由於由 Jira 匯入原始資料的工作表(命名為 Data:Raw)會因為更新,隨著排程定期去覆蓋,所以不適合在上面進行任何更動。所以為了利用這些資料,需要建立其他工作表去讀取予計算。
在繪製圖表前,先將這些屬於數據轉變成指標,再透過指標的趨勢繪製成圖表。所以接下來要進行資料的正規化,預期會有以下步驟。
挑選有用的資料
如果從 Jira 匯入的資料仍有些雜訊,或是希望再透過人工去做點修飾,那筆者建議在計算數據前,建立一個名為 Data:Selected 的工作表作為緩衝(截圖的工作表名稱誤寫成 Date: Selected ,先在這邊提醒讀者,之後會修改)。
挑選方式有可以是:
Data:Raw 的資料,不做篩選。好處是未來若需要臨時改成另外篩選的方式,已經建立起這個緩衝區。另外也可以針對原始資料進行一些自動化的樣式處理,取檢查原始資料有沒有要調整的地方。🔎 公式(Formula)與函式(Function)
在 Google Sheet 中,公式(formula)泛指在儲存格中以
=開頭的敘述,例如=1+2或是=COUNTA($B$2:B2),而函式(function)則是指COUNTA()這種以單詞與括號組成,給予參數後會返回處理過結果的公式元素。
