前面介紹了各種跟數值有關或是 Database 的常見 Data Source,但 Grafana 也能夠查詢例如 Logs、Traces、Profiling 等資訊,為更深入的系統監控與診斷提供了統一的平台。
Loki 是由 Grafana Labs 於 2018 年開源的 Log 收集系統,特點是輕量、易用、成本低、高可用且易於擴展。Loki 借鑑了 Prometheus 的設計,對時間和 Label 進行索引以提高查詢效率,並參考 PromQL 設計了 Loki 專屬的 LogQL。
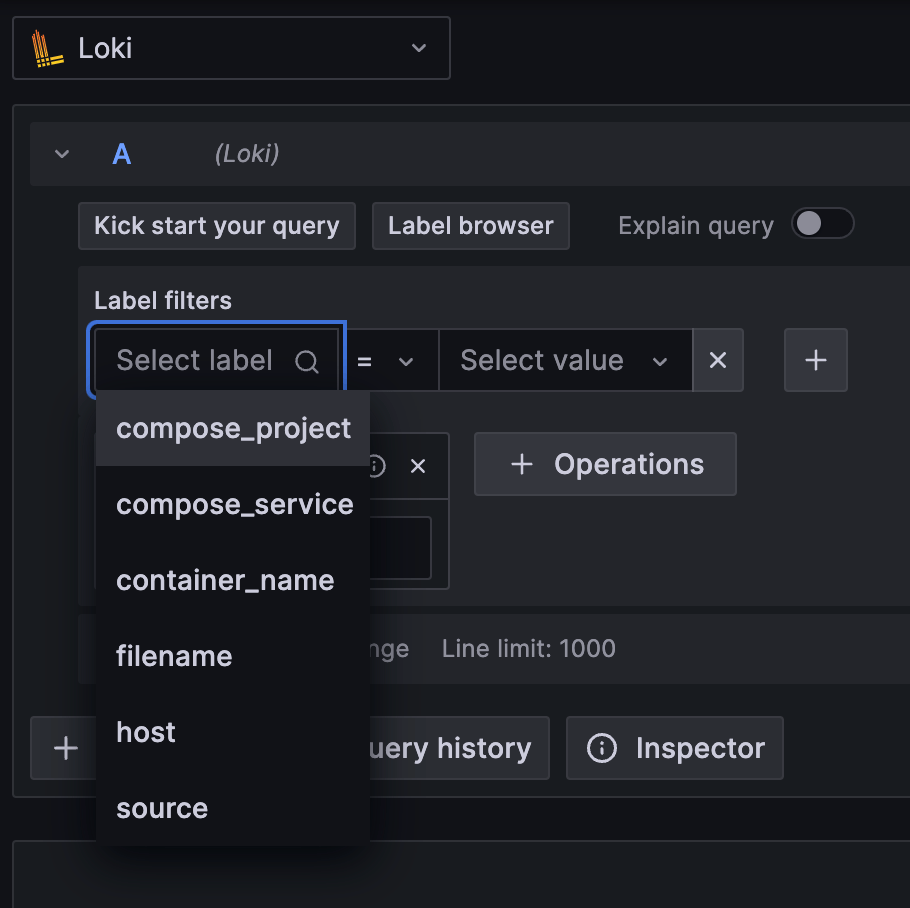
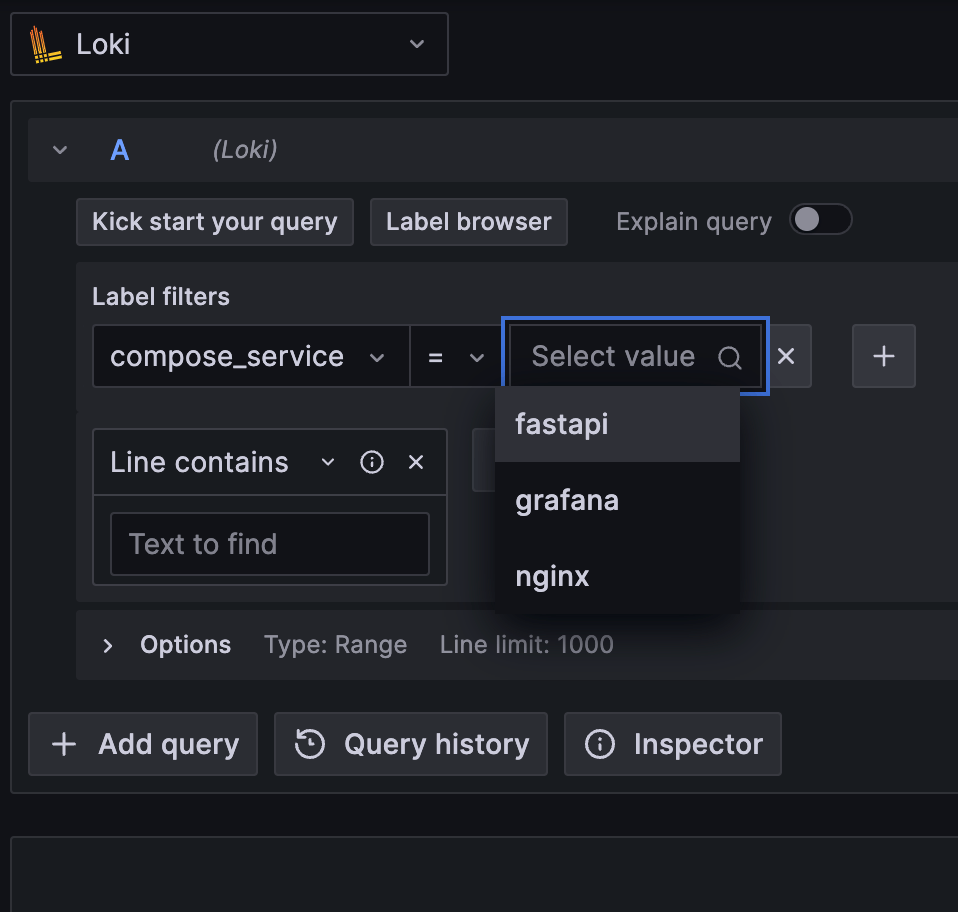
