
如果沒有接觸過衍生資料系統的團隊成員,可能比較難理解 Day 21 我們談到資料流上下游的耦合性。我們就用下方這張圖一探究竟。
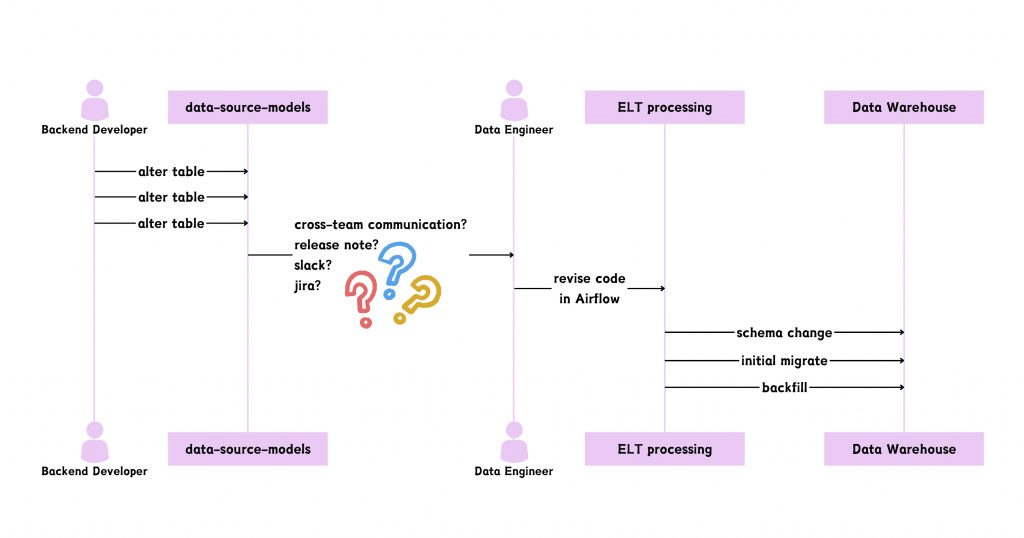
圖/資料工程師在整個資料流的運補過程。簡書廷製。
先前提及的工具包含 Airflow、Debezium、Kafka 及 Flink,通通都是用於從資料源把資料介接出來,送到下游運用的技術。但是資料源象徵一間公司的業務命脈,為了讓公司產品在變化多端的市場有更好的配適度 (product market fit),資料源的結構不可能一成不變。而只要一變動,就是資料工程師頭痛的開始。
從圖中可看到,資料源的後端工程師修改了資料模型 (models),可能是新增欄位或是修改欄位格式等。常出現一個情況是,使用資料倉儲的使用者如資料分析師、機器學習工程師等夥伴來和資料工程團隊反映某些出現在資料源的欄位資料無法取用到,我們才意識到,原來源頭的資料模型被改變了!
因職能分工的關係,資料源與下游 ELT 流程處理的開發者通常分屬不同團隊。跨團隊溝通是整條資料運補鏈裡面最容易出問題的地方,是要透過兩邊團隊的 Lead 或 PM 傳遞資訊?抑或是版本發佈公告 (release note)?由誰主動發起溝通?