下面會示範怎麼去設定公式協助,請參考下方 Raw: Data 工作表的截圖,以此定位資料欄列的編號去理解公式的含義。若圖片與程式碼方塊的公式有些微差異,則以程式碼區塊為主。
| Raw:Data | A | B | C | D | E | F | G | H | I | J | K | L | M | N |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Issue Type | Key | Summary | Status | Story point estimate | Created | refined at | selected at | began to develop at | developed at | tested at | reviewed at | deployed at | Updated |
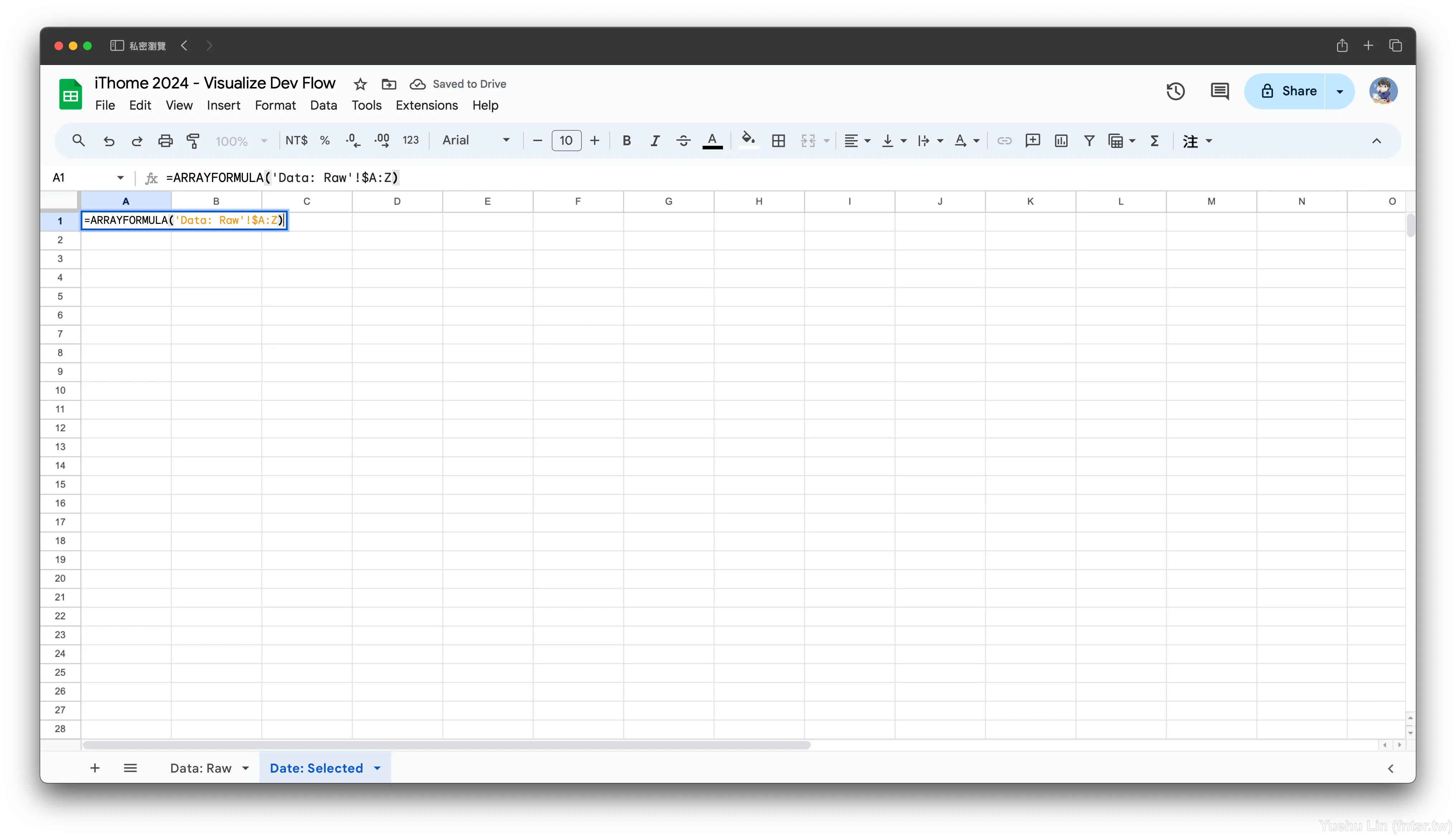
全部挑選可以透過下列公式去獲取。
=ARRAYFORMULA('Data: Raw'!$A:$Z)
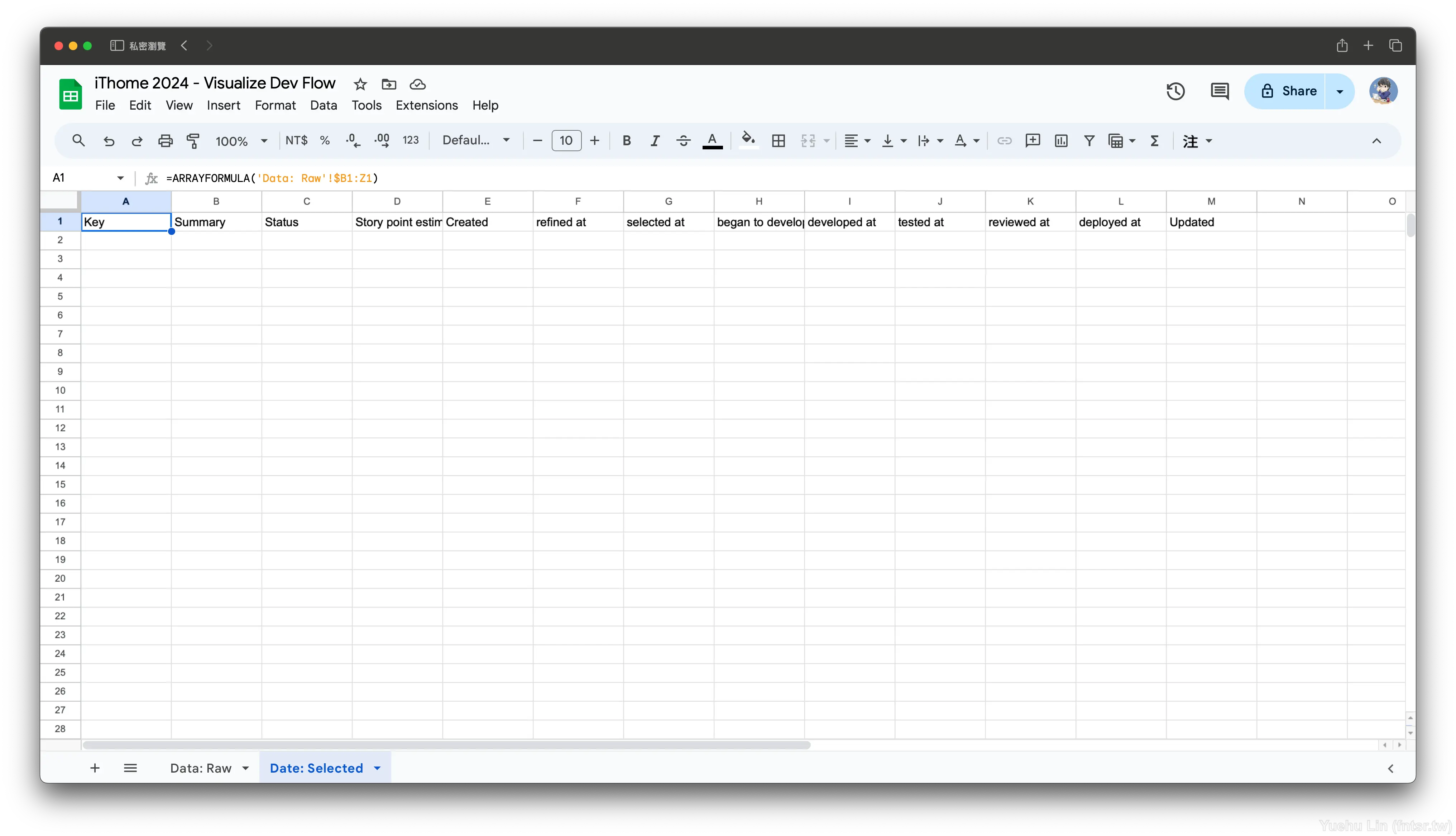
半自動選取的話,可以先在 A1 設定以下公式,自動去對應 Data: Raw 的標題列。
=ARRAYFORMULA('Data: Raw'!$B1:$Z1)
