在進行任何機器學習或數據分析專案時,拿到數據的那一刻起,就決定了後續工作的基礎。資料探勘(Data Mining)是深入理解數據、發現潛在模式和異常的重要過程。今天,我們將通過實際操作,逐步展示拿到數據後應該如何進行初步處理和分析。
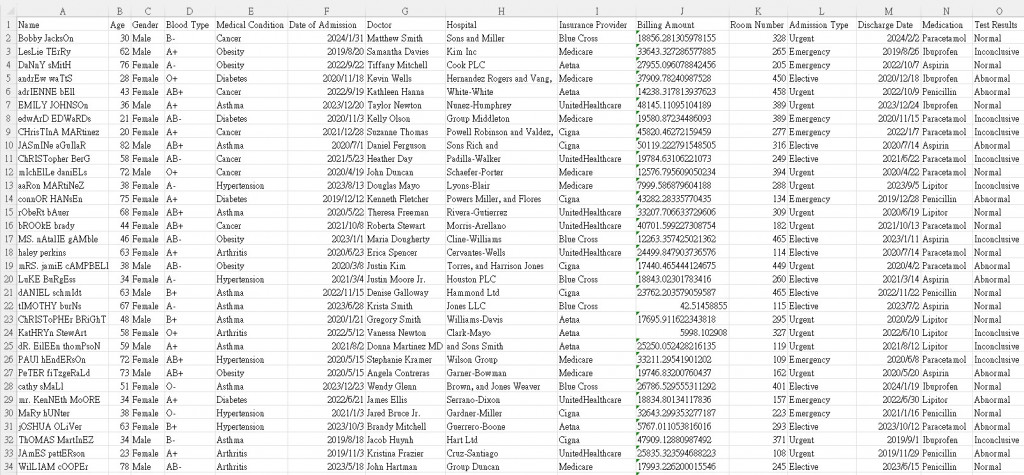
初步肉眼觀察:
我們要解決的問題是觀察數據以預測檢測結果。因此,output 是數據中最後一欄的檢測結果 ( Test Results)
接下來,我們要開始用程式碼詳細觀察人為不一定觀察到的部分。我們會需要 pandas library 進行 csv 的讀取。在資料探勘部分,筆者平常習慣將所有統計分布資料、資料視覺化、參數之間的關係、異常值、缺失值、重複值都包在一起並下載成 html 檔。筆者使用 google colab 來撰寫,程式碼如下:
!pip install catboost wandb ydata_profiling
# remove warnings
import warnings
warnings.filterwarnings('ignore')
# standard imports and setup
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from scipy import stats
# 引入檔案操作相關套件
import os
import pickle
import joblib
from datetime import datetime
from ydata_profiling import ProfileReport
# 引入機器學習相關套件
import xgboost as xgb
import lightgbm as lgb
