本題取自 Leetcode 1143. Longest Common Subsequence
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
For example, "ace" is a subsequence of "abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:
Input: text1 = "abcde", text2 = "ace"
Output: 3
Explanation: The longest common subsequence is "ace" and its length is 3.
Example 2:
Input: text1 = "abc", text2 = "abc"
Output: 3
Explanation: The longest common subsequence is "abc" and its length is 3.
Example 3:
Input: text1 = "abc", text2 = "def"
Output: 0
Explanation: There is no such common subsequence, so the result is 0.
Constraints:
1 <= text1.length, text2.length <= 1000
text1 and text2 consist of only lowercase English characters.
和day9遇到過的子字串定義不太相同,子序列可以由給定字串(或者陣列)當中取出任意的片段並重新串接,但順序要維持不變。例如'abcd'的子序列包含'abd',但不包含'ca'(因為字母順序和原字串不同)。
兩個字串擁有共同子序列,意即某個子序列sub同時屬於字串t1、t2的子序列。
那麼要如何找出題目所要求的「最長的共同子序列」長度呢?
暴力破解(brute force)顯然是不現實的,因為每一個字母都可以取或者不取,光是暴力枚舉(enumerate)出所有的子序列就需要O(2^n)的指數時間,顯然必須尋找不同的途徑。
我們以一個簡單的例子來思考:求字串'abc'與acb的最長共同子序列長度。
答案顯然為2,ab或者ac都為其所代表的解。儘管這兩個字串一共含有a b c三個共同的字母,但答案為何不是3呢?
原因就在於,子序列的排列順序必須與原本的字串相同。無法同時使用a b c三個字母,卻同時滿足和兩個字串相同的排列順序。
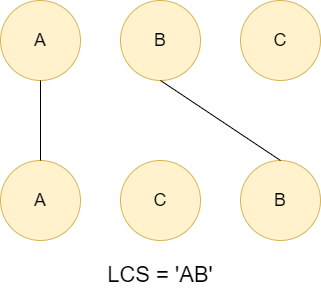
.png)
由前述討論可知,尋找LCS的過程,需要匹配相同的字母,且保證在兩個字串當中的順序相同
本題用到一個貪心(Greedy Stratagy)的思維:
若兩個字串
text1、text2的字首相同text1[0] == text2[0],則這個字首必定包含在text1、text2的*最長共同子序列(LCS)*當中。
繼續以前述的測資為例,'abc'與'acb'的LCS必定包含'a',且其位置必為字首。
若兩個字串
text1、text2的字首不text1[0] != text2[0],則這兩個字首的至少其一必定不包含在text1、text2的*最長共同子序列(LCS)*當中。
分析至此,我們便找到了如何逐步匹配的策略。
狀態:以LCS(i,j)來代表text1[i:]、text2[j:]之間的最長共同子序列的長度。
狀態轉移式:
若 text1[i] == text2[j](字首相同):
LCS(i,j) = 1 + LCS(i+1,j+1)
若 text1[i] != text2[j](字首不同):
LCS(i,j) = max( LCS(i+1,j), LCS(i,j+1) )
邊界條件(最小子問題):i < len(text1),j < len(text2)
母問題(題目所求):LCS(0,0)
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
@cache
def LCS(i,j):
if i==len(text1) or j==len(text2):
return 0
if text1[i] == text2[j]:
return 1 + LCS(i+1, j+1)
return max(LCS(i+1, j), LCS(i,j+1))
return LCS(0,0)
為了處理index overflow的問題並且不增加額外的邏輯判斷程式碼,最上一列與最左一行(i==o 或者 j==0)都加入一個額外的0。
配合計算順序,dp[i][j]改成代表text1[:i]和text2{:j}之間的LCS(改成比較字尾而非字首)。
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
dp = [[0]*(len(text2)+1)]
for i in range(len(text1)):
row = [0]
for j in range(len(text2)):
if text1[i] == text2[j]:
row.append(1+dp[i][j])
else:
row.append(max(row[j], dp[i][j+1]))
dp.append(row)
return dp[-1][-1]
也可以使用Rolling或者Inplace的技巧來優化,降低一維空間複雜度。
下例為inplace DP的示範:
由於inplace DP會覆寫掉上一列的資料,但轉移式會使用到LCS(i-1, j-1)以及LCS(i-1,j),需要額外保留左上角一格的資料prev以及上面一格的cur
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
dp = [0]*(len(text2)+1)
for i in range(len(text1)):
prev = 0
for j in range(len(text2)):
cur = dp[j+1]
if text1[i] == text2[j]:
dp[j+1] = 1+prev
else:
dp[j+1] = max(dp[j:j+2])
prev = cur
return dp[-1]
時間複雜度 = 狀態轉移數 x 計算複雜度
本題的狀態數 = O(n1 x n2),n1 = len(text1),n2 = len(text2)
計算複雜度為O(1)
因此總時間複雜度 = O(n1 x n2)
空間複雜度 = 狀態數 = O(n1 x n2))
若採用Rolling(或者Inplace) Bottom Up DP的技巧,則降低一個維度,空間複雜度 = O(n2)
以上的實作,時間複雜度上並沒有什麼問題,但若想要更進一步優化,可以想想看以下這組測資:
text1與text2很長,且彼此之間完全沒有任何一個共同的字母。(簡單舉例如aaa...aaa和bbb...bbb)
答案顯然為0,然而我們還是得花n1 x n2的時間遍歷比對text1與text2當中任意的字母組合。
有沒有方法事先排除掉這些不共同的字母,來優化整體的時間花費呢?