接下來預期 Key (A) 欄是由使用者自行輸入,(B) 欄與之後的欄位由公式代為輸入。所以 (B) 欄除了標題列以外都套用下方公式。可以先在 B2 輸入,然後再往下拖曳去套用到其他列。
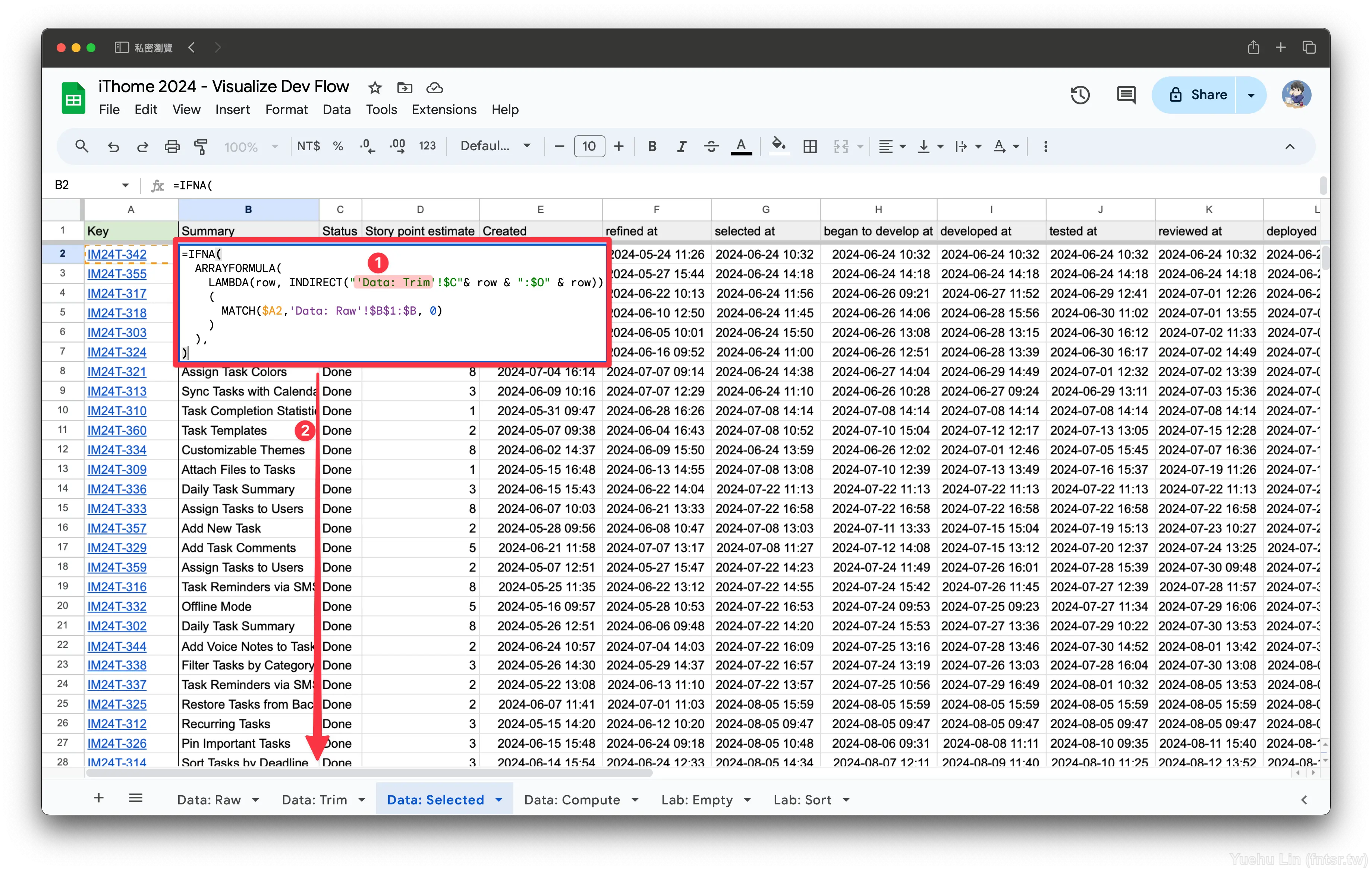
=IFNA(
ARRAYFORMULA(
LAMBDA(row, INDIRECT("'Data: Raw'!$C"& row & ":$O" & row))
(
MATCH($A2,'Data: Raw'!$B$1:$B, 0)
)
),
)

之後只要在 Key (A) 欄複製 Raw: Data 那種包含超連結的鍵值,或是純文字輸入鍵值,就會自動幫忙對應該 issue 的資料到後面的欄位了。
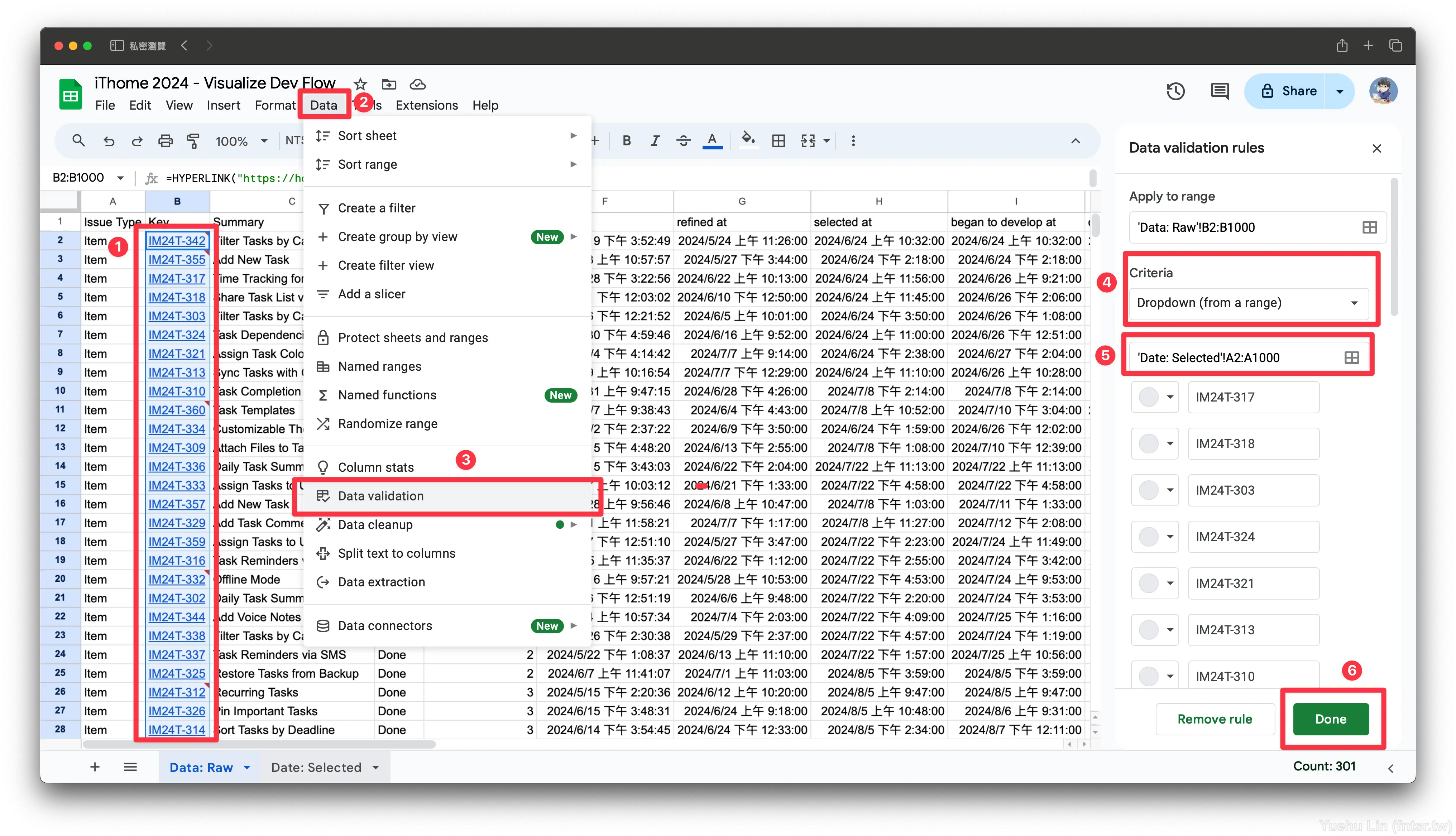
但這種方式可能會有個困擾是,忘記 Raw: Data 工作表中還有哪些 issue 是沒有選取過的,這時候就可以在 Raw: Data 工作表設定 Data validation(資料驗證)去協助示意。照樣沒有選取過的就會在儲存格的右上角有個紅色的警示符號。

