今天要分享:使用LangChain 的架構去製作RAG的聊天機器人,這邊主要會使用flask的開發框架來搭建後台。因為Flask的使用相對簡單,而且在未來只要對RAG實作有興趣的同學甚至可以將Flask搭建起來的Server去和常見的聊天室串接,像是LineBot。
from dotenv import load_dotenv
from pymongo import MongoClient
import os
# 載入環境變數
load_dotenv(".env")
# 連接mongoDB
client = MongoClient('your_connection_string')
db = client['practice_CRUD']
collection = db['contexts'] #我們將chunks開立一個新的collection儲存
vector_search_index = 'embedding_SearchIndexes' #先指定在MongoDB 當中建立的Vector Search Index名稱
app = Flask(__name__)#此為Flask預設的程式碼
api_key=os.getenv("AZURE_OPENAI_API_KEY")
api_version="2024-02-01"
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT")
# 配置 Azure OpenAI 聊天功能
llm = AzureChatOpenAI(
api_key=api_key,
azure_endpoint=azure_endpoint,
openai_api_version="2024-02-01",
azure_deployment="gpt-4o"
)
# 配置 Azure OpenAI 嵌入功能
aoai_embeddings = AzureOpenAIEmbeddings(
api_key=api_key,
azure_endpoint=azure_endpoint,
openai_api_version="2024-02-01",
azure_deployment="text-embedding-ada-002",
disallowed_special=()
)
@app.route('/query_langchain', methods=['POST'])
def query_langchain():
data = request.json
question = data.get('query', '')
vector_store = MongoDBAtlasVectorSearch(
collection=collection, #告知要使用的是哪一個資料夾進行資料搜索
embedding=aoai_embeddings, #告知要使用哪種向量化模型
index_name=vector_search_index, #index名稱
text_key="content" #這裡需要指定document文字的key。經過similarity找到相似的document後,會返回這個key的值
)
#初始化要進行檢索的方式,5是代表只會返回前五名相似的資訊
qa_retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5},
)
system_prompt= ("使用以下上下文來回答問題。如果你不知道答案,就說你不知道,不要試圖編造答案。"
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),("human", question)
]
)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
chain = create_retrieval_chain(
qa_retriever, question_answer_chain
)
# 使用chain
result = chain.invoke({"input": question})
return jsonify({"response": 'Success', 'status': '200', 'answer': result['answer']})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
註:昨天有提到兩種prompt,一種是只有系統看得到的SystemPrompt,另一種是使用者輸入想要詢問LLM的敘述,也就是human所代表的UserPrompt。
以上就是建立簡易版RAG的後端程式碼!如果想要嘗試的朋友,可以直接在自己電腦運行起來這個flask server。如果需要互動介面,可以串接linebot喔!
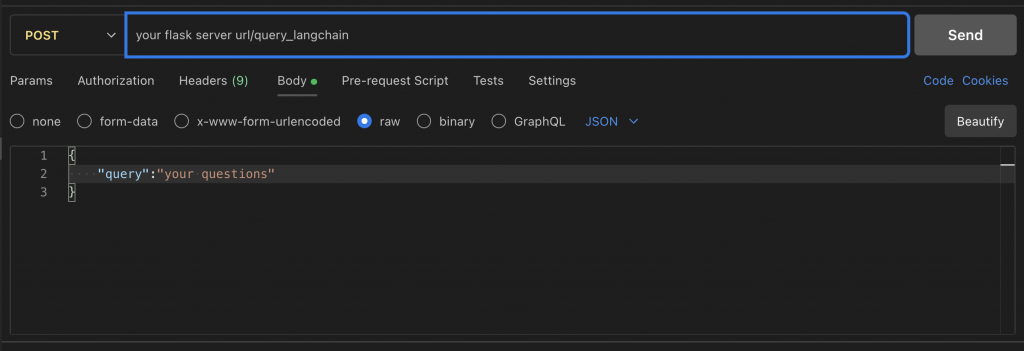
運行Flask Server之後,我自己是使用Postman去對url提出Post來去驗證運作是否成功。這邊也提供一下使用Postman的方法,我是直接在VScode裡面的extention使用。