在第二天的時候有分享MongoDB Atlas作為這次主題的向量資料庫,或許你可能會想說MongoDB 原始設計本就不是專用於向量和進行向量資料查找而設計的資料庫。但是近幾年MongoDB 推出了Vector Search服務,就算儲存架構不是專門設計於儲存向量,但是能在這種非結構化結構儲存向量並且擁有向量查詢的功能勢必擁有一定的優勢。
因此今天將要來介紹如何在MongoDB Atlas當中透過Compass建置Vector Search。因為目前我已經沒有OpenAI 的資源去進行Embedding,所以這邊我著重分享過去使用的方法。主要有以下步驟:
先進行資源的載入
import os
from dotenv import load_dotenv
from pymongo import MongoClient
#通常會將所有endpoint 或者API_KEY額外儲存在電腦中的.env檔案
#主要是為了不要讓連線資訊外流,同時也是為了方便管理
load_dotenv('.env')
api_key=os.getenv("AZURE_OPENAI_API_KEY")
api_version="2024-02-01"
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT")
print('api_key:', api_key)
print('azure_endpoint:', azure_endpoint)
#因為當時我們在開發測試時主要都是用LangChain架構去撰寫,所以這邊也直接使用LangChain提供的AOAI連接套件
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
from pymongo import MongoClient
# AOAI resources
aoai_embeddings = AzureOpenAIEmbeddings(
api_key=api_key,
azure_endpoint=azure_endpoint,
openai_api_version=api_version,
azure_deployment="text-embedding-ada-002",
disallowed_special=()
)
#MongoDB resource
connecting_string = "your_connection_string"
client = MongoClient(connecting_string)
