
進入系列文的下半場,我們重新思考一次:是否所有資料的加工運用,都無法滿足「即時性」的需求?
我們在 Day 11 介紹 Airflow 時提過,批量處理 (Batch Processing) 意指多筆資料一次性地進行處理,而不是即時處理單筆資料。相對應於批量處理的是串流處理 (Stream Processing) ,針對資料的到達方式、處理時間和應用場景都有所不同。它們的主要差異有:
批量處理
資料通常會在一定的時間範圍內累積起來,然後一起處理、進行運算。
常用於定期執行的任務,例如每天、每小時或每月的報告產生。
串流處理
資料會在到達系統後立刻被處理,通常是即時的 (real-time) 或接近即時的 (nearly real-time)。
系統會不斷接收和處理資料流,處理結果會隨著新資料到達而逐步更新。
適用於需要即時反應/分析的情境,例如監控告警系統、即時推薦或金融交易。
批量處理
延遲較高,適合處理大型資料集,可能耗時數分鐘、數小時甚至更長。
但等待整批資料收集完成後處理的結果通常較為精確。
很適合完整資料進行分析的場景等不強調即時性的應用。
串流處理
延遲極低,因為資料在到達時即被處理,通常在毫秒或秒級完成。
資料是持續到達的,因此在某個時刻可能並不具備完整的資料集。處理過程中往往會採用 windowing 的方式來 GROUP BY 一定範圍內的資料。
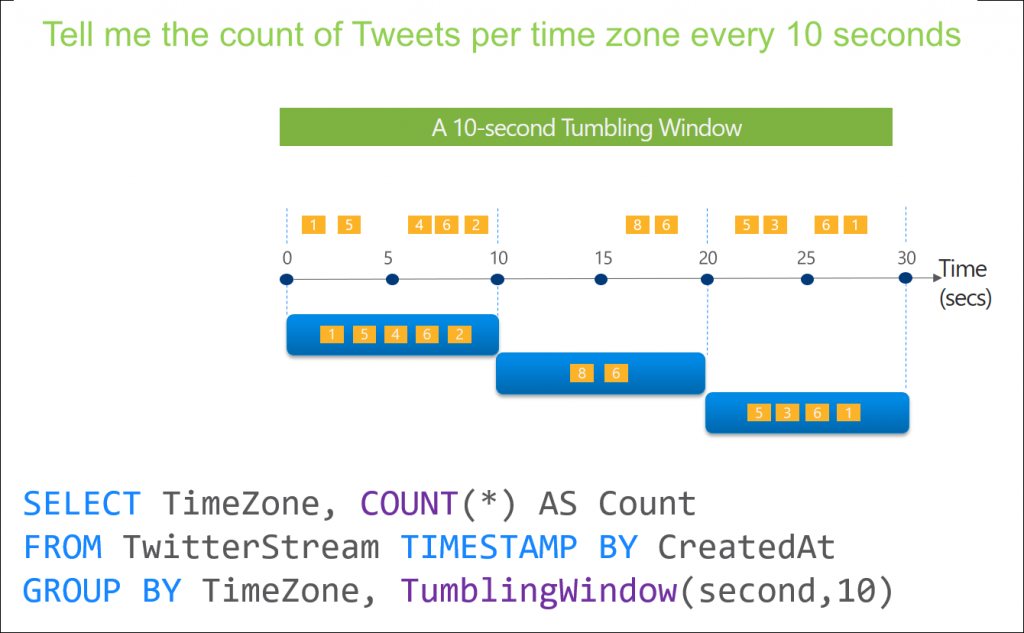
Source: https://learn.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions。
雖然反應迅速,但串流處理的結果可能在一開始並不精確,需隨著資料的持續流動來逐漸完善,可理解為滾動修正。
允許稍微不那麼準確但能快速做出反應的應用場景。
批量處理
Apache Hadoop:分散式 (distributed) 批量處理系統,擅長處理大規模資料集。
Apache Spark:批量處理引擎,能在記憶體 (in-memory) 中處理資料。
AWS 的 Glue、Google Cloud 的 Dataflow:雲端版批量處理方案。
串流處理
Apache Kafka:分散式串流處理平台,支援資料傳輸與儲存。
Apache Flink:即時資料流處理引擎。
Google Cloud 的 Pub/Sub、AWS 的 Kinesis:雲端提供的串流處理服務。
批量處理適合處理完整、大規模的歷史資料,通常用於需要高準確度但不強調即時性的工作,常和資料倉儲一起談論。串流處理則用於即時資料流的處理,適合需要快速反應並且能容忍一定誤差的應用場景。
以上的比較解決了我們的困惑:即便資料需要加工運用,還是能透過串流處理滿足即時性需求。
衍伸的問題是:作為一個資料平台建構者,我們能不能兼容批量和串流的特性,同時滿足歷史分析報表與即時資訊系統?