首先選取 Raw:Data 的 B 欄中的資料,通常是 B2 到 B1000 ,接著點擊選單列 Data 中的 Data validation(資料驗證),等到右邊出現其設定面板時,點擊 Add rule。在設定驗證規則的頁面中,設定驗證方式為 Dropdown (from a range) (下拉式選單 (來自某範圍)),並且在下方輸入框輸入要比對的範圍,也就是 ='Date: Selected'!$A$2:$A$1000 ,意即 Data: Selected (A) 欄中的資料,如此便大功告成。會使用 Data validation 而不是 Condition Formatting 的原因在於這種方式不會被 Jira Cloud for Sheets 更新資料時洗掉。
計算指標的前置作業
接著再建立一個名為 Data: Computed 表作為計算用的。在這裡筆者有一個原則,為了方便編寫,以及更容易維護,所有計算應該都直接在這個工作表進行,不要再參照到其他工作表;而若圖表要參照相關資料,也應當不用再計算,透過 ARRAYFORMULA() 函式直接使用即可。
所以在這裡一樣會再參照一次 Data: Selected 工作表的資料,不過這裡可以再作點變化,不是直接透過 ARRAYFORMULA() 進行引用,而是透過 SORT() ,讓引用的資料按照指定欄位去排序。
這裡的考量是與未來製作圖表有關,比如說 Lead Time Run Chart 是按照交付的順序去排序,那如果在 Data: Computed 就先以這樣的順序排序,再對照檢視時會更加方便。
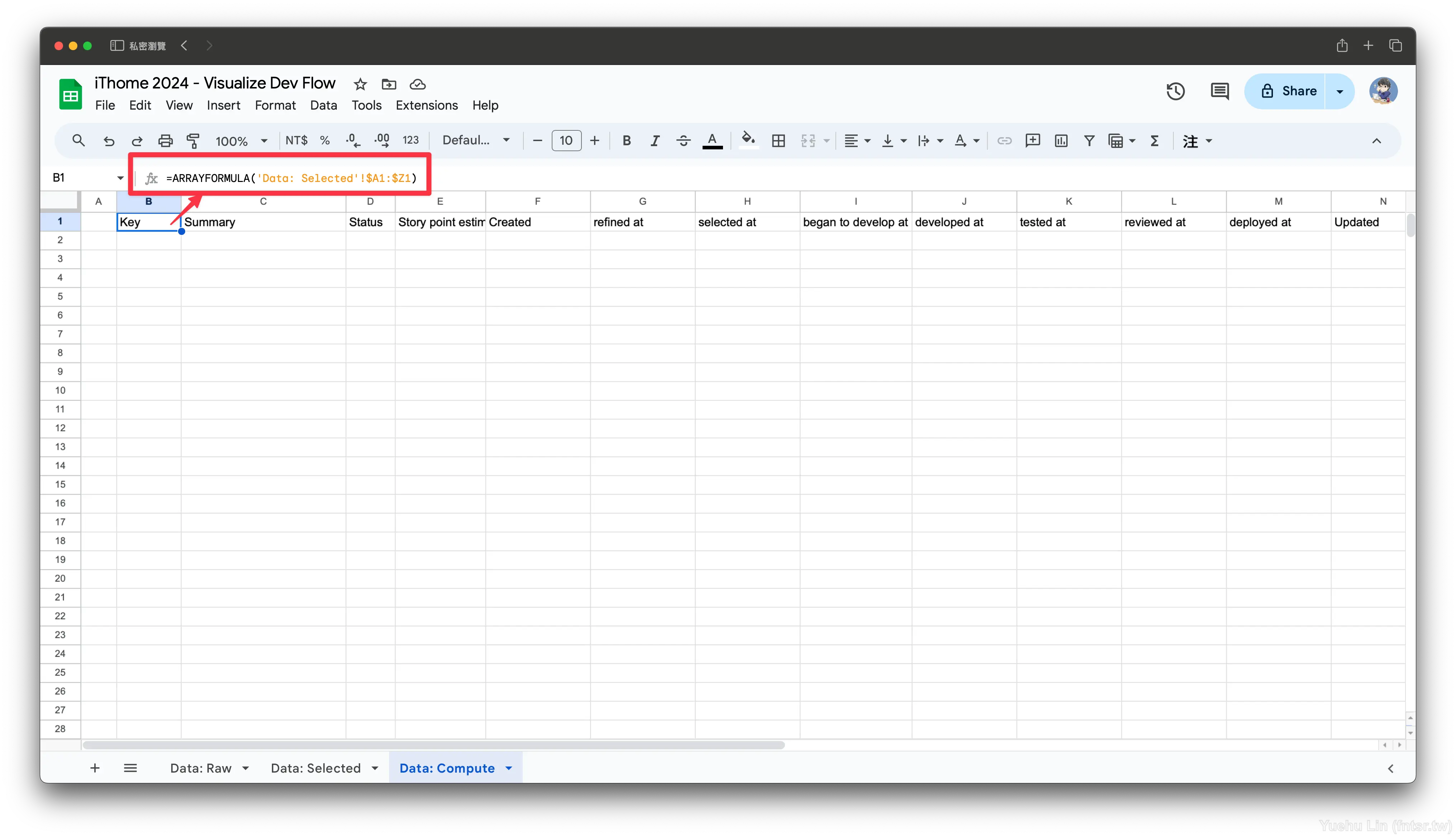
首先一樣透過 ARRAYFORMULA() 引用標題列,但這裡引用的是 Data: Selected 工作表。
=ARRAYFORMULA('Data: Selected'!$A1:$Z1)
接著透過 SORT() 進行排序,這裡排序的方式除了上面提過的已交付順序排序為,也參考自 Kanban 的標語:「停止啟動,聚焦完成」(stop starting start finishing),讓越該先被完成的放上面,包括越後面的階段,同階段則是越早開始的,一路從 deployed at、reviewed at、tested at、developed at、began to develop at、selected at,讓這些已經開始投入心力,客戶開始等待的 issue,越接近完成、時間戳越早發生的排越前面,力求讓 lead time 越短越好。
而 refined at 和 created at 這類還沒則反過來,越晚發生的排越前面,因為越新的資訊重要性通常越高,越舊的 issue 通常也不急於一時,所以就往後排。
