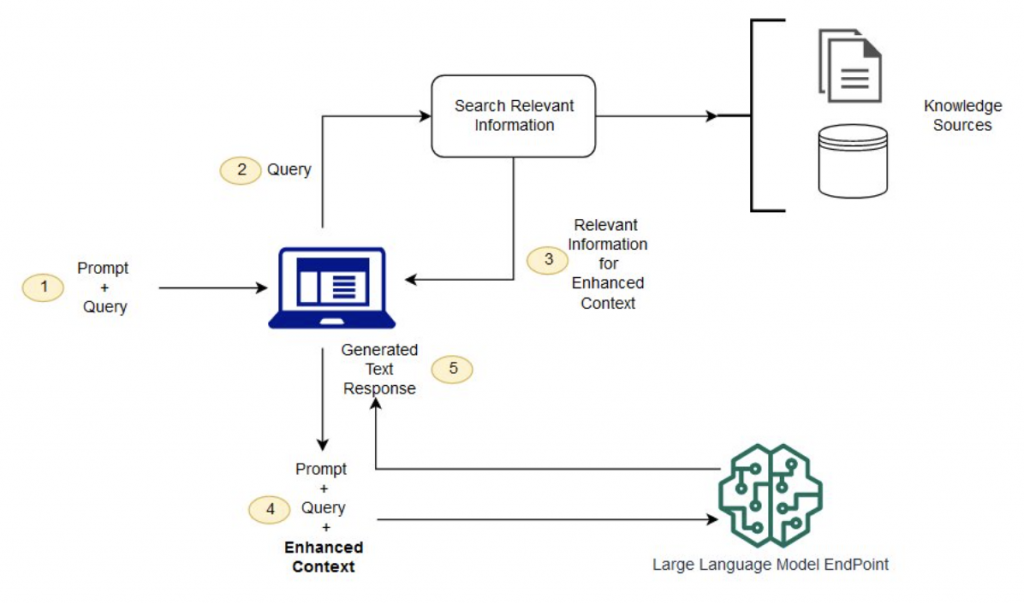
今天主要介紹RAG當中的最基礎版本,在使用者問題或檢索的過程中都是使用之前所提到的最初概念,文字切段並且向量化;利用cosine similarity來查詢相關資訊;同步傳遞相關資料給LLM去進行回答使用者問題。
這整個流程算是最初代的RAG,這版RAG看似邏輯完美,但是其實在檢索和提供給LLM的參考資訊都存在一點問題。
例如:
以上這些問題都是各專家在進行實驗時發現的問題,所以Naive RAG基本上只能說是RAG的Prototype,如果要進行客製化的使用可能會遇到一些問題。因此後續就有Advanced RAG的提出,嘗試去解決這些方面的問題。關於Advanced RAG的解決方案之後也會介紹一些,如果有興趣的同學可以繼續關注。
總結一下今天的內容,主要分享RAG的基礎版本。結合之前的分享,現在我們可以知道為什麼前面分享了MongoDB Atlas的功能和設定。明天將會分享如何使用LangChain模組迅速搭建出結合RAG的聊天機器人後端架構。