參考資料
FinRL_PortfolioAllocation_NeurIPS_2020.ipynb
FinRL_PortfolioAllocation_NeurIPS_2020.py
為了更準確地比較 MVO 策略和 DRL 模型的表現,教學原文這邊修改了 MVO 的計算方法,使其與 DRL 模型的動態特性相匹配。
max_sharpe()改為min_volatility(),以最小化波動率。前篇文章中的 MVO 策略是一次性計算並持有至到期,但因為與 portfolio allocation 需動態調整資產配置的目的不符,因此修改。
前篇文章中的 MVO 策略單一資產的最大占比為 0.5,可能導致過度集中投資,總之就是可能的獲利較大但風險也較大。
以下是修改後的 MVO 計算函數:
def calculate_daily_rebalanced_mvo_portfolio(df, unique_trade_dates, initial_capital=1000000):
"""
通過每日再平衡計算最小方差組合(MVO)。
參數:
- df:包含股票數據的 DataFrame,需要包含 'date'、'tic'、'close' 和 'return_list' 列。
- unique_trade_dates:交易日期的列表或數組。
- initial_capital:初始資金,默認為 1,000,000。
返回:
- portfolio:包含賬戶價值隨時間變化的 DataFrame。
"""
from pypfopt.efficient_frontier import EfficientFrontier
import numpy as np
# 初始化投資組合 DataFrame
portfolio = pd.DataFrame(index=range(1), columns=unique_trade_dates)
portfolio.loc[0, unique_trade_dates[0]] = initial_capital
# 遍歷交易日期,計算每日投資組合價值
for i in range(len(unique_trade_dates) - 1):
current_date = unique_trade_dates[i]
next_date = unique_trade_dates[i + 1]
# 獲取當前日期和下一日期的數據
df_current = df[df.date == current_date].reset_index(drop=True)
df_next = df[df.date == next_date].reset_index(drop=True)
# 計算當前日期的協方差矩陣
Sigma = df_current['return_list'][0].cov()
# 使用最小化波動率的方法計算權重
ef = EfficientFrontier(None, Sigma, weight_bounds=(0, 0.1))
ef.min_volatility()
cleaned_weights = ef.clean_weights()
# 計算每個資產的資金分配和持有數量
cap = portfolio.iloc[0, i]
weights = np.array(list(cleaned_weights.values()))
current_cash_allocation = weights * cap
current_prices = df_current['close'].values
current_shares = current_cash_allocation / current_prices
# 計算下一日期的投資組合價值
next_prices = df_next['close'].values