Loki 查詢主要透過 Label 與 Label 值進行初步篩選
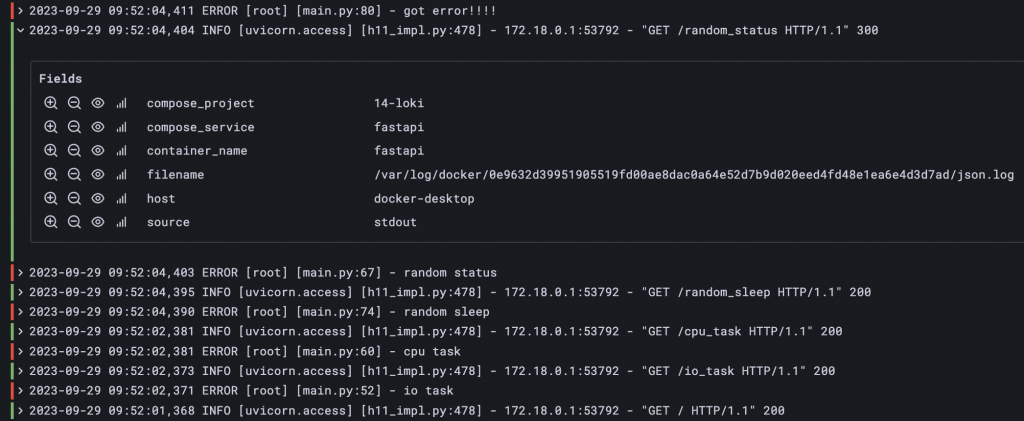
Loki 的查詢介面,展開可以查看每筆 Log 的 Label 與其值
範例 Lab 可以參考 https://github.com/blueswen/observability-ironman30-lab/tree/main/14-loki
在現代分散式系統中,追蹤和排查效能瓶頸是一項艱鉅的挑戰,然而透過分散式追蹤 (Distributed Tracing) 技術,可以快速有效地定位問題。分散式追蹤允許我們追蹤請求流經的多個系統,並了解在哪個環節發生延遲或失敗。