實作範例如下:
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
common = set(text1) & set(text2)
t1 = [c for c in text1 if c in common]
t2 = [c for c in text2 if c in common]
@cache
def LCS(i,j):
if i==len(t1) or j==len(t2):
return 0
if t1[i] == t2[j]:
return 1 + LCS(i+1, j+1)
return max(LCS(i+1, j), LCS(i,j+1))
return LCS(0,0)
動態規劃的部分和原本相同,只是在執行LCS演算法之前,先對原始字串做一點處理:
text1與text2共通的所有字母作為common(使用了Python的Set資料容器以及交集語法)text1與text2內不屬於common的字母剔除。所獲得的新字串,再執行LCS演算法。
如此一來的成效如何呢?
建立Set需要花費O(n1+n2)
交集運算(union operation '&')在worst case會花費O(x+y),其中xy分別為兩集合的大小
LCS演算法需要花費O(m1 x m2),其中m1、m2分別為經處理過後的字串長度。
由於時間瓶頸仍是在LCS的部分,當text1與text2當中不共通的字母越多,就能節省越多時間。
整體而言,雖然並沒有降低時間複雜度的數量級,但平均時間可獲得顯著的下降。
建立Set需要額外花費O(n1+n2)空間
交集運算(union operation '&')不花費額外的空間
LCS演算法需要花費O(m1 x m2),其中m1、m2分別為經處理過後的字串長度。
若使用Rolling Bottom Up DP,則LCS可以降低一個維度至O(m),m為min(m1,m2)
整體而言,由於m1、m2相對n1、n2亦獲得了縮減,空間複雜度並沒有數量級上顯著的增加。
(當然,建立Hashmap的空間常數必然比儲存整數的matrix大上許多)
下圖為筆者用Top-Down、Bottom-Up兩種策略,分別優化與不優化,在Leetcode上面跑出來的結果。
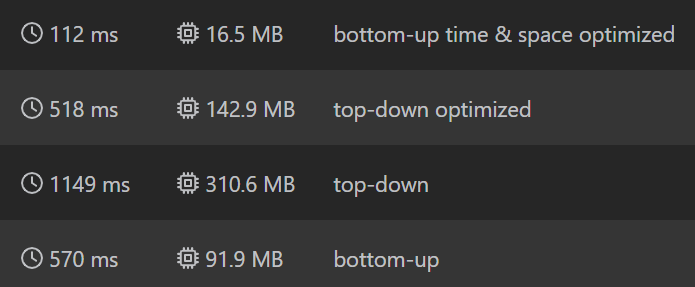
可以觀察到由於本例的遞迴層數很深,Top-Down的空間常數都相當大,Bottom-Up則在節省空間的同時也維持更快的運算速度。若同時使用Rolling和資料前處理的技巧來節省時間與空間,其效果也相當的顯著。
LCS的解題概念並不複雜,其中融入了一點Greedy的思維,讓我們不必浪費O(2^n)比較所有的子序列,是我當初刷到時很喜歡的一個題型。
除了LCS本身的算法邏輯,在本題也看到透過資料前處理來進一步優化計算時間的範例。這提醒了我們:有時候除了改變算法來影響複雜度的優化,不去算不必算的東西,也是一種優化方式。這無論是刷題時,或者真正實作專案時都值得借鏡。
以上為Day11的內容!感謝你的閱讀,如果有不同的想法或心得,歡迎留言一同討論!
本文也同步登載在我的個人部落格,記錄我的學習筆記與生活點滴,歡迎來逛逛。
明天會繼續看字串類型的例題。