SORT() 函式中的數字代表是指定範圍中的第幾個欄位,TRUE 為遞增,FASLE 為遞減。
=SORT('Data: Selected'!A2:P, 12, TRUE, 11, TRUE, 10, TRUE, 9, TRUE, 8, TRUE, 7, TRUE, 6, FALSE, 5, FALSE)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Key | Summary | Status | Story point estimate | Created | refined at | selected at | began to develop at | developed at | tested at | reviewed at | deployed at | Updated |

但這時候會發現 refined at 順序並不如預期,照理說有數值的列應該會比空白還更前面,但這裡卻是先空白再來是數值。
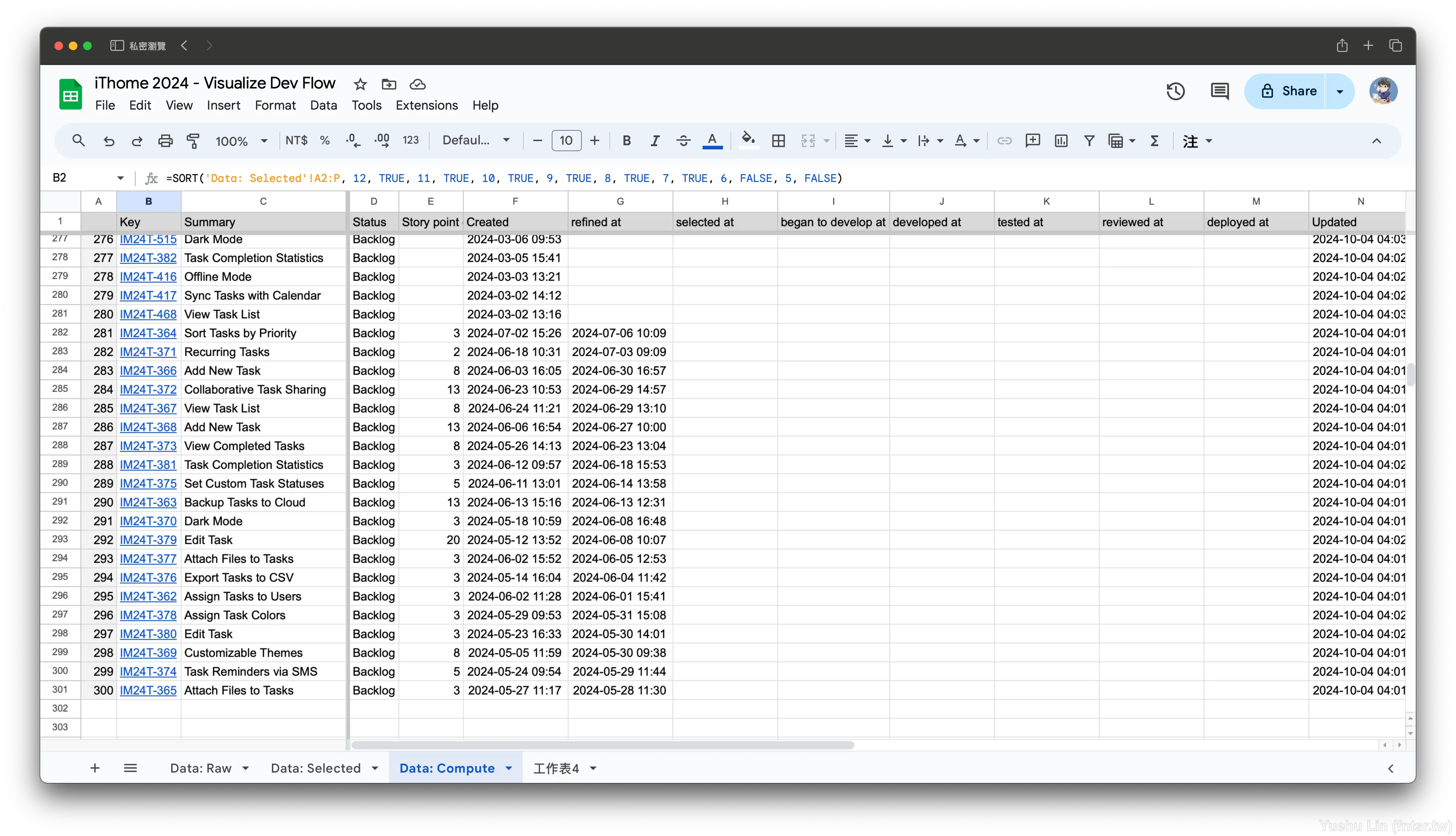
這就是一個小細節了,眼睛看到的空白,對於 Google Sheet 來說不一定等於空白,如果讀者這時候透過 ISBLANK(cell) 指向儲存格,會發現回傳的數值是 FALSE !這是為什麼呢?