例如,當使用者執行 Single Sign-On(SSO)時,後續可能涉及多個系統與服務,如 Redis、Google SSO Service 和 PostgreSQL。如果出現登入延遲或失敗,分散式追蹤能幫助我們迅速找出是 Redis 連線逾時、Google SSO 回應過慢,還是資料庫壅塞的原因,從而提升故障排除的效率。
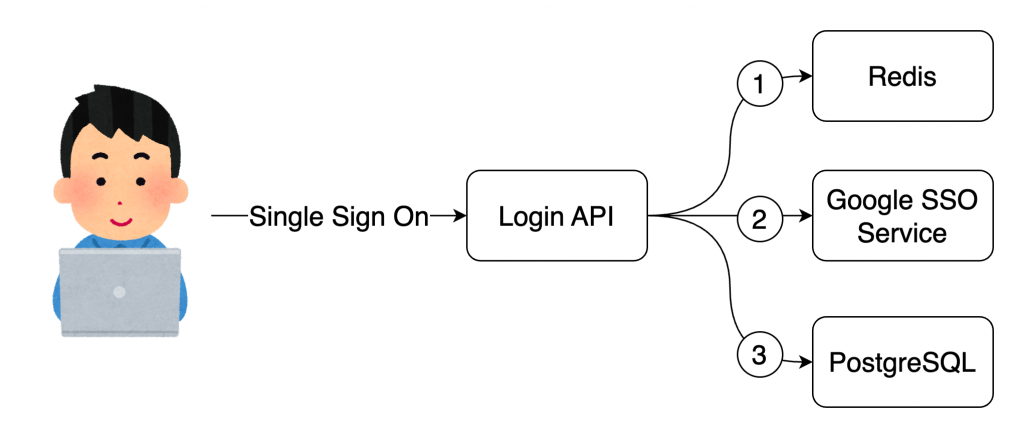
一個 SSO 會涉及多個服務
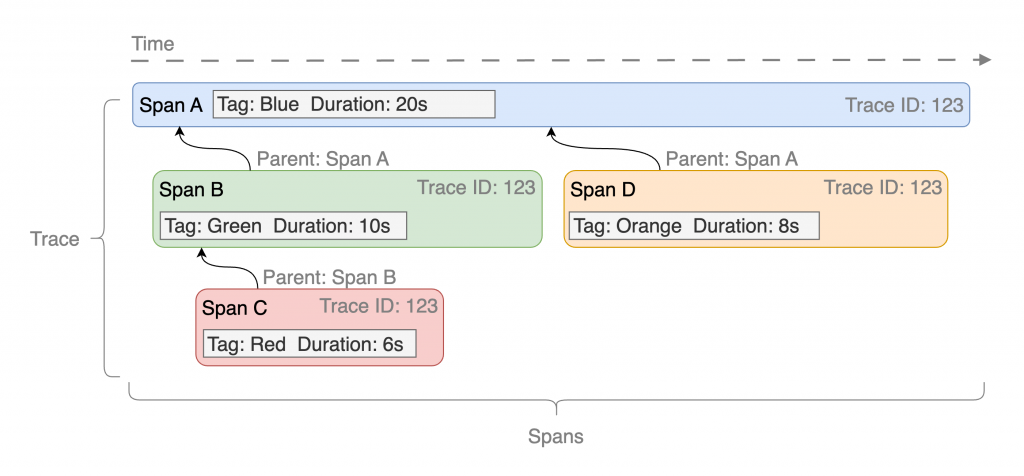
Trace 由多個 Span 組成,每個 Span 代表一個操作,紀錄開始時間、結束時間、耗時、操作名稱、Tag 等資訊
目前主流的 Trace 規範是 OpenTelemetry,他是在 2019 年由兩個同樣是專注於 Trace 的專案 OpenCensus 和 OpenTracing 合併而成。