portfolio_value_next = np.dot(current_shares, next_prices)
# 存儲投資組合價值
portfolio.iloc[0, i + 1] = portfolio_value_next
# 轉置 DataFrame 並命名列
portfolio = portfolio.T
portfolio.columns = ['account_value']
return portfolio
通過上述修改,MVO 策略每天重新計算最優權重並再平衡,與 DRL 模型的動態調整相對應。
在對 DRL 模型進行回測之前,我們需要計算基準策略的績效,以便進行比較。這裡我們使用道瓊斯工業平均指數(DJI)和最小方差組合(MVO)作為基準。
### 獲取基準數據
dji_daily_return = calculate_dji_daily_return(TRADE_START_DATE, END_DATE)
unique_trade_date = trade['date'].unique()
mvo_portfolio = calculate_daily_rebalanced_mvo_portfolio(df, unique_trade_date)
mvo_daily_return = calculate_daily_return_from_portfolio(mvo_portfolio)
# 初始化交易環境
e_trade_gym = StockPortfolioEnv(df=trade, **env_kwargs)
# 進行回測
backtest_results = backtest_drl(e_trade_gym, trained_models)
# 繪製累計收益曲線
trade['date'] = pd.to_datetime(trade['date'])
time_ind = pd.Series(trade['date'].unique()).sort_values()
plot_cumulative_returns(backtest_results, time_ind, min_var_daily_return=mvo_daily_return, dji_daily_return=dji_daily_return)
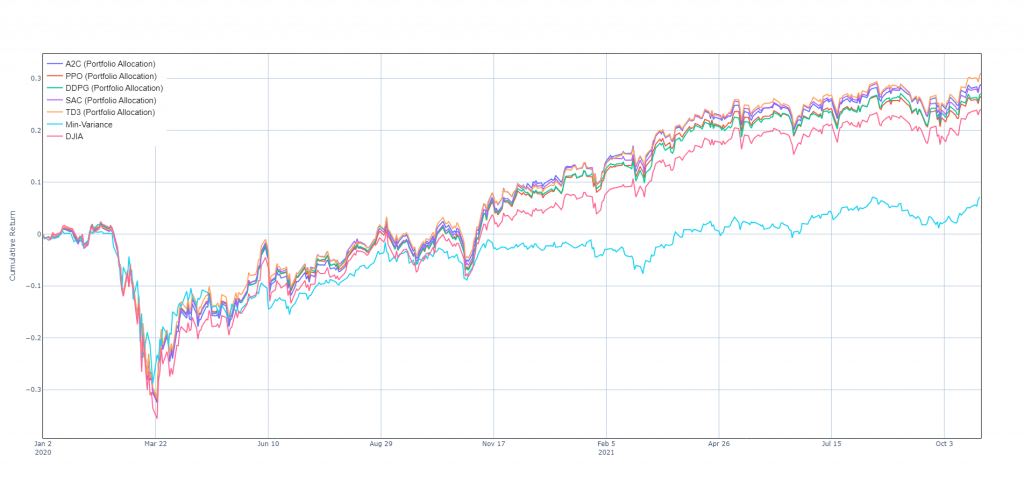
在動態修改資產配置的情況下,DRL 與 MVO 策略和 DJI 的累計收益曲線比較如下:
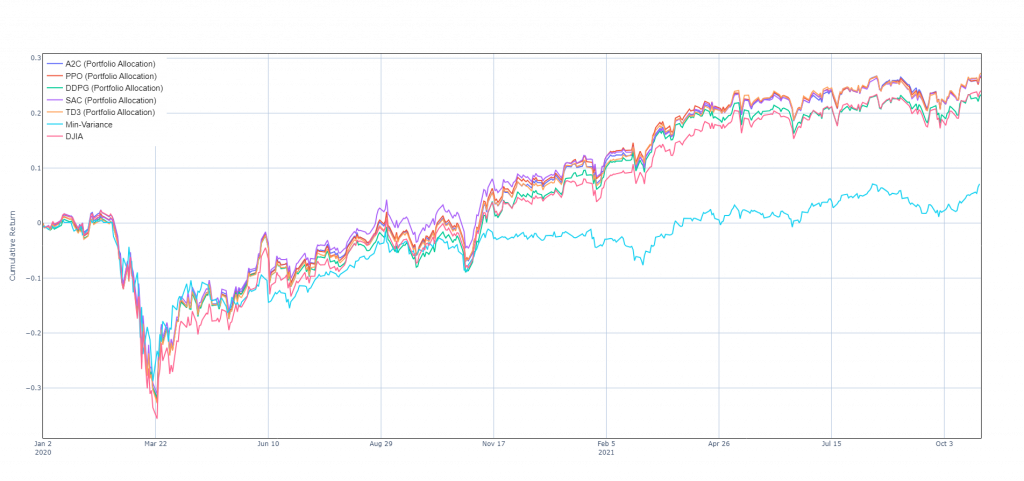
因為教學原文刻意讓訓練數據區間與回測數據區間重疊,所以這邊特別實驗了一下完全不重疊的情況,評估一下模型的泛化能力如何。
我將訓練數據區間改為 '2009-01-01' 至 '2019-12-31',交易(回測)數據區間為 '2020-01-01' 至 '2021-10-31'。
重新訓練模型並進行回測後,發現模型的績效有所下降,但其實也沒有下降非常多。
看起來 DRL 的模型還是有一定的泛化能力,但是在實際應用中,我最擔心的還是模型的泛化能力,畢竟資產數據量怎麼樣都不可能像圍棋那樣要多少有多少。
from stable_baselines3 import A2C, DDPG, PPO, SAC, TD3
from finrl.agents.stablebaselines3.models import DRLAgent
import plotly.graph_objs as go
import pandas as pd
import os
import quantstats as qs
def train_drl(e_trade_gym, models_info):
"""
Function to train deep reinforcement learning (DRL) models.
