關係,讓我們能夠即時了解每個服務的請求流向、上下游依賴,以及整個系統的交互方式。透過這個圖示化的拓樸結構,我們不僅可以迅速識別瓶頸和潛在問題,還能夠追蹤服務之間的延遲、錯誤率及其他關鍵指標,進一步優化服務之間的協作與性能表現。這使我們能夠在微服務架構下更加有效地進行問題排查與調優,確保系統穩定性和高效運行。
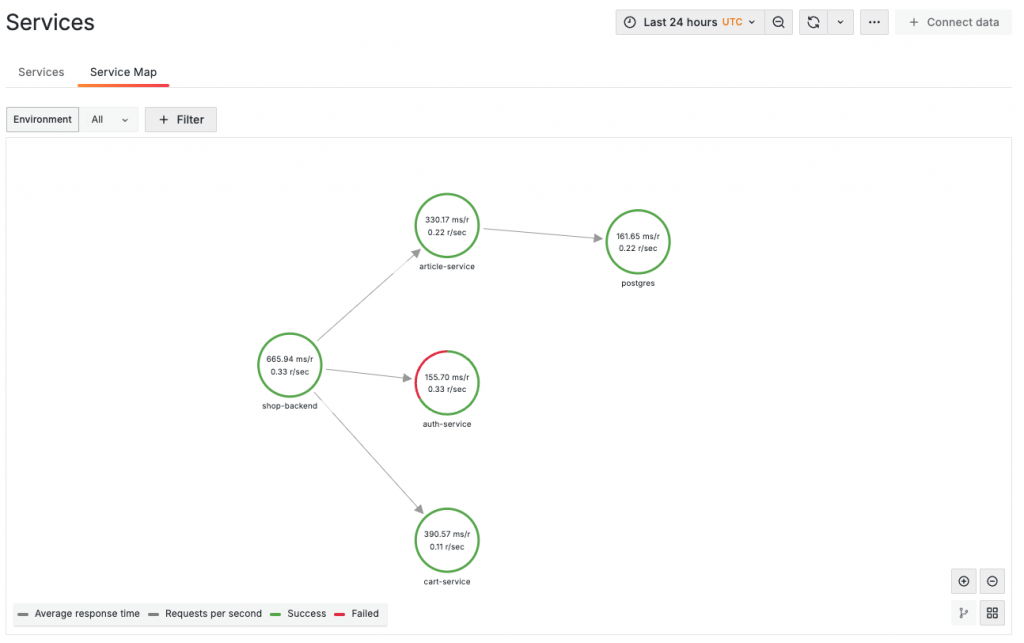
當我們剛開始接觸 Grafana 時,很容易被它強大且即開即用的各種 Dashboard 所驚艷。然而,隨著我們越來越依賴 Grafana,龐大的監控資料也帶來龐大的資訊疲勞,這讓我們開始思考,究竟什麼樣的「策略」才是最佳策略。儘管我們讀過許多理論,每種看似都有道理,但在實踐中卻難以找到可以效仿的範例。幸運的是,Grafana Cloud 在產品設計上,往往經過仔細品味後,我們可以很快發現其精妙之處,以及其對完善設計理念和最佳實踐的堅持。
References:
https://faun.pub/use-vs-red-vs-the-four-golden-signals-50655e93fad7
https://grafana.com/blog/2018/08/02/the-red-method-how-to-instrument-your-services/
https://medium.com/thron-tech/how-we-implemented-red-and-use-metrics-for-monitoring-9a7db29382af


 iThome鐵人賽
iThome鐵人賽