這邊修改了FinRL的sample code用來學習使用一小時的數據交易,雖然看程式碼中,可以看出FinRL的程式碼中有很多地方都是針對日線資料寫死的設定(很多地方使用252筆數據作為一個周期,美股一年的日線數量);不過訓練結果看起來還是能用。
為了要確認訓練完成的數據績效,要稍微修改一下比較基準,使用
S&P500 Hourly ReturnDJI Hourly Return以下是S&P500 Hourly Return的實作,主要是計算Daily Return後,將數據填入每日開盤的第一個小時,之後把該日期他小時的數據都填上0。
def calculate_sp500_hourly_return(start_date, end_date, train_df):
"""
Calculate hourly returns for the S&P 500 index by matching each hour to the corresponding day's data.
Parameters:
- start_date: The start date for fetching S&P 500 data.
- end_date: The end date for fetching S&P 500 data.
- train_df: The hourly train dataframe which contains the datetime column.
Returns:
- hourly_returns: Pandas Series containing hourly returns for the S&P 500 index.
"""
from finrl.plot import get_baseline, get_daily_return
# Fetch baseline S&P 500 daily data
baseline_df = get_baseline(ticker='^GSPC', start=start_date, end=end_date)
# Calculate daily returns for S&P 500
daily_returns = get_daily_return(baseline_df, value_col_name="close")
# Ensure 'date' is in datetime format
train_df['date'] = pd.to_datetime(train_df['date'])
train_df['date_only'] = train_df['date'].dt.date
# Get the first timestamp of each day in the hourly data
first_hour_per_day = train_df.groupby(
'date_only')['date'].min().reset_index()
# Merge the daily returns data with the first hour of each day
first_hour_per_day = pd.merge(first_hour_per_day,
daily_returns,
left_on='date_only',
right_on=daily_returns.index.date,
how='left')
# Set 'date' (first hour of each day) as the index for the merged data
first_hour_per_day.set_index('date', inplace=True)
# Extract all hourly timestamps for a random stock (example)
random_tic = train_df['tic'].sample(n=1).iloc[0] # Get random 'tic'
full_hourly_date = train_df[train_df['tic'] == random_tic]['date']
# Create a DataFrame for hourly returns with 0s as default
hourly_returns = pd.DataFrame(index=full_hourly_date)
hourly_returns['daily_return'] = 0.0
# Map the daily return to the first hour of each day
matched_dates = first_hour_per_day.index.intersection(full_hourly_date)
# Update the matched dates in hourly_returns with the correct daily return
hourly_returns.loc[matched_dates, 'daily_return'] = first_hour_per_day.loc[
matched_dates, 'daily_return'].values
return hourly_returns['daily_return'].fillna(0)
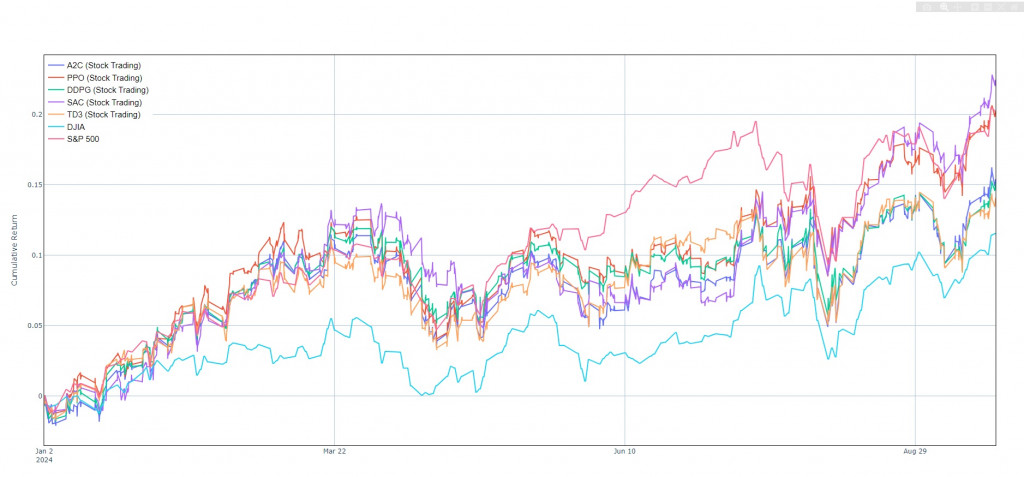
繪製折線圖來確認DRL的回測績效:
以結果來說實在不太好,只能說這是一次失敗的嘗試,
FinRL所有的設置都是針對日線,不利於接下來的嘗試,明天可能要調整接下來的方向。
完整的程式碼
import os
import itertools
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from stable_baselines3 import A2C, DDPG, PPO, SAC, TD3
from stable_baselines3.common.logger import configure
from finrl.agents.stablebaselines3.models import DRLAgent
from finrl.meta.preprocessor.yahoodownloader import YahooDownloader
from finrl.meta.preprocessor.preprocessors import FeatureEngineer, data_split
from finrl.meta.env_stock_trading.env_stocktrading import StockTradingEnv
from finrl import config_tickers
from finrl.config import INDICATORS
from pypfopt.efficient_frontier import EfficientFrontier
from pypfopt import risk_models
import plotly.graph_objs as go
TRAINED_MODEL_DIR = "sp500_1hour_20190921_20231231"
RESULTS_DIR = "sp500_1hour_20190921_20231231_log"
def train_drl(e_trade_gym, models_info):
"""
Function to train deep reinforcement learning (DRL) models.