Parameters:
- e_trade_gym: The trading environment for backtesting.
- models_info: A dictionary containing the model class as keys and corresponding training parameters and paths as values.
Returns:
- trained_models: A dictionary containing the trained models.
"""
env_train, _ = e_trade_gym.get_sb_env()
# Initialize DRLAgent
agent = DRLAgent(env=env_train)
# Dictionary to store the trained models
trained_models = {}
# Loop through each model class and its associated information
for model_class, info in models_info.items():
model_path = info["save_path"]
if os.path.exists(model_path):
print(f"正在從 {model_path} 加載現有的 {model_class.__name__} 模型")
# Load the model using stable-baselines3
try:
model = model_class.load(model_path, env=env_train)
trained_models[model_class.__name__] = model
print(f"{model_class.__name__} 模型加載成功。")
except Exception as e:
print(f"加載 {model_class.__name__} 模型失敗: {e}")
print(f"將繼續訓練 {model_class.__name__} 模型。")
# Train the model if loading fails
model = agent.get_model(
model_name=model_class.__name__.lower(),
model_kwargs=info["params"])
trained_model = agent.train_model(
model=model,
tb_log_name=model_class.__name__.lower(),
total_timesteps=info["total_timesteps"])
trained_model.save(model_path)
trained_models[model_class.__name__] = trained_model
print(f"{model_class.__name__} 模型已訓練並保存到 {model_path}")
else:
print(f"正在訓練 {model_class.__name__} 模型...")
model = agent.get_model(model_name=model_class.__name__.lower(),
model_kwargs=info["params"])
trained_model = agent.train_model(
model=model,
tb_log_name=model_class.__name__.lower(),
total_timesteps=info["total_timesteps"])
trained_model.save(model_path)
trained_models[model_class.__name__] = trained_model
print(f"{model_class.__name__} 模型已訓練並保存到 {model_path}")
return trained_models
def backtest_drl(e_trade_gym, trained_models):
"""
Function to backtest all trained DRL models.
Parameters:
- e_trade_gym: The trading environment for backtesting.
- trained_models: Dictionary of trained models.
Returns:
- backtest_results: Dictionary containing daily returns and actions for each model.
"""
# 初始化 backtest 結果的字典
backtest_results = {}
# 對每個模型進行回測
for model_name, model in trained_models.items():
print(f"正在對 {model_name} 模型進行回測...")
# 使用該模型進行預測
df_daily_return, df_actions = DRLAgent.DRL_prediction(
model=model, environment=e_trade_gym)
# 儲存回測結果
backtest_results[model_name] = {
'daily_return': df_daily_return,
'actions': df_actions
}
# 輸出回測的前幾行結果作為確認
print(f"{model_name} 模型的每日回報:")
print(df_daily_return.head())
print(f"{model_name} 模型的動作:")
print(df_actions.head())
return backtest_results
def plot_html(trace_list, time_ind):
fig = go.Figure()
for trace in trace_list:
fig.add_trace(trace)
fig.update_layout(legend=dict(x=0,
y=1,
traceorder="normal",
font=dict(family="sans-serif",
size=15,
color="black"),
bgcolor="White",
bordercolor="white",
borderwidth=2), )
#fig.update_layout(legend_orientation="h")
fig.update_layout(
title={
#'text': "Cumulative Return using FinRL",
'y': 0.85,
'x': 0.5,
'xanchor': 'center',
'yanchor': 'top'
})
#with Transaction cost
#fig.update_layout(title = 'Quarterly Trade Date')
fig.update_layout(
# margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor='rgba(1,1,0,0)',
plot_bgcolor='rgba(1, 1, 0, 0)',
#xaxis_title="Date",
yaxis_title="Cumulative Return",
xaxis={
'type': 'date',
'tick0': time_ind[0],
'tickmode': 'linear',
'dtick': 86400000.0 * 80
})
fig.update_xaxes(showline=True,
linecolor='black',
showgrid=True,
gridwidth=1,
gridcolor='LightSteelBlue',
mirror=True)
fig.update_yaxes(showline=True,
linecolor='black',
showgrid=True,
gridwidth=1,
gridcolor='LightSteelBlue',
mirror=True)
fig.update_yaxes(zeroline=True,
zerolinewidth=1,
zerolinecolor='LightSteelBlue')
fig.show()
def plot_cumulative_returns(backtest_results,
time_ind,
min_var_daily_return=None,
dji_daily_return=None):
"""
Function to plot cumulative returns for DRL models, Min-Variance, and DJI.