db = client['practice_CRUD']
collection = db['contexts'] #我們將chunks開立一個新的collection儲存
接著就是取出document當中的content資料,然後傳遞給embedding model 去轉換。
# 遍歷每個文件,嵌入並更新
for document in collection.find():
content = document['content']
# 獲取嵌入向量
embedding = aoai_embeddings.embed(content)
# 更新文件,新增 'embedding' 字段
collection.update_one(
{'_id': document['_id']},
{'$set': {'embedding': embedding}}
)
最後就是到Compass當中建立好Search Index就準備好Vector Search的前置作業了!(假設經過上面步驟就完成了每一個document的 content embedding的動作)
{
"_id": {
"$oid": "66eecfb8c1540b40d68a46ad"
},
"chunk_id": 1,
"content": "Fed降息影響有哪些?Q4投資布局一次看 | 遠見雜誌 訂閱 成為遠見會員 免費瀏覽更多專題好文 快速註冊 已是會員,立即登入 為您推薦 加入會員獨享優惠 最新 最新專題報導 話題 政治 時事 人物 總經 國際 全球焦點 兩岸 金融 投資理財 保險規劃 退休理財",
"embedding": [
0.123456, 0.654321, ..., 0.789012
]
}
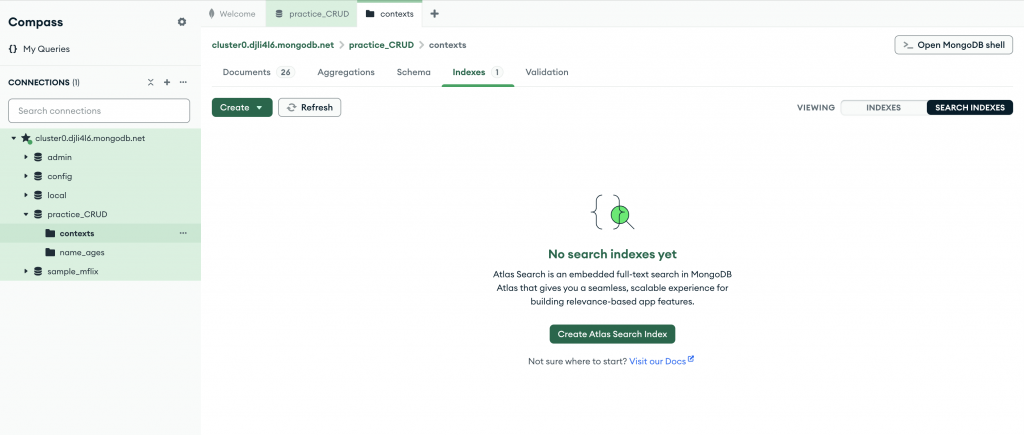
切換到Indexes分頁中,並且切換到Search Indexes模式。然後建立如下設定。這裡為什麼指定numDimensions是1536? 因為我們是使用OpenAI 的text-embedding-ada-002模型去將文字轉換成向量,所以需要告知說我們轉換後的向量維度為多少。
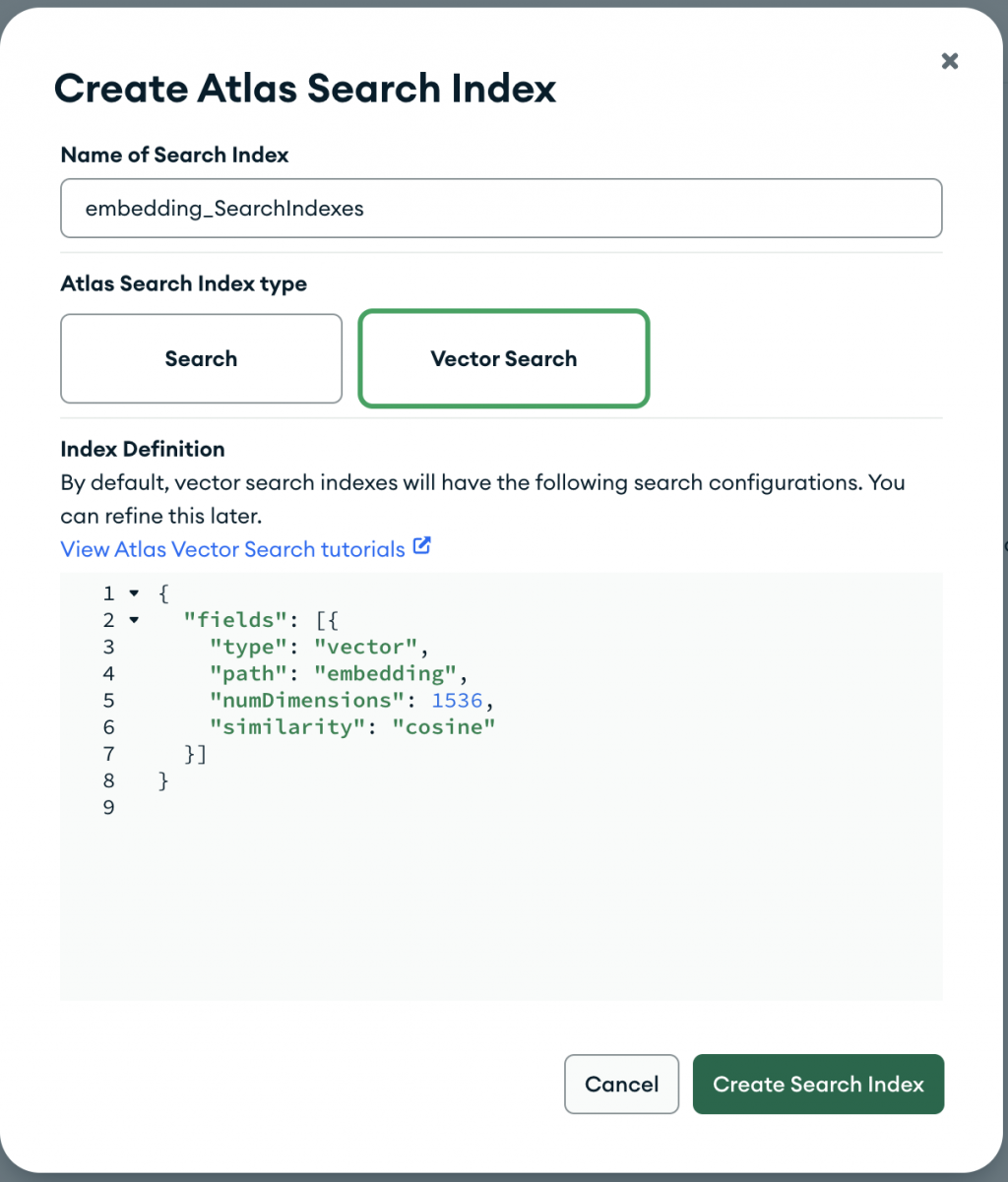

建立好之後,稍等一下並且Refresh一下Compass。最後就會看到這項Indexes已經Ready啦!所有的Vector Search前置作業就結束了,接下來就即將要開始使用RAG技術來開發我們的聊天機器人!

