經過初步的資料探勘後,我們需要進一步處理數據中的缺失值、異常值、重複值等問題,以確保模型能夠在乾淨的數據上進行訓練。以下是數據清理的主要步驟和實作方法:
在初步資料探勘時,我們有提到病患名字、醫生名字、醫院名稱與病患的檢測結果並無顯著相關性。因此,在數據清理過程中,我們將這些無關的欄位移除。
import pandas as pd
health_data = pd.read_csv('healthcare_dataset.csv')
cleaning_data = health_data.drop(columns=['Name', 'Doctor', 'Hospital'], axis=1) # 移除無關特徵
由於我們只想預測兩類別,分別是 Normal 和 Abnormal,因此我們將 Inconclusive 的個案刪掉。做法如下:
cleaning_data = cleaning_data[cleaning_data['Test Results']!='Inconclusive']
# 檢查缺失值
missing_values = cleaning_data.isnull().sum()
missing_values
我們得到的結果如下: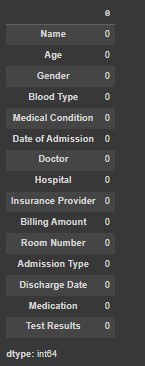
可以看到全部都是 0,代表我們的收案數據集中,並無缺失值。
但假如讀者在實作時,有發現缺失值可以依照不同的需求和缺失值比例進行處理。
處理方法包含:
# 使用眾數填補缺失值
cleaning_data['Admission Type'].fillna(cleaning_data['Admission Type'].mode()[0], inplace=True)
# 顯示填補後的資料
print("\n使用眾數填補缺失值後的資料:")
cleaning_data
# 使用平均值填補缺失值
cleaning_data['Age'].fillna(cleaning_data['Age'].mean(), inplace=True)
# 顯示填補後的資料
print("\n使用平均值填補缺失值後的資料:")
cleaning_data
舉例來說,原始資料與填補後的資料對比:
原始資料:
| Name | Age | Admission Type |
|---|---|---|
| Alice | 25.0 | Urgent |
| Bob | 30.0 | Emergency |
| Charlie | NaN | Elective |
| David | 35.0 | NaN |
| Edward | 30.0 | Emergency |
使用眾數填補 Admission Type,平均數填補 Age 後的資料:
| Name | Age | Admission Type |
|---|---|---|
| Alice | 25.0 | Urgent |
| Bob | 30.0 | Emergency |
| Charlie | 30.0 | Elective |
| David | 35.0 | Emergency |
| Edward | 30.0 | Emergency |
Note:若某欄位缺失值過多,則通常會考慮刪除該欄位:
cleaning_data.drop(columns=['...'], inplace=True)
由於 Kaggle 數據集無缺失值,因此無需做任何處理。以上只是範例僅供參考。
# 對所有數值型欄位計算 Z 分數
numeric_columns = cleaning_data.select_dtypes(include=['float64', 'int64']).columns
# 計算每個數值欄位的 Z 分數
for column in numeric_columns:
mean = cleaning_data[column].mean()
std = cleaning_data[column].std()
cleaning_data[column + '_z_score'] = (cleaning_data[column] - mean) / std
# 篩選出 Z 分數絕對值大於 3 的異常值(針對每個數值欄位)
outliers_z = cleaning_data[(cleaning_data[numeric_columns + '_z_score'].abs() > 3).any(axis=1)]
print("異常值資料:")
outliers_z
# 對所有數值型欄位計算 IQR
numeric_columns = cleaning_data.select_dtypes(include=['float64', 'int64']).columns
# 建立一個空的 DataFrame 來存儲所有的異常值
outliers_iqr = pd.DataFrame()
for column in numeric_columns:
# 計算 Q1 和 Q3
Q1 = cleaning_data[column].quantile(0.25)
Q3 = cleaning_data[column].quantile(0.75)
# 計算 IQR
IQR = Q3 - Q1
# 計算異常值範圍
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 篩選出異常值
outliers = cleaning_data[(cleaning_data[column] < lower_bound) | (cleaning_data[column] > upper_bound)]
# 將該欄位的異常值合併到最終的異常值 DataFrame
outliers_iqr = pd.concat([outliers_iqr, outliers])
# 刪除重複的異常值行
outliers_iqr = outliers_iqr.drop_duplicates()