Parameters:
- backtest_results: Dictionary containing daily returns for different DRL models.
- time_ind: Pandas Series of dates (x-axis values).
- min_var_daily_return: (Optional) Daily returns for the Min-Variance model. Default is None.
- dji_daily_return: (Optional) Daily returns for the DJI index. Default is None.
"""
# Initialize the figure
trace_list = []
# Loop through backtest results and add traces for each model's cumulative returns
for model_name, result in backtest_results.items():
df_daily_return = result['daily_return']
# 計算累積回報 (Cumulative Returns)
cumpod = (df_daily_return['daily_return'] + 1).cumprod() - 1
# Add trace for each model's cumulative return
trace = go.Scatter(x=time_ind,
y=cumpod,
mode='lines',
name=f'{model_name} (Portfolio Allocation)')
trace_list.append(trace)
# Conditionally add Min-Variance cumulative return trace if provided
if min_var_daily_return is not None:
# 計算MVO累積回報
min_var_cumpod = (min_var_daily_return + 1).cumprod() - 1
trace_min_var = go.Scatter(x=time_ind,
y=min_var_cumpod,
mode='lines',
name='Min-Variance')
trace_list.append(trace_min_var)
# Conditionally add DJI cumulative return trace if provided
if dji_daily_return is not None:
# 計算DJI累積回報
dji_cumpod = (dji_daily_return + 1).cumprod() - 1
trace_dji = go.Scatter(x=time_ind,
y=dji_cumpod,
mode='lines',
name='DJIA')
trace_list.append(trace_dji)
plot_html(trace_list, time_ind)
def generate_quantstats_report(daily_return_df, output_filename, title):
"""
Function to generate a QuantStats HTML report.
Parameters:
- daily_return_df: Pandas DataFrame containing 'date' and 'daily_return' columns.
- output_filename: The name of the output HTML file for the report.
- title: The title for the report.
Returns:
- None. The report will be saved as an HTML file.
"""
# 確保 'date' 列是 datetime 格式,並將其設置為索引
daily_return_df['date'] = pd.to_datetime(daily_return_df['date'])
daily_return_df.set_index('date', inplace=True)
# 確保 'daily_return' 是 pandas Series
daily_return_series = daily_return_df['daily_return']
# 使用 quantstats 生成 HTML 報告,將其保存為文件
qs.reports.html(daily_return_series, output=output_filename, title=title)
qs.reports.plots(daily_return_series)
print(f"Quantstats HTML 報告已生成並保存為 '{output_filename}'。")
def calculate_dji_daily_return(start_date, end_date):
"""
Calculate daily returns for the DJI index.
Parameters:
- start_date: The start date for fetching DJI data.
- end_date: The end date for fetching DJI data.
Returns:
- baseline_returns: Pandas Series containing daily returns for the DJI index.
