現在我們的學習進度已經達到一半,並且已經完成了圖像與文字的辨識任務。接下來我們將進入一個更加特殊的單元生成式AI(Generative AI)。今天的課程重點是介紹圖片生成的簡易模型。現在讓我們先來了解其技術原理吧!
生成對抗網路(Generative Adversarial Networks, GANs)是由Ian Goodfellow等人在2014年提出的一種方法。其基本概念是通過一個生成模型從潛在空間(latent space)中隨機取樣作為輸入,這個潛在空間是由亂數產生的。生成模型嘗試生成與訓練集中真實樣本相似的結果。由於該技術是一種非監督式學習技術,因此我們還需要建立一個判別模型,用來判斷生成的圖片的真偽,其目的是盡可能準確地分辨生成的結果和真實樣本,以計算損失值。
而不同於GANs這類只使用深度神經網路建立的生成式模型,DCGAN(Deep Convolutional GAN)更是在生成圖像的應用中扮演了重要角色,因其結合了卷積神經網路和GAN的力量,大幅提升了圖像生成的品質與穩定性,現在讓我們看看其核心概念與數學推導吧!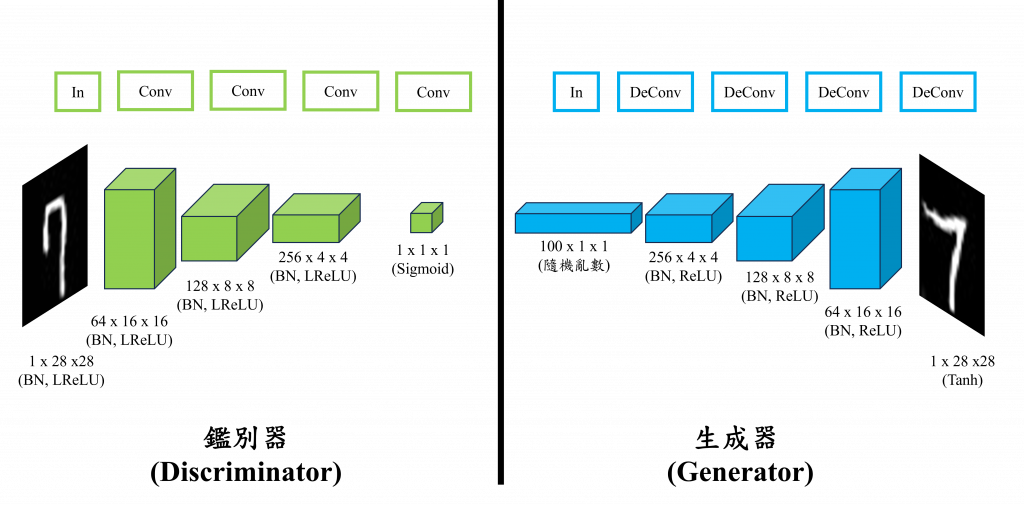
DCGAN的架構主要由兩部分組成判別器(Discriminator)和生成器(Generator)。判別器負責判斷輸入的圖像是真實的還是生成的,它接受的資料包括由生成器產生的圖像,或是從我們資料集中取得的真實圖像。判別器的目標是將真實圖像與生成圖像區分開來,這些資料會通過多個卷積層進行特徵提取,最終輸出一個表示真實或虛假的概率。而生成器的目的是通過一個隨機的向量,經過一系列轉置卷積層(Transposed Convolution Layers),最終生成與目標圖像相似的圖像。
在判別器中圖像會逐步通過卷積層縮小成一個特徵圖,而在生成器中則使用轉置卷積層來逐步放大特徵圖,從隨機噪音(Random Noize)中合成完整的圖像。
轉置卷積層也會被稱為
反卷積層(Deconvolution),因此在Paper中你看到兩個名詞時其實都在指向相同的東西。
而對於DCGAN的數學公式其實只有一個損失函數的設計。該函數是基於博弈論中的零和博弈設計,旨在讓生成器和判別器進行對抗訓練,其損失函數為: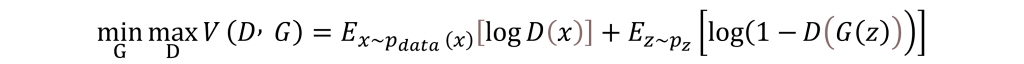
在以上公式中G 是生成器,負責生成圖像;D 是判別器負責區分真實圖像和生成圖像。x 是真實數據來自於真實的圖片輸入 p(x);z 是隨機噪聲來自於事先定義的噪聲分佈 p(z)。