OpenTelemetry 除了訂定統一的 API 外,也提供各種語言的 SDK 用於產生 Trace 資料送至儲存 Trace 的後端服務。
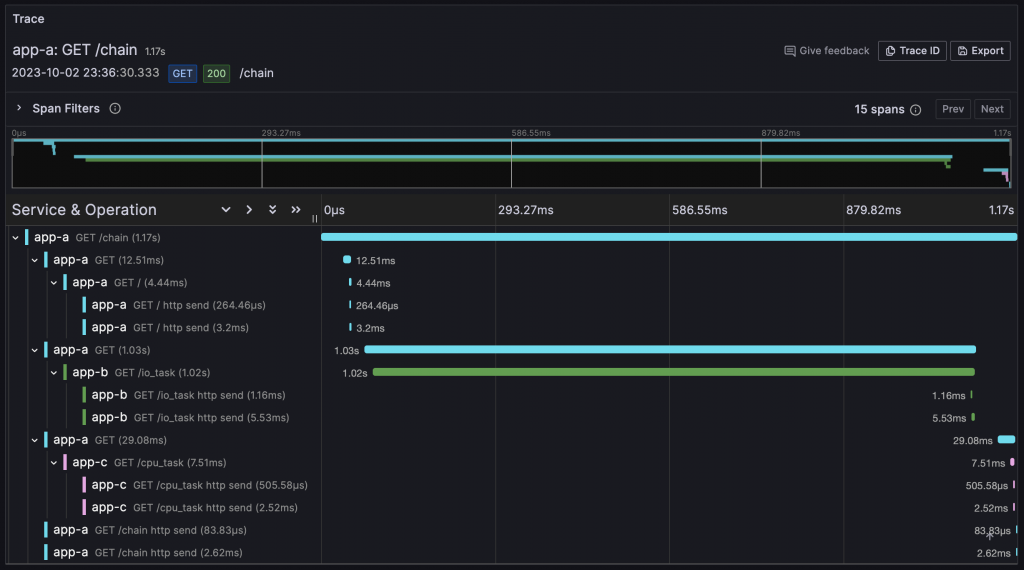
在 Grafana 中查看 Trace 資訊
Jaeger 是 Uber 由開源的分散式追蹤工具,支援 OpenTelemetry 的資料格式,有完整的收集機制與查詢介面,但也可以單純作為儲存 Trace 的後端服務。
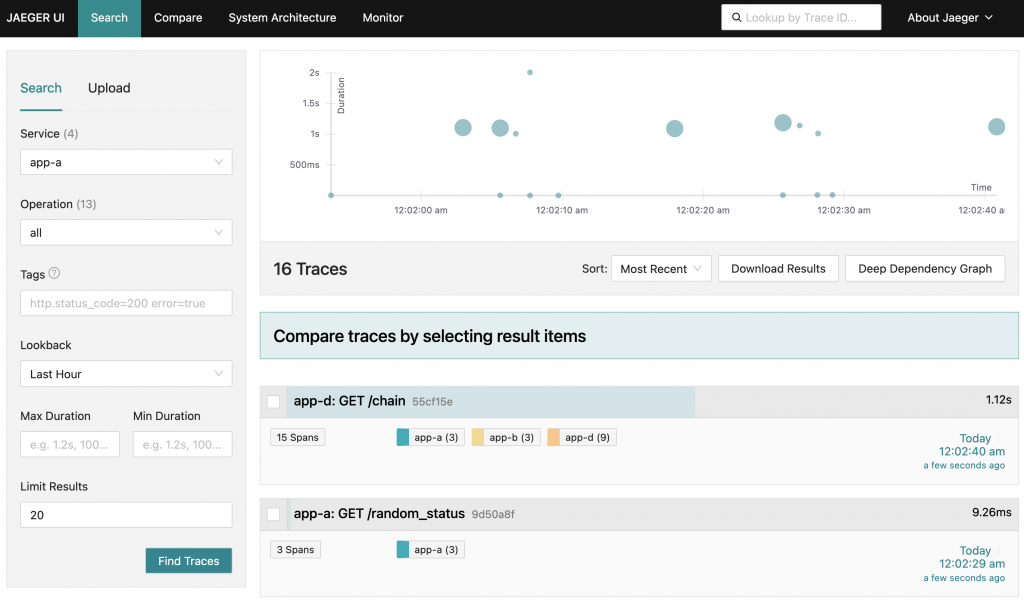
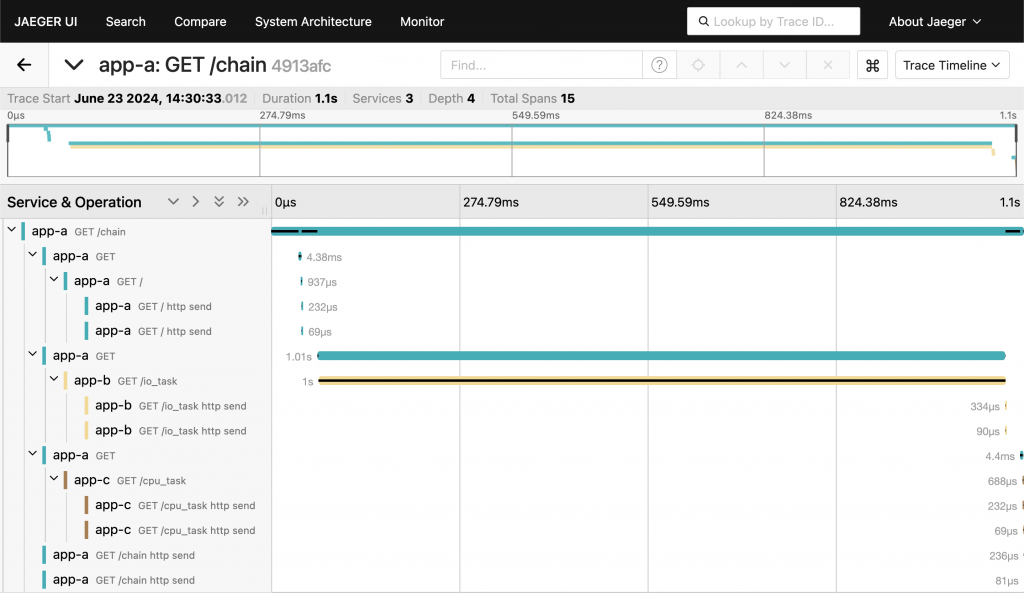