"""
from finrl.plot import get_baseline, get_daily_return
# Fetch baseline DJI data
baseline_df = get_baseline(ticker='^DJI', start=start_date, end=end_date)
# Calculate daily returns for DJI
baseline_returns = get_daily_return(baseline_df, value_col_name="close")
return baseline_returns
def calculate_daily_rebalanced_mvo_portfolio(df,
unique_trade_dates,
initial_capital=1000000):
"""
通过每日再平衡计算最小方差组合(MVO)。
参数:
- df:包含股票数据的 DataFrame,需要包含 'date'、'tic'、'close' 和 'return_list' 列。
- unique_trade_dates:交易日期的列表或数组。
- initial_capital:初始资金,默认为 1,000,000。
返回:
- portfolio:包含账户价值随时间变化的 DataFrame。
"""
from pypfopt.efficient_frontier import EfficientFrontier
import numpy as np
# 初始化投资组合 DataFrame
portfolio = pd.DataFrame(index=range(1), columns=unique_trade_dates)
portfolio.loc[0, unique_trade_dates[0]] = initial_capital
# 遍历交易日期,计算每日投资组合价值
for i in range(len(unique_trade_dates) - 1):
current_date = unique_trade_dates[i]
next_date = unique_trade_dates[i + 1]
# 获取当前日期和下一日期的数据
df_current = df[df.date == current_date].reset_index(drop=True)
df_next = df[df.date == next_date].reset_index(drop=True)
# 计算当前日期的协方差矩阵
Sigma = df_current['return_list'][0].cov()
# 使用最小化波动率的方法计算权重
ef = EfficientFrontier(None, Sigma, weight_bounds=(0, 0.1))
ef.min_volatility()
cleaned_weights = ef.clean_weights()
# 计算每个资产的资金分配和持有数量
cap = portfolio.iloc[0, i]
weights = np.array(list(cleaned_weights.values()))
current_cash_allocation = weights * cap
current_prices = df_current['close'].values
current_shares = current_cash_allocation / current_prices
# 计算下一日期的投资组合价值
next_prices = df_next['close'].values
portfolio_value_next = np.dot(current_shares, next_prices)
# 存储投资组合价值
portfolio.iloc[0, i + 1] = portfolio_value_next
# 转置 DataFrame 并命名列
portfolio = portfolio.T
portfolio.columns = ['account_value']
return portfolio
def calculate_daily_return_from_portfolio(portfolio):
"""
Calculate daily returns from a portfolio's account value.
Parameters:
- portfolio: DataFrame containing the portfolio's account value over time.
Returns:
- daily_return: Pandas Series containing daily returns.
"""
# 確保 'account_value' 列存在於 portfolio 中
if 'account_value' not in portfolio.columns:
raise ValueError("Portfolio must contain 'account_value' column")
# 計算每日回報
daily_return = portfolio['account_value'].pct_change().dropna()
return daily_return
def calculate_cov_list(df, lookback=252):
"""
Calculate cov_list and return_list from price data.
Parameters:
- df: The dataframe containing the price data.
- lookback: The lookback period for calculating the covariance (default is 252, which represents a year).
Returns:
- df: DataFrame with the calculated cov_list and return_list.
"""
df = df.sort_values(['date', 'tic'], ignore_index=True)
df.index = df.date.factorize()[0]
cov_list = []
return_list = []
for i in range(lookback, len(df.index.unique())):
data_lookback = df.loc[i - lookback:i, :]
price_lookback = data_lookback.pivot_table(index='date',
columns='tic',
values='close')
return_lookback = price_lookback.pct_change().dropna()
return_list.append(return_lookback)
# 計算協方差矩陣
covs = return_lookback.cov().values
cov_list.append(covs)
# 將協方差矩陣加入 df
df_cov = pd.DataFrame({
'date': df.date.unique()[lookback:],
'cov_list': cov_list,
'return_list': return_list
})
df = df.merge(df_cov, on='date')
df = df.sort_values(['date', 'tic']).reset_index(drop=True)
return df
def main():
from finrl import config
from finrl import config_tickers
from finrl.meta.data_processors.processor_yahoofinance import YahooFinanceProcessor
from finrl.meta.env_portfolio_allocation.env_portfolio import StockPortfolioEnv
from finrl.meta.preprocessor.preprocessors import FeatureEngineer, data_split