Parameters:
- e_trade_gym: The trading environment for backtesting.
- models_info: A dictionary containing the model class as keys and corresponding training parameters and paths as values.
Returns:
- trained_models: A dictionary containing the trained models.
"""
env_train, _ = e_trade_gym.get_sb_env()
# Initialize DRLAgent
agent = DRLAgent(env=env_train)
# Dictionary to store the trained models
trained_models = {}
# Loop through each model class and its associated information
for model_class, info in models_info.items():
model_path = info["save_path"]
if os.path.exists(model_path):
print(f"正在從 {model_path} 加載現有的 {model_class.__name__} 模型")
# Load the model using stable-baselines3
try:
model = model_class.load(model_path, env=env_train)
trained_models[model_class.__name__] = model
print(f"{model_class.__name__} 模型加載成功。")
except Exception as e:
print(f"加載 {model_class.__name__} 模型失敗: {e}")
print(f"將繼續訓練 {model_class.__name__} 模型。")
# Train the model if loading fails
model = agent.get_model(
model_name=model_class.__name__.lower(),
model_kwargs=info["params"])
trained_model = agent.train_model(
model=model,
tb_log_name=model_class.__name__.lower(),
total_timesteps=info["total_timesteps"])
trained_model.save(model_path)
trained_models[model_class.__name__] = trained_model
print(f"{model_class.__name__} 模型已訓練並保存到 {model_path}")
else:
print(f"正在訓練 {model_class.__name__} 模型...")
model = agent.get_model(model_name=model_class.__name__.lower(),
model_kwargs=info["params"])
trained_model = agent.train_model(
model=model,
tb_log_name=model_class.__name__.lower(),
total_timesteps=info["total_timesteps"])
trained_model.save(model_path)
trained_models[model_class.__name__] = trained_model
print(f"{model_class.__name__} 模型已訓練並保存到 {model_path}")
return trained_models
def backtest_drl(e_trade_gym, trained_models):
"""
Function to backtest all trained DRL models.
Parameters:
- e_trade_gym: The trading environment for backtesting.
- trained_models: Dictionary of trained models.
Returns:
- backtest_results: Dictionary containing daily returns and actions for each model.
"""
# Initialize backtest results dictionary
backtest_results = {}
# Iterate through each trained model for backtesting
for model_name, model in trained_models.items():
print(f"正在對 {model_name} 模型進行回測...")
# Perform DRL prediction using the model
df_account_value, df_actions = DRLAgent.DRL_prediction(
model=model, environment=e_trade_gym)
# Calculate daily returns for the model
df_account_value['daily_return'] = df_account_value[
'account_value'].pct_change().fillna(0)
# Store backtest results
backtest_results[model_name] = {
'account_value': df_account_value,
'actions': df_actions,
'daily_return': df_account_value['daily_return']
}
# Output the first few rows of backtest results for verification
print(f"{model_name} 模型的帳戶價值前幾行:")
print(df_account_value.head())
print(f"{model_name} 模型的交易動作前幾行:")
print(df_actions.head())
return backtest_results
def calculate_dji_daily_return(start_date, end_date):
"""
Calculate daily returns for the DJI index.
Parameters:
- start_date: The start date for fetching DJI data.
- end_date: The end date for fetching DJI data.
Returns:
- baseline_returns: Pandas Series containing daily returns for the DJI index.
