今天我們繼續看一題字串類型的題目:拆字。
Given a string s and a dictionary of strings wordDict, return true if s can be segmented into a space-separated sequence of one or more dictionary words.
Note that the same word in the dictionary may be reused multiple times in the segmentation.
Example 1:
Input: s = "leetcode", wordDict = ["leet","code"]
Output: true
Explanation: Return true because "leetcode" can be segmented as "leet code".
Example 2:
Input: s = "applepenapple", wordDict = ["apple","pen"]
Output: true
Explanation: Return true because "applepenapple" can be segmented as "apple pen apple".
Note that you are allowed to reuse a dictionary word.
Example 3:
Input: s = "catsandog", wordDict = ["cats","dog","sand","and","cat"]
Output: false
Constraints:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s and wordDict[i] consist of only lowercase English letters.
All the strings of wordDict are unique.
題目給出一個字串以及一個包含許多字串的陣列,要我們判定字串能不能拆解成全由陣列內的字串所構成的片段。
我們以Example3為例來思考如何拆解問題為更小的子問題:
s = "catsandog", wordDict = ["cats","dog","sand","and","cat"]
從字尾開始觀察,我們會發現,可以拆出'dog'
把'dog'從字尾切掉之後剩下'catsan',再繼續思考能不能拆出字典中的字串。
依此類推一直往下拆解下去,若能找到一個能夠完全拆開的方式,就回答True,若不能,就回答False。
我們可以用「剩餘的子字串開頭的index」來描述子問題。
狀態:breakable(i):布林值,描述s[i:]能/不能完全拆解成字典內的字
狀態轉移式:前述的討論若寫成邏輯,會稍微複雜一點:
若len(s) >= j > i範圍內存在一個j,使得breakable(j) == True ,且 s[i:j]是一個wordDict內的字串,則breakable(i)為True。反之,則為False
如下圖:
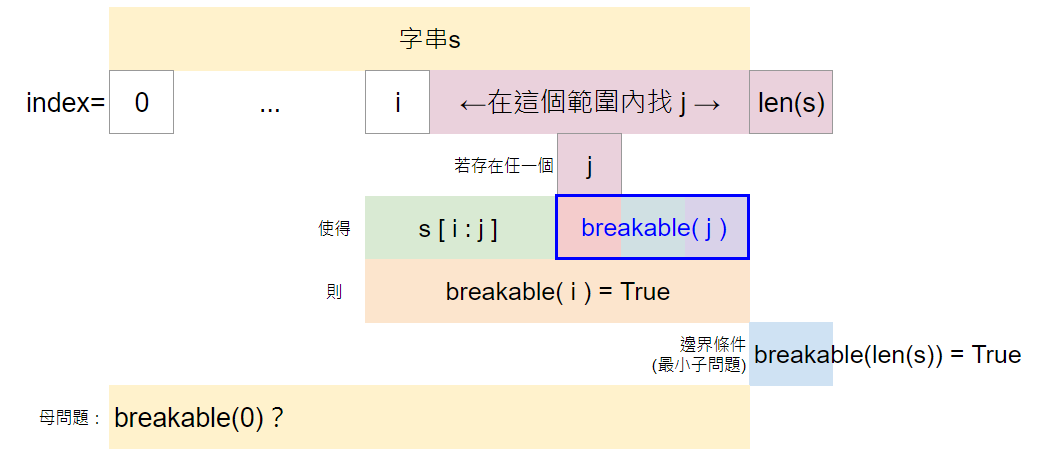
最小子問題(邊界條件):
我們讓breakable(len(s))為True,因為這代表字串s恰好切完了不剩任何字母。
母問題(題目所求):breakable(0),即詢問整個原始字串s是否可分割。
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
# 把List轉化為Set,減少查詢時間
wordSet = set(wordDict)