# 設定環境
TIME_INTERVAL = '1D'
START_DATE = '2008-01-01'
END_DATE = '2021-10-31'
RAW_DATA_PATH = f'./datasets/DOW30_{TIME_INTERVAL}_{START_DATE}_to_{END_DATE}.csv'
TRAIN_START_DATE = '2009-01-01'
TRAIN_END_DATE = '2019-12-31'
TRADE_START_DATE = '2020-01-01'
## Part 3. Download Data
print(config_tickers.DOW_30_TICKER)
if not os.path.exists(RAW_DATA_PATH):
dp = YahooFinanceProcessor()
df = dp.download_data(start_date=START_DATE,
end_date=END_DATE,
ticker_list=config_tickers.DOW_30_TICKER,
time_interval=TIME_INTERVAL)
df.to_csv(RAW_DATA_PATH)
else:
df = pd.read_csv(RAW_DATA_PATH)
if 'date' not in df.columns and 'timestamp' in df.columns:
df = df.rename(columns={'timestamp': 'date'})
### 特徵工程
"""
後面初始化StockPortfolioEnv時 "tech_indicator_list": config.INDICATORS
會需要指定使用的技術指標,
所以這裡先對數據進行特徵工程, 取得技術指標
"""
fe = FeatureEngineer(use_technical_indicator=True,
use_turbulence=False,
user_defined_feature=False)
df = fe.preprocess_data(df)
# 計算協方差矩陣
df = calculate_cov_list(df)
# 獲取訓練數據 (假設你已經準備好數據)
# 注意,你需要根據實際情況調用數據處理過程,例如 data_split 或其他
train, trade = data_split(df, TRAIN_START_DATE,
TRAIN_END_DATE), data_split(
df, TRADE_START_DATE, END_DATE)
# 定義環境參數
stock_dimension = len(train.tic.unique())
state_space = stock_dimension
print(f"Stock Dimension: {stock_dimension}, State Space: {state_space}")
env_kwargs = {
"hmax": 100,
"initial_amount": 1000000,
"transaction_cost_pct": 0.001,
"state_space": state_space,
"stock_dim": stock_dimension,
"tech_indicator_list": config.INDICATORS,
"action_space": stock_dimension,
"reward_scaling": 1e-4
}
# 初始化環境
e_train_gym = StockPortfolioEnv(df=train, **env_kwargs)
# 定義模型類別映射和參數
models_info = {
A2C: {
"params": {
"n_steps": 5,
"ent_coef": 0.005,
"learning_rate": 0.0002
},
"total_timesteps": 50000,
"save_path": './training/portfolio_allocation/trained_a2c.zip'
},
PPO: {
"params": {
"n_steps": 2048,
"ent_coef": 0.005,
"learning_rate": 0.0001,
"batch_size": 128,
},
"total_timesteps": 80000,
"save_path": './training/portfolio_allocation/trained_ppo.zip'
},
DDPG: {
"params": {
"batch_size": 128,
"buffer_size": 50000,
"learning_rate": 0.001
},
"total_timesteps": 50000,
"save_path": './training/portfolio_allocation/trained_ddpg.zip'
},
SAC: {
"params": {
"batch_size": 128,
"buffer_size": 100000,
"learning_rate": 0.0003,
"learning_starts": 100,
"ent_coef": "auto_0.1",
},
"total_timesteps": 50000,
"save_path": './training/portfolio_allocation/trained_sac.zip'
},
TD3: {
"params": {
"batch_size": 100,
"buffer_size": 1000000,
"learning_rate": 0.001
},
"total_timesteps": 30000,
"save_path": './training/portfolio_allocation/trained_td3.zip'
}
}
### get baseline
dji_daily_return = calculate_dji_daily_return(TRADE_START_DATE, END_DATE)
unique_trade_date = trade['date'].unique()
mvo_portfolio = calculate_daily_rebalanced_mvo_portfolio(
df, unique_trade_date)
mvo_daily_return = calculate_daily_return_from_portfolio(mvo_portfolio)
# 訓練模型
trained_models = train_drl(e_train_gym, models_info)
# 初始化交易環境
e_trade_gym = StockPortfolioEnv(df=trade, **env_kwargs)
# 進行回測
backtest_results = backtest_drl(e_trade_gym, trained_models)
# 假設 backtest_results 來自 backtest_drl 函數
trade['date'] = pd.to_datetime(trade['date'])
time_ind = pd.Series(trade['date'].unique()).sort_values()
plot_cumulative_returns(backtest_results,
time_ind,
min_var_daily_return=mvo_daily_return,
dji_daily_return=dji_daily_return)
print(backtest_results)
# 假設你想用 PPO 模型的回報生成 quantstats 報告
ppo_daily_return = backtest_results['PPO']['daily_return']
generate_quantstats_report(ppo_daily_return, "PPO_performance_report.html",
"PPO Performance Report")
if __name__ == "__main__":
main()


 iThome鐵人賽
iThome鐵人賽