其實那些看似空白的儲存格,實為是空字串,而空字串就不是空白儲存格(empty cell),對於 ISBLANK() 來說,在儲存格中放了空字串,還是有放東西,那就不是空的(empty)。顯示沒東西和是否為空是兩回事。這就是 與 "" 的差異。空白儲存格在型別上也會被判定是 Number,而空字串則是 Text。

所以為了解決排序的問題,這邊筆者先採取一個簡單暴力的做法——另外建立一個工作表 Data: Trim ,透過下列公式去清理空字串。也就再透過 ARRAYFORMULA() 函式引用時,會檢查每一個值是否為空字串,是空字串則返回空值,若不是則返回原值)
=ARRAYFORMULA( IF('Data: Raw'!A:Z="", , 'Data: Raw'!A:Z) )

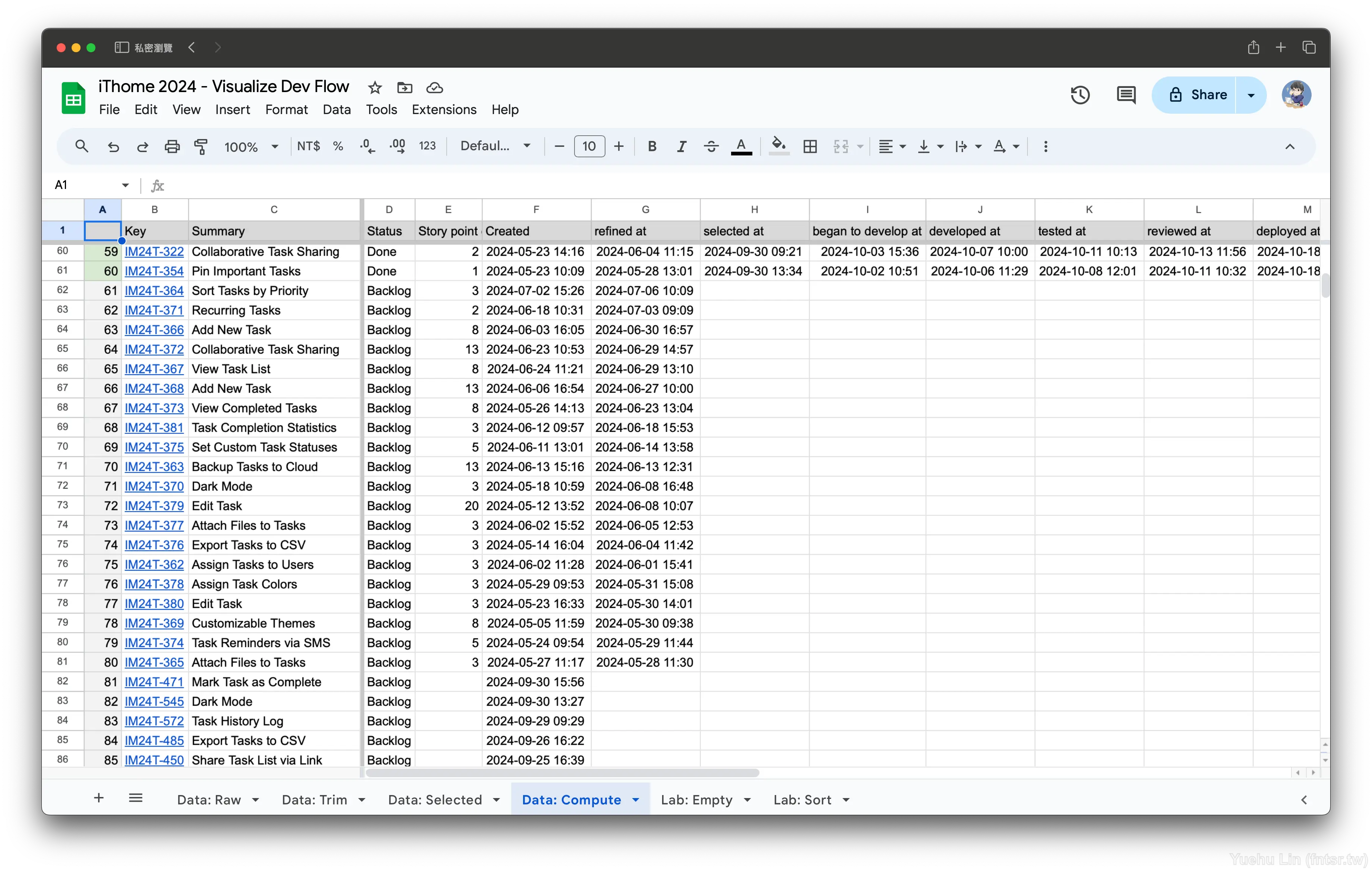
並且將 Data: Selected 中參照的工作表從 Data: Raw 改成 Data: Trim 。
這時候回到 Data: Computed 就會發現按照預期的方式排序了。這樣做的好處也是預防未來邊寫公式時,再度踩到空值與空字串難以識別的坑。