"""
from finrl.plot import get_baseline, get_daily_return
# Fetch baseline DJI data
baseline_df = get_baseline(ticker='^DJI', start=start_date, end=end_date)
# Calculate daily returns for DJI
baseline_returns = get_daily_return(baseline_df, value_col_name="close")
return baseline_returns
# df_dji = YahooDownloader(
# start_date=start_date, end_date=end_date, ticker_list=["dji"]
# ).fetch_data()
# df_dji = df_dji[["date", "close"]]
# fst_day = df_dji["close"][0]
# dji = pd.merge(
# df_dji["date"],
# df_dji["close"].div(fst_day).mul(1000000),
# how="outer",
# left_index=True,
# right_index=True,
# ).set_index("date")
# daily_return = dji["close"].pct_change(1).fillna(0)
# return daily_return
def plot_html(trace_list, time_ind):
fig = go.Figure()
for trace in trace_list:
fig.add_trace(trace)
fig.update_layout(legend=dict(x=0,
y=1,
traceorder="normal",
font=dict(family="sans-serif",
size=15,
color="black"),
bgcolor="White",
bordercolor="white",
borderwidth=2), )
#fig.update_layout(legend_orientation="h")
fig.update_layout(
title={
#'text': "Cumulative Return using FinRL",
'y': 0.85,
'x': 0.5,
'xanchor': 'center',
'yanchor': 'top'
})
#with Transaction cost
#fig.update_layout(title = 'Quarterly Trade Date')
fig.update_layout(
# margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor='rgba(1,1,0,0)',
plot_bgcolor='rgba(1, 1, 0, 0)',
#xaxis_title="Date",
yaxis_title="Cumulative Return",
xaxis={
'type': 'date',
'tick0': time_ind[0],
'tickmode': 'linear',
'dtick': 86400000.0 * 80
})
fig.update_xaxes(showline=True,
linecolor='black',
showgrid=True,
gridwidth=1,
gridcolor='LightSteelBlue',
mirror=True)
fig.update_yaxes(showline=True,
linecolor='black',
showgrid=True,
gridwidth=1,
gridcolor='LightSteelBlue',
mirror=True)
fig.update_yaxes(zeroline=True,
zerolinewidth=1,
zerolinecolor='LightSteelBlue')
fig.show()
def plot_cumulative_returns(backtest_results,
time_ind,
min_var_daily_return=None,
dji_daily_return=None,
sp500_daily_return=None):
"""
Function to plot cumulative returns for DRL models, Min-Variance, and DJI.
Parameters:
- backtest_results: Dictionary containing daily returns for different DRL models.
- time_ind: Pandas Series of dates (x-axis values).
- min_var_daily_return: (Optional) Daily returns for the Min-Variance model. Default is None.
- dji_daily_return: (Optional) Daily returns for the DJI index. Default is None.
"""
# Initialize the figure
trace_list = []
# Loop through backtest results and add traces for each model's cumulative returns
for model_name, result in backtest_results.items():
df_daily_return = result['daily_return']
# 計算累積回報 (Cumulative Returns)
daily_return = df_daily_return if type(
df_daily_return) == pd.Series else df_daily_return['daily_return']
cumpod = (daily_return + 1).cumprod() - 1
# Add trace for each model's cumulative return
trace = go.Scatter(x=time_ind,
y=cumpod,
mode='lines',
name=f'{model_name} (Stock Trading)')
trace_list.append(trace)
# Conditionally add Min-Variance cumulative return trace if provided
if min_var_daily_return is not None:
# 計算MVO累積回報
min_var_cumpod = (min_var_daily_return + 1).cumprod() - 1
trace_min_var = go.Scatter(x=time_ind,
y=min_var_cumpod,
mode='lines',
name='Min-Variance')
trace_list.append(trace_min_var)
# Conditionally add DJI cumulative return trace if provided
if dji_daily_return is not None:
# 計算DJI累積回報
dji_cumpod = (dji_daily_return + 1).cumprod() - 1
trace_dji = go.Scatter(x=time_ind,
y=dji_cumpod,
mode='lines',
name='DJIA')
trace_list.append(trace_dji)
if sp500_daily_return is not None:
# 計算DJI累積回報
sp500_cumpod = (sp500_daily_return + 1).cumprod() - 1
trace_sp500 = go.Scatter(x=time_ind,
y=sp500_cumpod,
mode='lines',
name='S&P 500')
trace_list.append(trace_sp500)
plot_html(trace_list, time_ind)
def check_data_alignment(df, ticker_key='tic', date_key='date'):
# 提取唯一日期和股票代碼
unique_date = df[date_key].unique()
unique_tic = df[ticker_key].unique()
# 使用itertools.product生成日期和股票代碼的笛卡爾積
combinations = list(itertools.product(unique_date, unique_tic))
# 將組合轉換為DataFrame
df_combinations = pd.DataFrame(combinations,
columns=[date_key, ticker_key])
# 使用左合併將所有可能的(date, tic)與原始df對齊
merged_df = df_combinations.merge(df,
on=[date_key, ticker_key],
how='left')
# 檢查是否有缺失的數據
missing_data = merged_df.isna().any(axis=1)
# 找出缺失數據的行
if missing_data.any():
missing_combinations = merged_df[missing_data][[date_key, ticker_key]]
print("The following (date, ticker) combinations are missing data:")
print(missing_combinations)
return False
print(
"Data alignment complete. Every date has data for all tics (even if NaN)."