Jaeger 的查詢介面
Grafana 支援 Jaeger Data Source,只要連接到 Jaeger Query 即可查詢,無需切換到 Jaeger 的查詢介面。
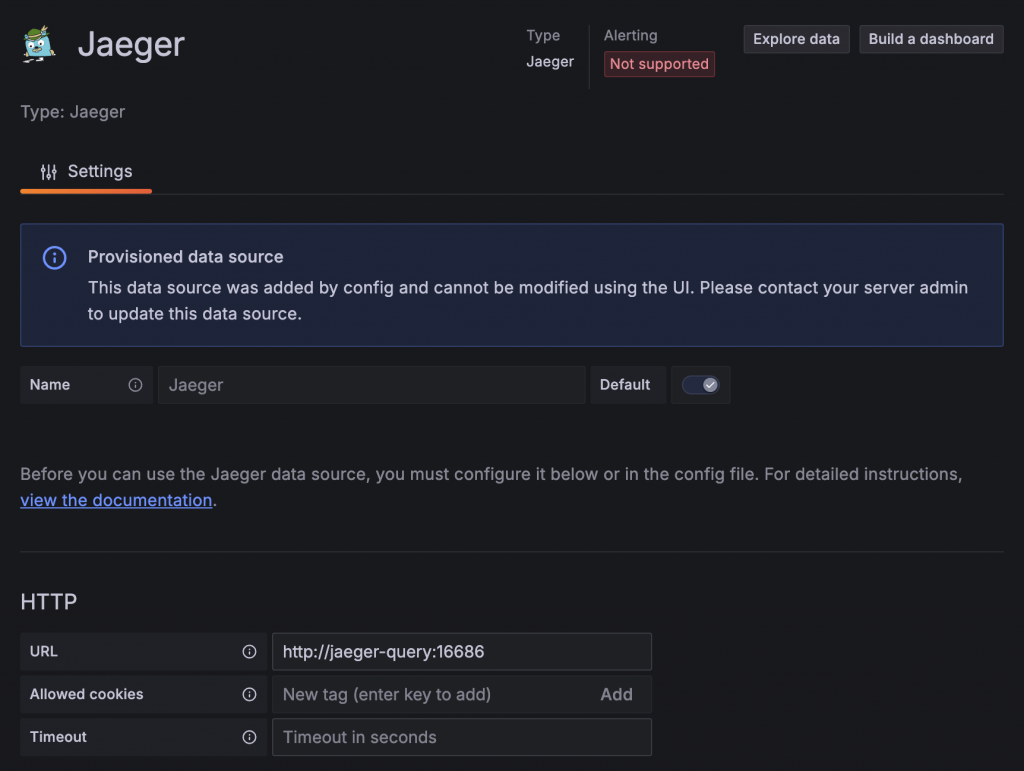
範例 Lab 可以參考 https://github.com/blueswen/observability-ironman30-lab/tree/main/21-jaeger
Grafana Labs 於 2020 年的 ObservabilityCON 釋出了 Tempo,它是一個開源的 Trace 儲存服務,能夠使用 Object Storage 作為儲存媒介,降低儲存成本。