Lambda 和 Kappa 是兩種常見的資料處理架構,特別適用於大規模資料處理和分析工作。它們解決了如何有效處理 batch 與 streaming 資料的問題,但各自的設計和應用情境有所不同。
Lambda 架構的核心理念是分離系統中的批量處理和串流處理,兩者獨立運作,最後才結合的架構。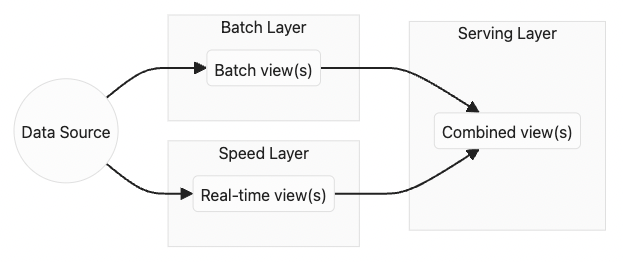
Source: https://dataengineering.wiki/Concepts/Lambda+Architecture。
此架構適合需要處理大量歷史資料,並且即時處理結果對業務有價值的情境。這類架構能確保資料處理的最終一致性,常見於即時推薦系統或資料分析平台 (如 SHOPLINE 數據分析中心 Shoplytics 的部分功能)。
Kappa 架構主要不再有分離的 Batch Layer 和 Speed Layer,所有的資料處理都通過 stream processing 進行。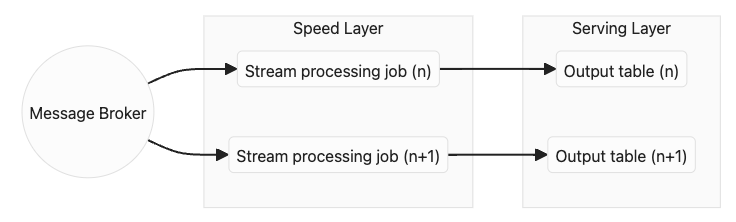
Source: https://dataengineering.wiki/Concepts/Kappa+Architecture
此架構在 Speed Layer 邏輯的統一性,在批量與串流處理需求比較接近的情境下更具吸引力,例如即時警示系統。
日更新報表,我們在 10/2 午夜開始計算 10/1 00:00:00 ~ 10/1 23:59:59 的資料,計算時間 10 分鐘,對於 10/1 午夜就進到處理系統的資料而言,延遲時間是 24 小時又 10 分鐘。但這就是 Batch Processing 的特徵:累積資料 ⮕ 定時運算,雖然有延遲,但確保了資料完整性。處理成本會落在 query size 計價的服務上,以及儲存大量歷史資料的費用。
Stream Processing 讓資料從資料源到終端取用者的流轉時間接近秒等級,滿足了即時性的需求,雖然資料是逐步到達,但仍然確保最終一致的目標。處理成本會落在即時處理的 engine 上。
資料轉換想必是越快越好,如果能接近即時,誰要選批量呢?
只要一套處理邏輯的 Kappa 是否一定優於 Lambda 呢?
這樣想,就忽略開發者的學習成本及後續的維護成本了。例如,Stream Processing 就不是一個 Airflow 可以完成,可能要駕馭 Kafka 及 Flink 才能完善基礎建設;當資料品質出現問題時,即時運算的資料或許沒辦法像 Batch Processing 產生的資料可以方便地查詢 snapshot。開發/維運者的心力負擔,也是資料系統架構考量的一大重點。
之前準備 GCP 資料工程師
有看到 Apache Beam
你覺得會是更好的選擇嗎?
Apache Beam 是一個通用的資料處理模型,支援多種執行引擎,例如 Apache Flink、Google Dataflow 和 Apache Spark。使用相同的程式設計模型來處理批次和流式數據,適合多雲或異構環境。