另外針對各資料型別透過 SORT() 函式排序,筆者也做了點實驗去求解,如圖。排序大致是:
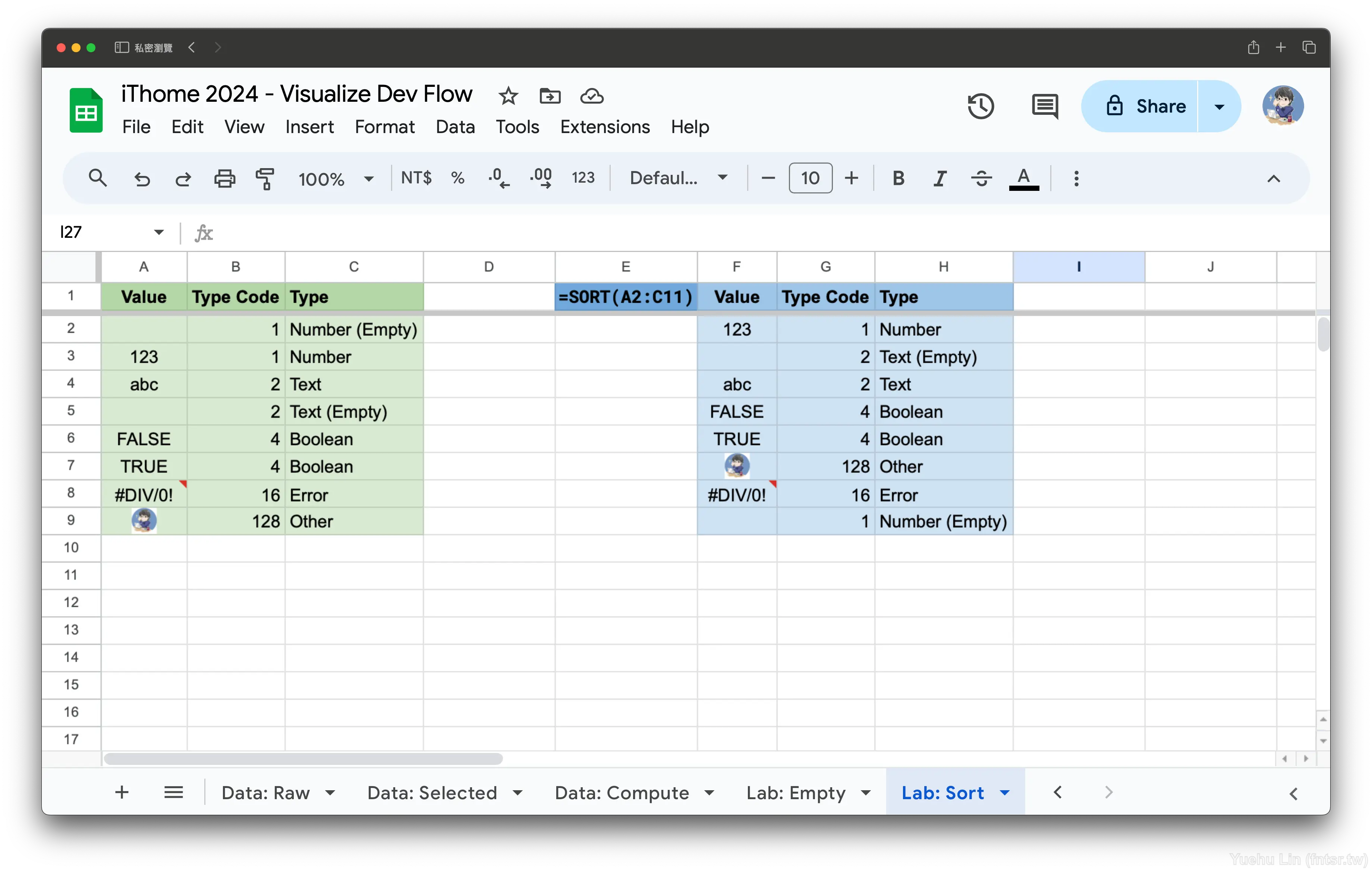
排序解決,往下進行。
剛剛在建立計算指標要參照的資料時,或許覺察力敏銳的讀者可能已經發現筆者刻意將 (A) 欄空下,這邊的確是有所圖的。筆者建議這邊放上排序順序的編號,並且可以按照其狀態上色。這樣做的考量是因為預期 Data: Computed 會是一個欄位超級多、寬度廣闊的工作表,看久了會不知道這一列是哪一個 PBI,所以需要凍結前幾欄去示意,這邊選擇的是順序編號、issue 編號與標題。
這裡使用的是 COUNTA(range) ,用計算個數的方式來取得順序編號。搭配鎖定字元 $ ,就可以得知從 $B$2 到某列的順序編號。 IF() 則是讓 (A) 欄只會在 (B) 欄有值時去取得順序編號。
=IF(B2="", , COUNTA($B$2:B2))
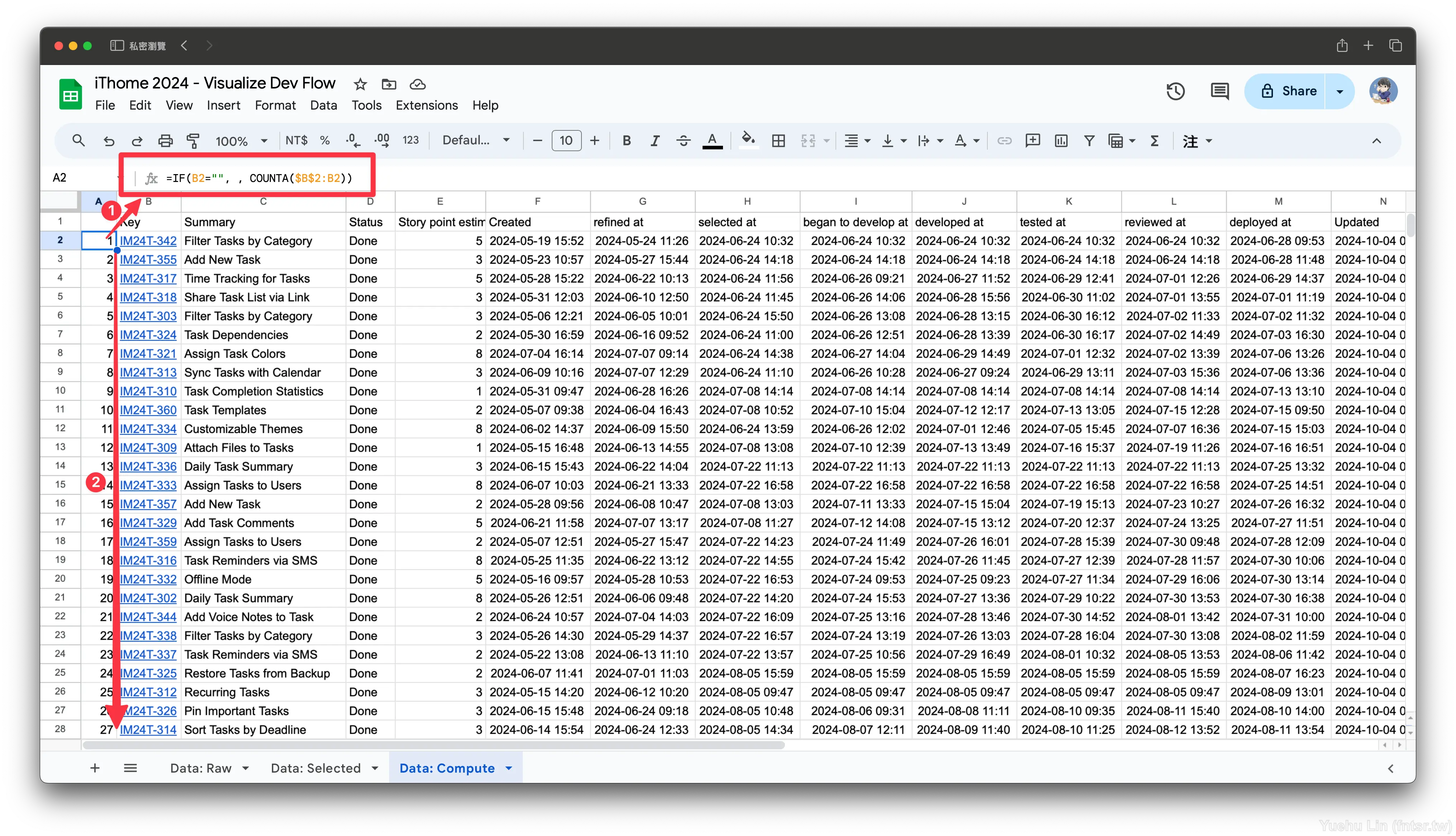
最後簡單做的樣式排版與修飾,這邊筆者在 Done Order (A) 欄根據 Status (D) 欄去上色,並且在新增一列置頂,作為欄位組的命名,以便於後面新增更多欄位時,可以快速索引。

今天先談到這邊,明天就會正式進入到計算指標的環節。