Tempo 提供了專屬的 TraceQL 查詢介面,並支援 Service Graph 功能,還可根據 Trace 資料計算 RED Metrics。
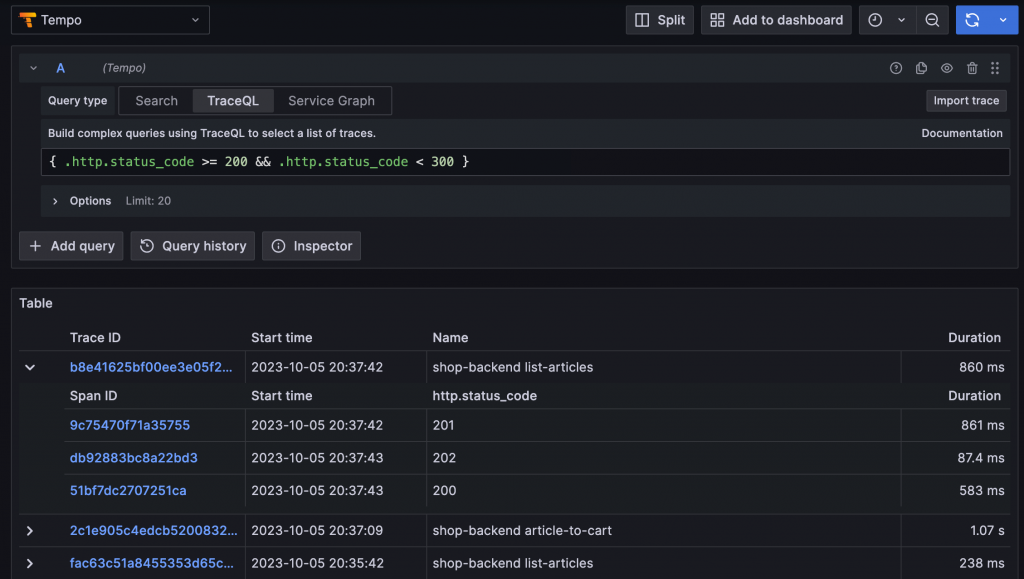
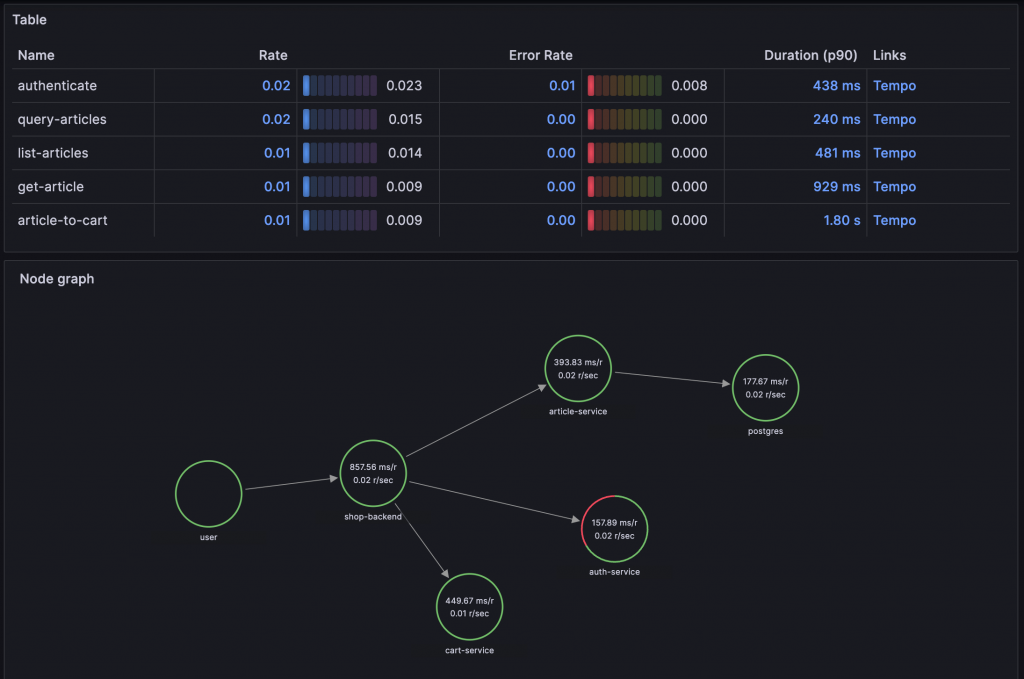
Tempo 提供的 Service Graph 與 RED Metrics 功能
範例 Lab 可以參考 https://github.com/blueswen/observability-ironman30-lab/tree/main/20-tempo
若要深入了解是哪一行程式碼、函數或物件導致效能瓶頸,Profiling 是很有效的方式。