在昨天的課程中,我們已經介紹完了自然語言處理的基礎名詞,因此今天將開始進入文字辨識的環節。不過在此之前,我們需要先理解為何文字與時間有關,並介紹處理時間序列的重要模型循環神經網路(Recurrent Neural Network, RNN)與長短期記憶(Long Short-Term Memory, LSTM)。因此在這幾天的內容中我們會探討這兩個模型如何經過Word Embedding後進行運算,並成功進行文字辨識。
讓我們首先來理解文字與時間的關係。文字在自然語言中有順序(Sequence)和上下文關係(Context),這意味著前後文的詞語會影響整個句子的意義。例如,"他拿了錢就走"和"他走了才拿錢"的詞組相同,但意思完全不同:前者表示「先拿錢再離開」,而後者表示「先離開後再拿錢」。這展示了文本的時間序列特性(Temporal Sequence Characteristic)如何影響句子的具體意思。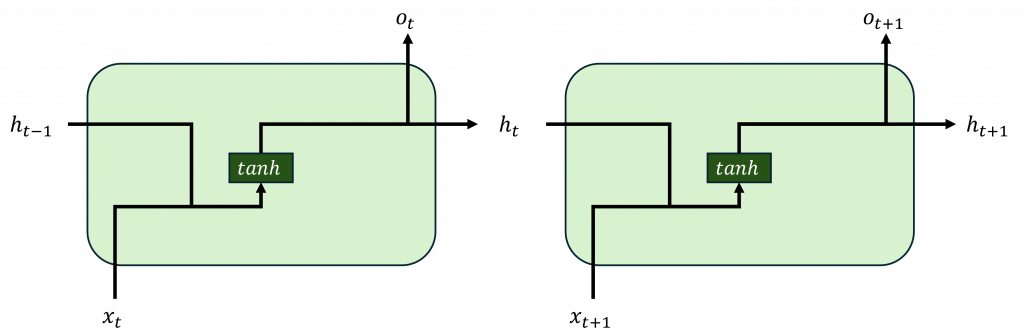
因此在設計神經網路模型時,需要考慮每個時序的位置,並根據這些時序的排列組合來預測正確的結果而循環神經網路是一種專門用於處理時間序列數據的神經網路模型,其核心思想是通過內部的循環結構來保留之前的信息。
循環神經網路的基本運算可分為兩個部分:第一部分計算當前時序的輸入x(t);第二部分則計算前幾個時序的隱狀態(Hidden State, h(t))。這兩者的結果會結合在一起,並通過tanh激勵函數將結果縮放到-1到1之間,其數學公式如下: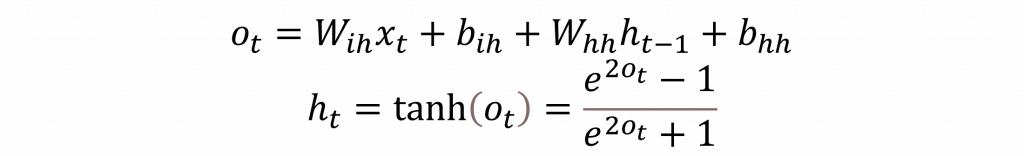
而在公式中這裡選用tanh激勵函數而不是sigmoid或ReLU,是因為**tanh能夠提供更廣泛的信息範圍**。與sigmoid函數的返回值範圍為0到1不同,tanh的範圍是-1到1,能夠提供負相關的特徵,這對於時間序列模型來說非常重要,因為它能夠保留更多有效的信息,讓資訊能夠更有效地傳遞下去,從而提升預測的效能。
循環神經網路在處理長期依賴的序列時,常常會遇到梯度消失問題。這是因為當某些數據在輸入時,其輸出值非常接近於0,隨著時間推移,這些資料造成的梯度將趨近於0,導致模型無法正常更新。為了解決這個問題,長短期記憶網路應運而生。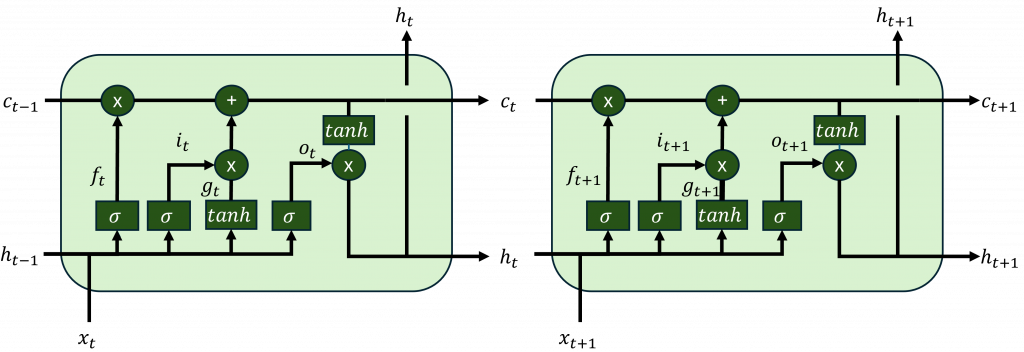
LSTM使用不同的門控機制(Gating Mechanism)來控制信息的傳遞和保護,使其能更好地處理長期依賴問題。LSTM的結構由多個單元組成,每個單元包含三個主要的門控機制:輸入門(Input Gate)、遺忘門(Forget Gate)和輸出門(Output Gate),以及一個貫通整個網路的記憶單元(Cell State)。這些門控機制的作用如下:
輸入門的主要功能是決定是否將新的信息寫入記憶單元,這層主要根據前一個時間步驟的隱藏狀態來進行計算,用來模擬人類接收新信息時對其重要性的評估,決定是否將其存儲到長期記憶(記憶單元)中。這層涉及兩個主要參數其公式如下: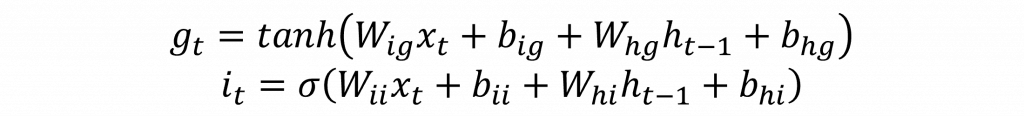
候選記憶單元g(t)的概念類似於循環神經網路中的下一個隱藏狀態h(t),其目的是生成潛在的新信息。在LSTM中,每一層的計算都需要先生成候選結果,然後與對應的門控機制進行運算。
因此在輸入門層中,首先通過前一個時間步驟和當前的輸入進行計算,然後通過tanh函數生成其概率分布。接下來,這個結果會與i(t)進行哈達瑪乘積運算。由於i(t)是經過sigmoid函數處理的,其值介於0到1之間,因此這個乘積運算能夠剔除不重要的信息,只保留重要的信息進入記憶單元形成長期記憶。
遺忘門的作用是控制哪些信息應該從記憶單元中遺忘,這類似於人類選擇性遺忘不再重要的記憶,以避免記憶過載。公式相對簡單,通過sigmoid函數計算前一個記憶單元c(t-1)中的信息應該被遺忘的程度其數學公式如下: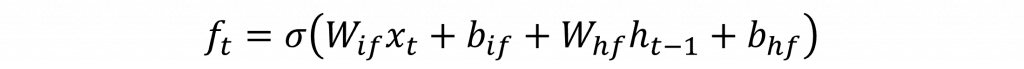
有了輸入門和遺忘門的計算結果後,可以更新當前時間步的記憶單元c(t),該公式是將兩者的輸出結果進行加法運算,具體公式如下: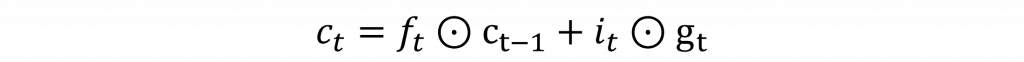
當我們得到記憶單元的結果後,接下來像循環神經網路一樣,計算短期記憶o(t)的資料分布,並將其與記憶單元c(t)的長期記憶進行哈達瑪乘積運算。這樣每一層的輸出就能同時保留過去的信息並融合當前的最新信息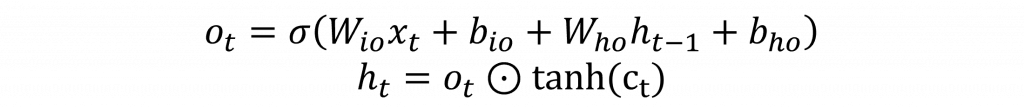
這些門控機制使LSTM在處理長期依賴關係時能夠保持關鍵信息,避免了梯度消失問題,因此與傳統RNN相比,LSTM在處理較長的序列時表現得更加出色。
在今天的內容中,我們公式從中可以得知其時序是單向的運算,例如由左到右或由右到左。這樣的運算方式實其跟我們人類觀看在文字時的方式不太一樣。我們人類有時候跳著會觀看一些文字,或在序順時相反也能自動解析夠這些文字。所以一個好的模型應要該的具備這樣特性。對於前者可能我們的模型無法有效解決,但對於後者我們可以通過輸入一些混亂的文字讓來模型學會更多特徵。這個做法在深度學習中,即是種透過加入噪音以提升效能模型的正化規方法。不信你認真的重新閱讀一下這段文字。