該損失函數的目標是生成器希望最大化判別器的錯誤率,也就是說生成的圖像越難被判別器識別出來,生成器的表現就越好。反之判別器則希望能正確區分真實圖像與生成圖像。
在訓練DCGAN時我們需要注意的事情就是緩解不同層之間的內部協變轉移(Internal Covariate Shift),即由於前面幾層參數的改變會引起後面幾層輸入分佈的劇烈變化。因為在DCGAN這類的深層網路,模型的梯度會由於深度而更加不穩定導致梯度爆炸或梯度消失,而且由於DCGAN訓練時的兩個網路是對抗性的,容易陷入不穩定的訓練狀態。因此我們通常會加入批量標準化(Batch Normalization)平滑這種對抗,讓判別器和生成器都能更好地學習。
批量標準化會對每一個特徵通道(Channel)分別計算均值和標準差。這些計算是在小批量(mini-batch)的數據上進行的。均值E[x]是每個通道的平均值,而標準差Var[x]是根據偏差估計(biased estimator)計算的,這表示在計算方差時分母使用了批量大小。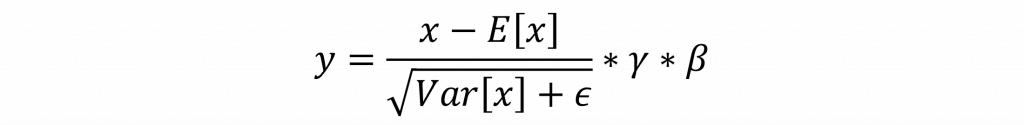
而在這個過程中,每個特徵通道都有對應的可學習參數向量γ(縮放)和β(偏移)。這兩個參數的維度都是特徵通道的大小。而在Pytorch預設情況下,γ的元素初始化為1,而β的元素初始化為0。這意味著初始的批量標準化不會改變標準化後數據的比例和位置。
一個問題在於我們通常會選擇使用ReLU作為這些模型的激勵函數,然而標準的ReLU函數在輸入小於0時會輸出0,這會導致負輸入的神經元在後續的訓練過程中無法更新(梯度為0),也就是所謂的神經元死亡問題(Dead ReLU Problem)。
因此在DCGAN這類深層網路中,通常會改用 Leaky ReLU。因為它能透過設定 α 值,允許負輸入有一個小的正梯度,使得這些神經元仍然能夠更新,保持負輸入的梯度。這有助於在訓練過程中維持更好的梯度,特別是在深層網路中。這使得模型能夠學習更複雜的數據表示,從而可能提高模型的整體性能。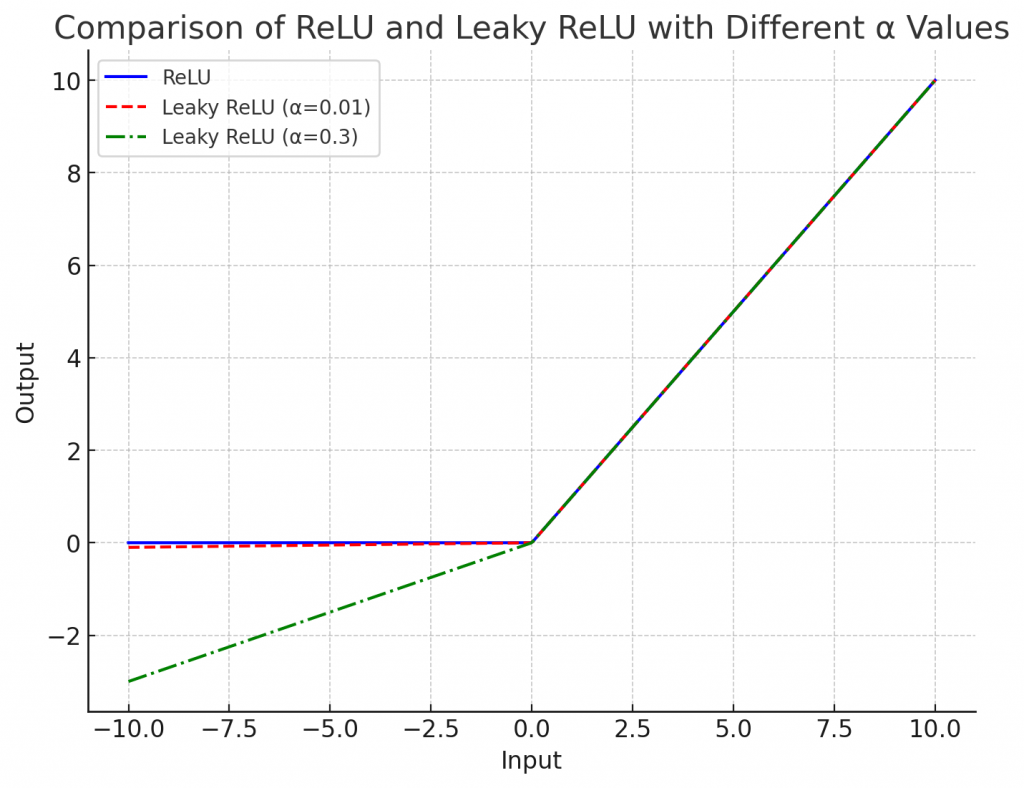
而這也是我們在Day 8中提到在後續的網路中都是使用ReLU的變化版本,而就是其中一種該激勵函數特別適合用於需要處理較深層網路結構的情況,能夠有效地緩解死神經元問題,提高模型的訓練效率和性能。
在今天的內容中,我們可以看到DCGAN的數學推導其實並不複雜,基本上就是一個CNN的延伸。唯一的差異在於一個基於博弈論的損失函數,使其能夠完成生成圖像的工作。不過雖然數學式簡單,但在程式的建立上會有一些難度。因此,我們今天還介紹了如何更好地優化這些模型。而在明日我會告訴你如何完整地建立出一個DCGAN模型。