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import Pool, CatBoostClassifier
from sklearn.model_selection import train_test_split, GridSearchCV, KFold, StratifiedKFold
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, StandardScaler, OneHotEncoder, PolynomialFeatures, KBinsDiscretizer
from sklearn.impute import SimpleImputer
from sklearn.impute import SimpleImputer
from sklearn.feature_selection import SelectKBest, SelectPercentile, SelectFpr, SelectFdr, SelectFwe, GenericUnivariateSelect
from sklearn.feature_selection import RFE, RFECV, SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# 引入其他工具
import gc
import wandb
import random
import multiprocessing as mp
# 引入日誌相關套件
from logging import getLogger, INFO, FileHandler, Formatter, StreamHandler
from google.colab import files
uploaded = files.upload()
import io
以上步驟請記得上傳已下載的資料檔案
health_data = pd.read_csv('healthcare_dataset.csv')
profile = ProfileReport(health_data)
# 將報告儲存為HTML
profile.to_file(output_file="healthcare_analysis_report.html")
#下載報告
files.download('healthcare_analysis_report.html')
下載檔案後,可以透過 HTML 報告全面了解數據的整體狀況。該報告不僅顯示了數據的分佈情況,還能與介面互動,探索不同參數之間的關聯性。報告中的警示(alerts)會標示出可能存在的問題,如分佈不均、全為常數、重複值、缺失值以及高度不平衡的類別等。在視覺化分析部分,若點陣圖(scatter plot)中出現明顯偏離主要數據群的點,則可初步判斷為異常值。此外,報告還會列出每個參數的統計描述,供進一步分析使用。由於 HTML 報告內容豐富,這裡僅展示部分關鍵資訊。我們鼓勵讀者嘗試使用上述程式碼,將自己收集的數據載入並進行分析,這樣可以更深入地體驗數據處理和分析的過程。
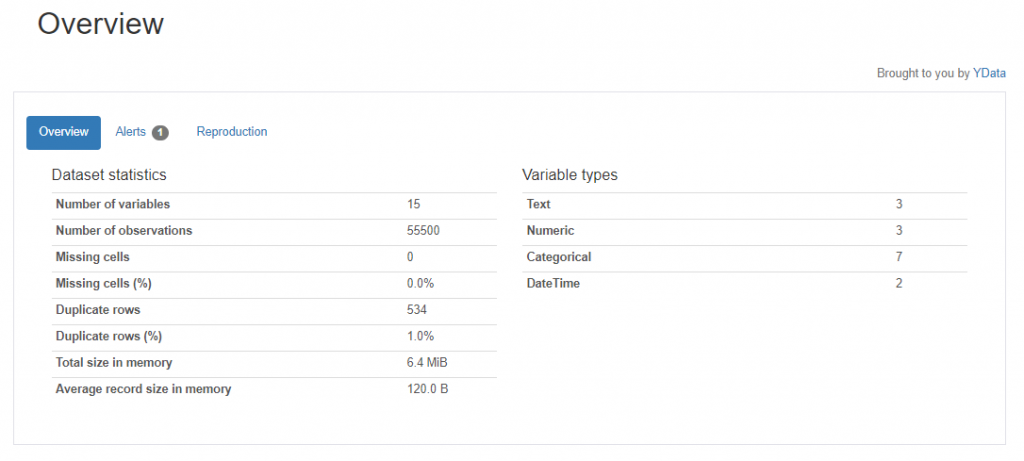
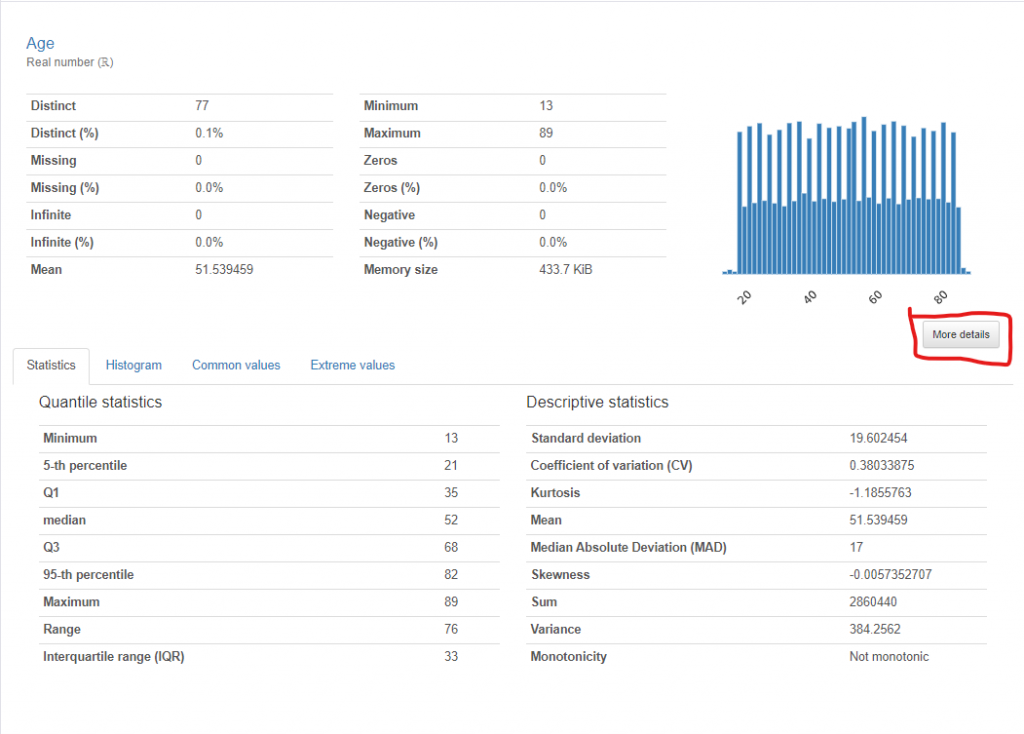
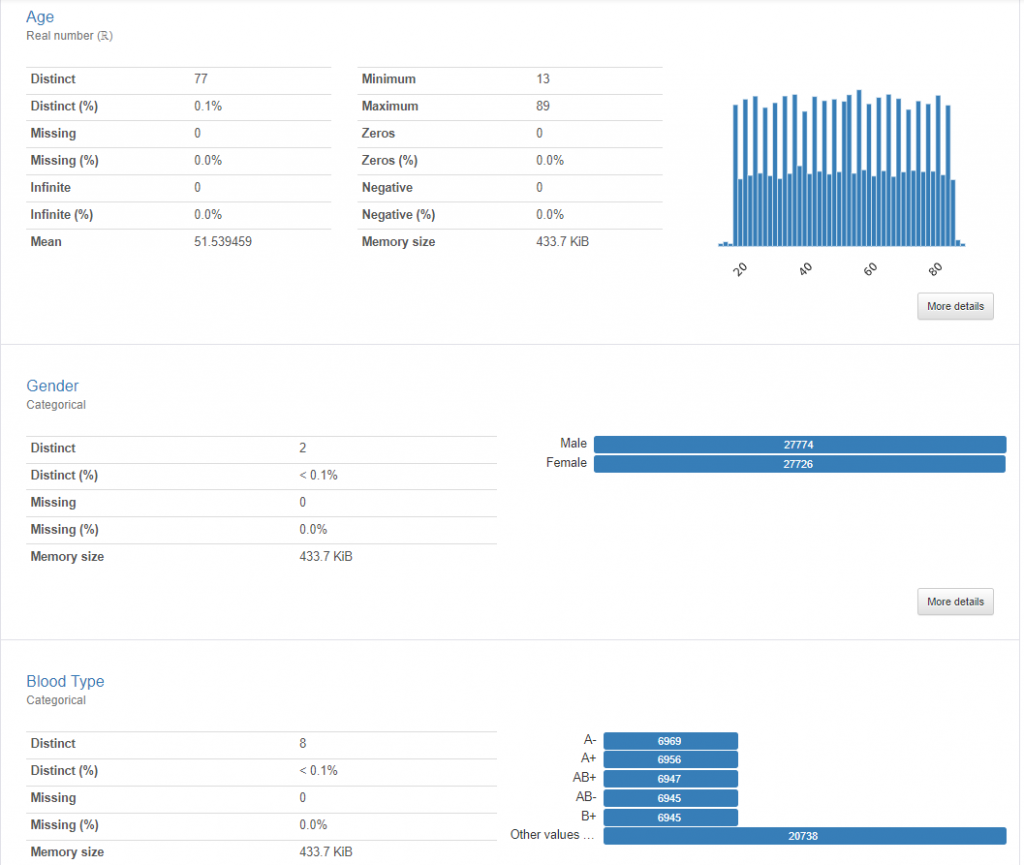
在進行任何機器學習或數據分析項目時,第一步就是深入了解手中的數據。在這篇文章中,我們通過觀察和初步分析數據,為後續的模型建構奠定了基礎。我們確定了數據集的規模、類型和潛在的問題,如異常值、缺失值等,並評估了數據的合理性及標註的準確性和一致性。接下來,我們將進一步探討如何處理這些觀察到的數據問題,進行必要的數據清理與處理,確保最終的模型能夠提供準確且可靠的預測結果。