# 子問提:s[i:]是否可拆分成...
@cache
def breakable(i):
# 邊界條件:s已完全拆分(剩下空字串)
if i==len(s): return True
# 狀態轉移式
return any(breakable(j) and s[i:j] in wordSet for j in range(i+1,len(s)+1) )
# 母問題:s[0:] == s 是否可拆分成...
return breakable(0)
子問題可能重複問到,因此要使用@cache或者手動快取計算過的子問題答案
此外還有幾個細節:
Hashmap的使用:
wordDict是一個List(而非Hashmap的Dict),這將導致每一次檢查s[i:j]存不存在於wordDict都花費O(n)的時間複雜度。在worst case(s不包含任何一個wordDict內的字串)時,演算法會對所有的s[i:j](即s的所有子字串)都進行檢查,因此降低這個檢查的複雜度是必要的。O(n)的時間將wordDict轉化為set,這個Python內建的資料型態可以看成空值的HashMap,讓每一次s[i:j] in wordSet的檢查都加快至O(1)
高階函式any():
any輸入一個可迭代物件,當其中的任何一個元素為True,則返回True。否則返回False
其中的邏輯剛好就是轉移式中「若可以找到至少一個j,使得...,則為True」
當然也可以手刻一個出來:
def any(iterable):
for item in iterable:
if item: return True
return False
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
# 把List轉化為Set,減少查詢時間
wordSet = set(wordDict)
# 記錄答案用的陣列,dp[i] == breakable(i)
dp = [False] * len(s) + [True]
# 從小問題(短的尾巴)開始往前計算
for i in reversed(range(len(s))):
dp[i] = any(dp[j] and s[i:j] in wordSet for j in range(i+1, len(s)+1))
# 回答母問題
return dp[0]
由於和Top-Down使用了相同的轉移式,我們思考母問題時,把原始字串從前面開始拆分,所以要從後面(最小的問題)開始計算。
當然也可以從前往後計算,不過子問題和轉移式就要對應著做修改。各位讀者有興趣的話也可以練習看看。
建立Hashmap的部分:時間複雜度為O(m),m = len(wordDict)
動態規劃的部分:
時間複雜度 = 狀態轉移數 x 計算複雜度
本題的狀態數 = O(n),n = len(s)
計算複雜度的討論有一點複雜:
若將「s不包含wordSet內任何一個字串」視為worst case討論,因此any總是檢查完所有的j,才會返回False,又因為所有的dp[j]均為False,any內每個j檢查的複雜度為O(1),因此,每個狀態的總計算複雜度為O(n)
因此總時間複雜度 = O(m + n^2)
建立wordSet需要O(m)空間,m為wordDict的長度
後續紀錄答案需要O(n)空間
因此總空間複雜度為O(m + n)
本題還有另一個思考的角度:
s上的每一個字母都當成是一個節點s[i:j]存在於wordDict內,則(i,j)節點間存在一個連結0與節點len(s)+1是否連通。例如 s = "catsandogs", wordDict = ["cats","dogs","sand","and","cat"] 等價於下圖:
.png)
由於開頭的c和結尾並不連通,這個例子答案為false。
從這個角度出發,原題等價於「求一個圖(graph)中的某兩個節點(node)是否連通」,其實就是我們在Day5(費氏數列扒手題型)介紹過的Depth First Search問題。
至於寫出來的程式碼,則和動態規劃殊途同歸,因為「檢查兩個節點是否連通」的程式邏輯就是我們在前述動態規劃時檢查s[i:j]是否存在於wordDict當中的程式碼!
字串和List都能用index取值,因此大多數的情況下都可以用1-D DP的框架來思考如何分治,設定狀態並找到子問題。
如果苦無切入點時,以簡單的測資作為出發點,畫圖思考題目的情境,對於解題會相當有幫助!
此外,本題的材料明明就是字串,但是從另一個角度切入,又和費氏數列題型的問題有相似之處。希望各位讀者也能從中體驗到動態規劃題型「異曲同工」背後共通的核心思維!
以上為Day10的內容!感謝你的閱讀,如果有不同的想法或心得,歡迎留言一同討論!
本文也同步登載在我的個人部落格,記錄我的學習筆記與生活點滴,歡迎來逛逛。
明天會繼續看其他的字串題。

