在完成初步數據清洗後,我們將實作特徵工程中的特徵創建、特徵轉換和特徵縮放。這些步驟將幫助我們將數據轉化為更適合模型的格式,並確保特徵在相同的度量上進行比較。
在觀察特徵時,發現雖然入院日期和出院日期不直接影響檢測結果,但筆者決定嘗試將住院長度作為一個新特徵,這樣模型或許能夠從中學到有價值的資訊。
# 檢查日期欄位的數據類型
cleaning_data_filtered.dtypes
結果如下: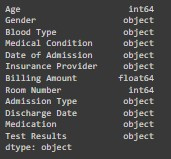
可以看到,Admission Date 和 Discharge Date 的數據類型為 object。我們需要將這些欄位轉換為 datetime 類型。
# 將日期列轉換為 datetime 類型
cleaning_data_filtered['Date of Admission'] = pd.to_datetime(cleaning_data_filtered['Date of Admission'])
cleaning_data_filtered['Discharge Date'] = pd.to_datetime(cleaning_data_filtered['Discharge Date'])
# 計算住院長度
cleaning_data_filtered['Length of Stay'] = (cleaning_data_filtered['Discharge Date'] - cleaning_data_filtered['Date of Admission']).dt.days
cleaning_data_filtered
結果:
清理後的數據包含了新增的 Length of Stay 欄位,顯示了每位病患的住院天數。這樣可以為模型提供額外的特徵,可能有助於提高預測準確性。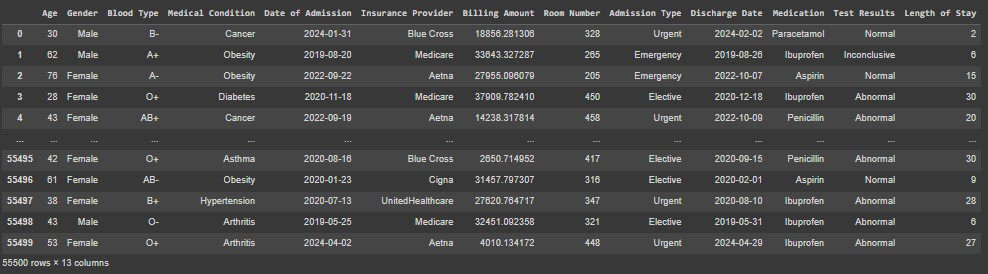
由於我們使用了入院及出院日期創建新特徵,因此為了避免高度相關特徵而使模型增加權重,我們將入院日期及出院日期特徵移除。做法如下:
cleaning_data_filtered.drop(['Date of Admission', 'Discharge Date'], axis=1, inplace=True)
在處理類別型數據時,由於模型無法直接理解文字,我們需要將這些特徵進行轉換。首先,我們要識別數據中的類別型特徵。在我們的數據集中,Gender、Blood Type、Medical Condition、Insurance Provider、Admission Type 和 Medication 都屬於類別型特徵。
接下來,我們需要區分這些類別型特徵是否有順序性。有序類別特徵(如評級或階段)可以使用 Label Encoding 進行編碼;無序類別特徵(如性別或血型)則適合使用 One-Hot Encoding 來避免引入順序性假設。在此數據集中,看起來所有特徵都是無序的,因此所有這些特徵都會做 One hot encoding 以下是具體的處理方法:
from sklearn.preprocessing import OneHotEncoder
# 對無序類別進行 One-Hot Encoding
cleaning_data_filtered = pd.get_dummies(cleaning_data_filtered, columns=['Gender', 'Blood Type', 'Medical Condition', 'Insurance Provider', 'Admission Type', 'Medication'], drop_first=True)
由於 One hot encoding 特徵轉換會新增特徵,因此此時我們的數據 column 將從 11 欄增加到 28 欄。
Note:此 Kaggle 數據集沒有有序的,所以特徵不需 Label Encoder, 但要預測的 Output 是要做 Label Encoder 的,通常會將文字輸出成 0 或 1 的標示,程式碼如下:
from sklearn.preprocessing import LabelEncoder
# 對有序類別進行 Label Encoding
label_encoder = LabelEncoder()
cleaning_data_filtered['Test Results'] = label_encoder.fit_transform(cleaning_data_filtered['Test Results'])
在數值型的數據需要考量到特徵縮放問題,因為不同特徵的取值範圍可能會相差甚大,這可能導致模型訓練時過於關注某些特徵,而忽略其他特徵。在我們的數據集中,數值型數據包含 Age, Billing Amount, Room Number, Length of Stay。看數據分布,我們發現:
Age (範圍: 23-83):這個範圍相對較小,但即使範圍不大,標準化可以確保它在與其他特徵一起使用時不會對模型產生過大的影響。可以使用 Standard Scaling 或 Min-Max Scaling。Billing Amount (範圍: 100-9997):這個範圍相當大,因此強烈建議進行縮放,以防止模型過度關注這個特徵。建議使用 Min-Max Scaling,將數值縮放到一個較小的範圍內(如 0 到 1)。Room Number (範圍: 115-445):雖然範圍比 Age 大,但還是較小且有序的,可以選擇是否縮放。如果它不是數值意義很強的特徵,可以考慮不縮放,但如果認為這個特徵有意義,可以使用 Standard Scaling 或 Min-Max Scaling。Length of Stay (範圍: 1-30):這個範圍較小,但也建議縮放,因為這樣可以保持一致性。可以使用 Standard Scaling 或 Min-Max Scaling。筆者決定將所有數值型特徵用 Min-Max Scaling,主要原因是希望可以統一縮放到 [0, 1] 之間,且 Min-Max Scaling 適合在數據沒有明顯分佈及希望保留數據的分佈形狀時使用。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(cleaning_data_filtered[['Age', 'Billing Amount', 'Room Number', 'Length of Stay']])
cleaning_data_filtered[['Age', 'Billing Amount', 'Room Number', 'Length of Stay']] = scaled_data
Note:如果需要使用 Standard Scaling,以下是相應的代碼示例:
from sklearn.preprocessing import StandardScaler
# 使用 Standard Scaler 進行特徵縮放
scaler = StandardScaler()
scaled_data = scaler.fit_transform(cleaning_data_filtered[['Age', 'Billing Amount', 'Room Number', 'Length of Stay']])
cleaning_data_filtered[['Age', 'Billing Amount', 'Room Number', 'Length of Stay']] = scaled_data
一旦選擇了縮放器並進行了縮放,記得保存縮放器,將縮放器(scaler)保存成 pickle 檔案是一個好做法。這樣,你可以在模型部署或進行新數據預處理時,使用相同的縮放器來保持數據的一致性。
import pickle
from google.colab import files
# 保存縮放器
with open('minmax_scaler.pkl', 'wb') as f:
pickle.dump(scaler, f)
# 下載 minmax_scaler.pkl 檔案
files.download('minmax_scaler.pkl')
在本篇文章中,我們探討了特徵創建、轉換和縮放的實踐過程。首先,我們從原始數據中創建了新的特徵,如住院長度,以提高模型的預測能力。接著,對類別型特徵進行了 One-Hot Encoding,將其轉換為模型可以處理的格式。最後,對數值型特徵進行了 Min-Max Scaling,以確保特徵在相同的度量上進行比較,並避免模型過度關注某些特徵。
在下一篇文章中,我們將深入探討特徵選擇和數據切分的方法。特徵選擇的目的是識別對模型預測最有幫助的特徵,而數據切分則是將數據分為訓練集和測試集,以評估模型的性能。這些步驟對於構建有效的機器學習模型很重要。