)
return True
def calculate_sp500_hourly_return(start_date, end_date, train_df):
"""
Calculate hourly returns for the S&P 500 index by matching each hour to the corresponding day's data.
Parameters:
- start_date: The start date for fetching S&P 500 data.
- end_date: The end date for fetching S&P 500 data.
- train_df: The hourly train dataframe which contains the datetime column.
Returns:
- hourly_returns: Pandas Series containing hourly returns for the S&P 500 index.
"""
from finrl.plot import get_baseline, get_daily_return
# Fetch baseline S&P 500 daily data
baseline_df = get_baseline(ticker='^GSPC', start=start_date, end=end_date)
# Calculate daily returns for S&P 500
daily_returns = get_daily_return(baseline_df, value_col_name="close")
# Ensure 'date' is in datetime format
train_df['date'] = pd.to_datetime(train_df['date'])
train_df['date_only'] = train_df['date'].dt.date
# Get the first timestamp of each day in the hourly data
first_hour_per_day = train_df.groupby(
'date_only')['date'].min().reset_index()
# Merge the daily returns data with the first hour of each day
first_hour_per_day = pd.merge(first_hour_per_day,
daily_returns,
left_on='date_only',
right_on=daily_returns.index.date,
how='left')
# Set 'date' (first hour of each day) as the index for the merged data
first_hour_per_day.set_index('date', inplace=True)
# Extract all hourly timestamps for a random stock (example)
random_tic = train_df['tic'].sample(n=1).iloc[0] # Get random 'tic'
full_hourly_date = train_df[train_df['tic'] == random_tic]['date']
# Create a DataFrame for hourly returns with 0s as default
hourly_returns = pd.DataFrame(index=full_hourly_date)
hourly_returns['daily_return'] = 0.0
# Map the daily return to the first hour of each day
matched_dates = first_hour_per_day.index.intersection(full_hourly_date)
# Update the matched dates in hourly_returns with the correct daily return
hourly_returns.loc[matched_dates, 'daily_return'] = first_hour_per_day.loc[
matched_dates, 'daily_return'].values
return hourly_returns['daily_return'].fillna(0)
def calculate_dji_hourly_return(start_date, end_date, train_df):
"""
Calculate hourly returns for the DJI index by matching each hour to the corresponding day's data.
Parameters:
- start_date: The start date for fetching DJI data.
- end_date: The end date for fetching DJI data.
- train_df: The hourly train dataframe which contains the datetime column.
Returns:
- hourly_returns: Pandas Series containing hourly returns for the DJI index.
"""
from finrl.plot import get_baseline, get_daily_return
# Fetch baseline DJI daily data
baseline_df = get_baseline(ticker='^DJI', start=start_date, end=end_date)
# Calculate daily returns for DJI
daily_returns = get_daily_return(baseline_df, value_col_name="close")
# Ensure 'date' is in datetime format
train_df['date'] = pd.to_datetime(train_df['date'])
train_df['date_only'] = train_df['date'].dt.date
# Get the first timestamp of each day in the hourly data
first_hour_per_day = train_df.groupby(
'date_only')['date'].min().reset_index()
# Merge the daily returns data with the first hour of each day
first_hour_per_day = pd.merge(first_hour_per_day,
daily_returns,
left_on='date_only',
right_on=daily_returns.index.date,
how='left')
# Set 'date' (first hour of each day) as the index for the merged data
first_hour_per_day.set_index('date', inplace=True)
# Extract all hourly timestamps for a random stock (example)
random_tic = train_df['tic'].sample(n=1).iloc[0] # Get random 'tic'
full_hourly_date = train_df[train_df['tic'] == random_tic]['date']
# Create a DataFrame for hourly returns with 0s as default
hourly_returns = pd.DataFrame(index=full_hourly_date)
hourly_returns['daily_return'] = 0.0