# 顯示異常值
print("IQR 規則篩選出的異常值資料:")
outliers_iqr
兩種方法得到結果皆如下:
異常值資料為空,代表這兩種方法我們都並無找到異常值數據。
筆者喜好:更傾向使用 IQR 規則來檢測異常值。若發現異常值,會考慮刪除該數據點,除非數據量過少,則可能會保留並與相關專業人士討論處理方式。
例如,在 Kaggle 資料集中,我們發現 Billing Amount 中有少數負數或異常小的值,這些數據對整體分析影響不大,因此決定將這些數據刪除並再重新確認一次異常值:
# 刪除 Billing Amount 小於 100 的行
cleaning_data_filtered = cleaning_data[cleaning_data['Billing Amount'] >= 100]
# Calculate lower and upper bounds for each numeric column
numeric_columns = ['Age', 'Room Number', 'Billing Amount']
lower_bound = {}
upper_bound = {}
for column in numeric_columns:
Q1 = cleaning_data_filtered[column].quantile(0.25)
Q3 = cleaning_data_filtered[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound[column] = Q1 - 1.5 * IQR
upper_bound[column] = Q3 + 1.5 * IQR
# Filter outliers based on the calculated bounds
outliers_iqr = cleaning_data_filtered[((cleaning_data_filtered['Age'] < lower_bound['Age']) | (cleaning_data_filtered['Age'] > upper_bound['Age'])) | ((cleaning_data_filtered['Room Number'] < lower_bound['Room Number']) | (cleaning_data_filtered['Room Number'] > upper_bound['Room Number'])) |((cleaning_data_filtered['Billing Amount'] < lower_bound['Billing Amount']) | (cleaning_data_filtered['Billing Amount'] > upper_bound['Billing Amount']))
]
outliers_iqr
在資料探勘過程中,發現數據中有 534 筆完全重複的數據。這些重複數據對模型來說是多餘的,因此我們需要將其刪除:
cleaning_data_filtered = cleaning_data_filtered.drop_duplicates()
若有不完全重複值,也會檢查是否有同個病患重複檢測,若有也會刪除。
確保所有數據格式一致、單位統一、標籤正確。若發現錯誤,可以手動修正或使用 Python 進行數據清理。Kaggle 資料集未發現此問題。
# 檢查標註分佈
label_distribution = cleaning_data_filtered['Test Results'].value_counts()
print(label_distribution)
結果顯示:
Test Results
Abnormal 18390
Normal 18293
Name: count, dtype: int64
數據分佈較為均衡,不存在某一類別過多或過少的情況。如果數據不平衡,可以考慮在模型訓練階段使用 SMOTE 技術來平衡類別分佈。
import seaborn as sns
import matplotlib.pyplot as plt
X = cleaning_data_filtered[['Age', 'Billing Amount', 'Room Number']]
# 計算 Pearson 相關係數
pearson_corr = X.corr(method='pearson')
print(pearson_corr)
# 計算 Spearman 相關係數
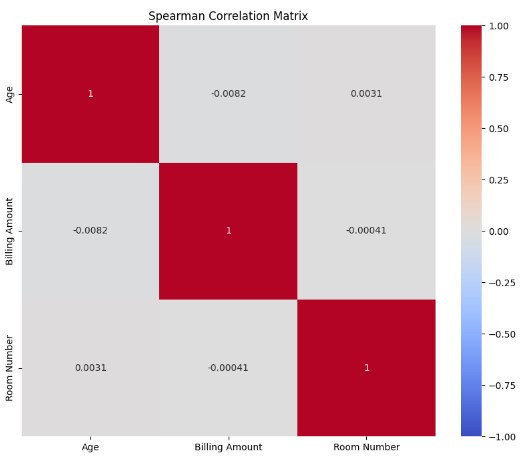
spearman_corr = X.corr(method='spearman')
print(spearman_corr)
# 可視化相關矩陣
plt.figure(figsize=(10, 8))
sns.heatmap(pearson_corr, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pearson Correlation Matrix')
plt.show()
plt.figure(figsize=(10, 8))
sns.heatmap(spearman_corr, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Spearman Correlation Matrix')
plt.show()
結果顯示:各特徵之間的相關性非常低,接近於 0,這表明這些特徵之間幾乎沒有線性關聯性,因此不太可能存在嚴重的多重共線性問題。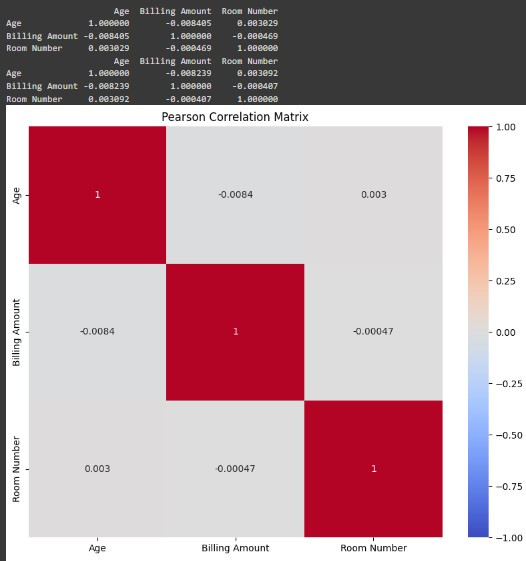
本章介紹了數據清理的關鍵步驟,包括處理缺失值、異常值、重複數據,確保數據的一致性等。我們還移除了與預測無關的參數,為模型的訓練提供了乾淨且有用的數據。在下一章,我們將探討特徵工程中的特徵轉換與縮放。這些步驟有助於提升模型性能,確保數據特徵在相同尺度上進行比較。

