最近不同的推理框架不斷地冒出,其實主流也就是那幾個XD,在選擇使用哪一個之前,應該要先定義清楚使用情境,像是給個人電腦做運算 🖥️,還是做成API server 🌐,又或是在不同設備上做邊緣運算 📱。
想要以速度為主 ⚡,還是以功能為主 🔧?
- 並不是每一個都支持custom models或token streaming 🔄
- 也不是每一個都可以使用CPU 💻
- 而極少數支持adapters 🔌
推薦 這一篇文章 的比較表格非常簡單好懂 📊。
(圖源: linkedin,搜尋LLM速度的時候發現的梗圖XD)
順序一樣是想到什麼寫什麼,裡面有寫到使用多種加速技術的框架都可以在他們的Github上面看到它用了什麼技術。
⚠️ 注意:這邊寫的內容除了vLLM,都是2024/9查的,後續可能會有更多更新,僅供參考用。
🔍 簡單小統整:
🌐 適合API Server:vLLM、TGI、DeepSpeed-MII、TensorRT-LLM、LMdeploy、FastChat。
💻 適合個人電腦:Ollama、MLC-LLM、AirLLM。
另外專門為CPU推理的框架還有一個CTranslate2 ⚙️
目前很多文章都有在比較他們他們之間的速度,不過礙於他們都還是在持續開發中,現在的比較過一陣子可能就沒有意義了,每個github都寫自己最快,但vLLM github放的比較結果卻不是自己最快的XD,因此先以這個為主。
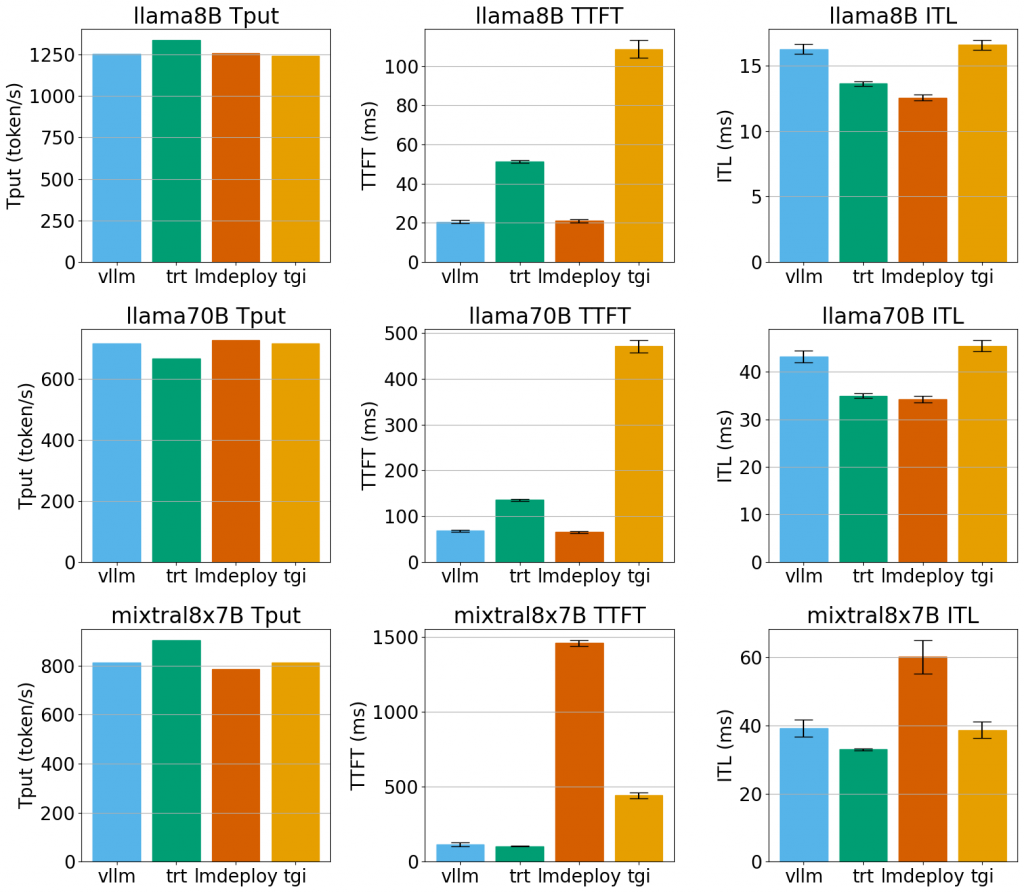
(圖源: buildkite,vLLM / TensorRT-LLM / LMdeploy / TGI之間的比較,比較的時間是2024/7)
這個比較的硬體設備是One AWS node with 8x NVIDIA A100 GPUs.
另外,這個比較測試有一個表格,可以看到更詳細的數字。
整體來看,所有測試的Successful req.都是500,代表這些框架在這些特定的工作負載下都能穩定運行,沒有出現崩潰的情況。
整體來說vLLM和TensorRT-LLM比較穩定,而LMdeploy和TGI在特定情境較不穩定。
除了目前最經典的vLLM和TGI 🌟,LMdeploy也是一個值得被注意到的框架 🔍。在選擇推理框架時,了解每個框架的特點和應用場景是非常重要的,隨著技術的不斷演化 🦠,未來仍有可能會出現更多創新性的解決方案。 🧬🧬🧬
這章寫起來比想像中的還要難很多,原本是希望可以把所有框架用到的加速技術都列出來,結果越挖越多,而且很多框架並不是以加速技術為主的,即使可以作為API server,也並沒有特別寫到他們使用的技術是什麼QQ
雖然現在vLLM並不算是目前最快速的框架,但筆者還是很喜歡它,因為整體而言相較穩定、該有的功能都有,而且用起來很簡單XDD,明天就接著來實作時間囉! 🛠️✨
Best LLM Inference Engine? TensorRT vs vLLM vs LMDeploy vs MLC-LLM (2024/7)
https://medium.com/@zaiinn440/best-llm-inference-engine-tensorrt-vs-vllm-vs-lmdeploy-vs-mlc-llm-e8ff033d7615
0.llm推理框架简单总结 (2024/5)
https://github.com/wdndev/llm_interview_note/blob/main/06.%E6%8E%A8%E7%90%86/0.llm%E6%8E%A8%E7%90%86%E6%A1%86%E6%9E%B6%E7%AE%80%E5%8D%95%E6%80%BB%E7%BB%93/0.llm%E6%8E%A8%E7%90%86%E6%A1%86%E6%9E%B6%E7%AE%80%E5%8D%95%E6%80%BB%E7%BB%93.md
Comparing LLM serving frameworks — LLMOps (2023/12)
https://medium.com/@plthiyagu/comparing-llm-serving-frameworks-llmops-f02505864754