# Map the daily return to the first hour of each day
matched_dates = first_hour_per_day.index.intersection(full_hourly_date)
# Update the matched dates in hourly_returns with the correct daily return
hourly_returns.loc[matched_dates, 'daily_return'] = first_hour_per_day.loc[
matched_dates, 'daily_return'].values
return hourly_returns['daily_return'].fillna(0)
def main():
INIT_AMOUNT = 1000000
TRAIN_START_DATE = '2019-09-21'
TRAIN_END_DATE = '2023-12-01'
TRADE_START_DATE = '2024-01-01'
TRADE_END_DATE = '2024-09-21'
train = pd.read_csv("sp500_1hour_2019-09-21_2024-01-01_train.csv")
trade = pd.read_csv("sp500_1hour_2024-01-01_2024-09-21_trade.csv")
processed_full = pd.concat([train, trade], ignore_index=True)
train = data_split(processed_full, TRAIN_START_DATE, TRAIN_END_DATE)
trade = data_split(processed_full, TRADE_START_DATE, TRADE_END_DATE)
print(f"Training Data Length: {len(train)}")
print(f"Trading Data Length: {len(trade)}")
# Step 2: Define Model Configurations
models_info = {
A2C: {
"params": {
"n_steps": 5,
"ent_coef": 0.005,
"learning_rate": 0.0002
},
"total_timesteps": 50000,
"save_path": os.path.join(TRAINED_MODEL_DIR, 'agent_a2c.zip')
},
PPO: {
"params": {
"n_steps": 2048,
"ent_coef": 0.005,
"learning_rate": 0.0001,
"batch_size": 128,
},
"total_timesteps": 80000,
"save_path": os.path.join(TRAINED_MODEL_DIR, 'agent_ppo.zip')
},
DDPG: {
"params": {
"batch_size": 128,
"buffer_size": 50000,
"learning_rate": 0.001
},
"total_timesteps": 50000,
"save_path": os.path.join(TRAINED_MODEL_DIR, 'agent_ddpg.zip')
},
SAC: {
"params": {
"batch_size": 128,
"buffer_size": 100000,
"learning_rate": 0.0003,
"learning_starts": 100,
"ent_coef": "auto_0.1",
},
"total_timesteps": 70000,
"save_path": os.path.join(TRAINED_MODEL_DIR, 'agent_sac.zip')
},
TD3: {
"params": {
"batch_size": 100,
"buffer_size": 1000000,
"learning_rate": 0.001
},
"total_timesteps": 30000,
"save_path": os.path.join(TRAINED_MODEL_DIR, 'agent_td3.zip')
}
}
# Step 3: Train DRL Models
# Initialize StockTradingEnv for training
stock_dimension = len(train.tic.unique())
state_space = 1 + 2 * stock_dimension + len(INDICATORS) * stock_dimension
print(f"Stock Dimension: {stock_dimension}, State Space: {state_space}")
buy_cost_list = sell_cost_list = [0.001] * stock_dimension
num_stock_shares = [0] * stock_dimension
env_kwargs = {
"hmax": 100,
"initial_amount": INIT_AMOUNT,
"num_stock_shares": num_stock_shares,
"buy_cost_pct": buy_cost_list,
"sell_cost_pct": sell_cost_list,
"state_space": state_space,
"stock_dim": stock_dimension,
"tech_indicator_list": INDICATORS,
"action_space": stock_dimension,
"reward_scaling": 1e-4
}
e_train_gym = StockTradingEnv(df=train, **env_kwargs)
# Train models
trained_models = train_drl(e_train_gym, models_info)
# Step 4: Backtest Models
# Initialize trading environment
e_trade_gym = StockTradingEnv(df=trade, **env_kwargs)
# Backtest trained models
backtest_results = backtest_drl(e_trade_gym, trained_models)
trade_dates = pd.to_datetime(trade['date'].unique()).sort_values()
dji_hourly_returns = calculate_dji_hourly_return(TRADE_START_DATE,
TRADE_END_DATE, trade)
sp500_hourly_returns = calculate_sp500_hourly_return(
TRADE_START_DATE, TRADE_END_DATE, trade)
plot_cumulative_returns(backtest_results,
trade_dates,
dji_daily_return=dji_hourly_returns,
sp500_daily_return=sp500_hourly_returns)
# Optional: Save backtest results
print("Backtest Results:")
for model_name, result in backtest_results.items():
print(f"{model_name}:")
print(result['daily_return'].head())
if __name__ == "__main__":
# Ensure directories exist
os.makedirs(TRAINED_MODEL_DIR, exist_ok=True)
os.makedirs(RESULTS_DIR, exist_ok=True)
main()


 iThome鐵人賽
iThome鐵人賽