傳統上,Profiling 主要用於開發階段,但隨著技術進步,例如 eBPF 的發展,使得 Profiling 能夠應用於生產環境,並減少資源消耗的影響。
2023 年 3 月,Grafana Labs 收購了 Pyroscope,這是一個能持續監控程式片段 CPU 和記憶體使用狀況的工具。透過火焰圖 Flame Graph 進行視覺化,開發者可以輕鬆了解系統效能瓶頸。
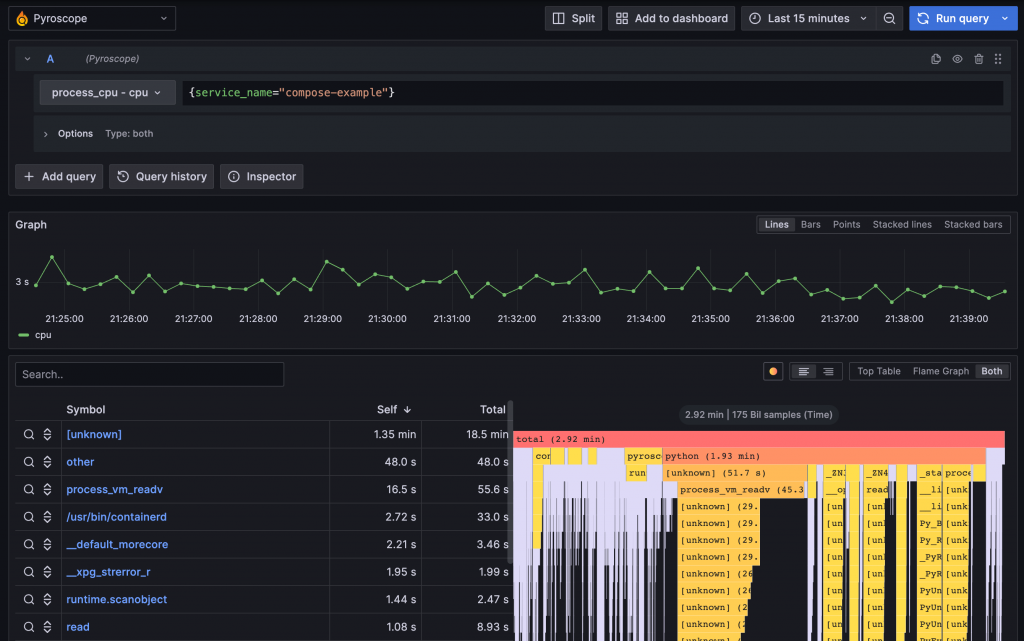
Pyroscope 收集的 Profiling 資訊
範例 Lab 可以參考 https://github.com/blueswen/observability-ironman30-lab/tree/main/25-profiles-and-ebpf#pyroscope