資料分析師:『這張 users 表多了新的欄位,我在分析時需要用到。麻煩資料工程團隊盡量在一星期以內補上資料。』
資料工程師:『好。我們去和上游開發團隊詢問。(murmur:但為什麼分析師知道有業務上有新欄位,但上游沒告訴我們)』
後端工程師:『我們需要特別跟你們說欄位的新增和改動嗎?而且資料工程那邊應該就改個 SQL 很快吧?』
資料工程師:『……』
卡在資料流夾縫中的資料工程師,只有滿滿的無奈。
廣義的相容性 (compatibility) 指的是當一個系統的元件發生變更時,它仍然能夠與其他系統元件共同正常運作。在指稱 data pipeline 中資料流轉的情境時,相容性是指資料格式變動下,產製者 (producer) 和消費者 (consumer) 能否繼續相互理解並正確處理資料。
相容性有以下幾種類型:
上一段提及,後端開發者對於欄位進行增修但資料消費者不曉得這件事,當欄位型態直接改變,例如從 STRING 變成 ARRAY ,下游的 ELT 流程會直接崩壞,這也稱作破壞性修改 (breaking change)。
當此欄位是新增,而下游消費者並沒有預先定義 schema 進行嚴格的驗證,雖然系統是向前相容的。但無法收錄此欄位,就會造成資料運補困擾。
Day 19 討論的 Kafka 的企業雲端版 Confluent 就提供了一個資料格式管理的重要工具 Schema Registry。它提供了一個集中儲存庫,用來管理和驗證 Kafka 每個主題 (topic) 訊息資料的 schema。
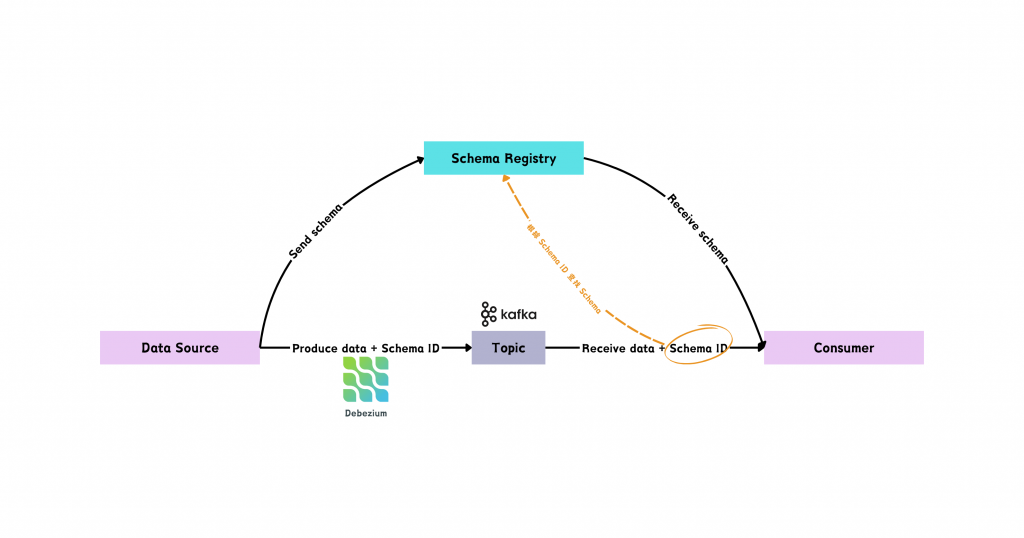
圖/Schema Registry 與資料產製者、資料消費者透過 Schema ID 進行格式驗證。簡書廷製。
在這個資料流轉的過程,資料產製者在產製資料時,會一併註冊一份資料格式到 Schema Registry 這個集中儲存庫,並將該格式 (schema) 的 Schema ID 連同資料發送給。資料消費者收到資料和 Schema ID 後,會根據這個 ID 去集中儲存庫找到對應的格式,就可以進行獲取資料的驗證與解析啦。
為什麼要解析?
還記得我們在 Day 18 有提到,不同種資料庫的日誌格式可能不同,所以在收到資料後,我們要把人讀不懂的二進位或壓縮格式進行解碼 (decoding),才能進行後續的運用。
例如,我們收到一份已經被字串化 (stringfy) 的 user 資訊:
'{\"name\": \"Alice\", \"age\": 30, \"city\": \"New York\"}'
如果要解析成 Python 的格式以利後續用 Python 開發 data pipeline 進行 ELT 流程,可以透過 json 套件進行解析,就能將資料轉換成 Python 的 dictionary 格式囉。
import json
data = '{"name": "Alice", "age": 30, "city": "New York"}'
decoded_data = json.loads(data)
在資料格式管理中,解析的動作叫做反序列化 (deserialization),而將資料物件轉換為一個可儲存/傳輸格式的對應動作叫做序列化 (serialization)。
若強調效率,我們可以透過開源格式 AVRO 來將資料序列化,便於在不同系統間傳輸和儲存。它還有幾個很明顯的優勢:
INT、STRING、BOOLEAN、FLOAT) 及複雜型態 (如 ENUM、ARRAY、 MAP、UNION)。以下是一份 AVRO 格式定義文件,是不是很清晰呢!
{
"type": "record",
"name": "users",
"namespace": "core",
"fields": [
{
"name": "user_id",
"type": "int",
"default": 99
},
{
"name": "name",
"type": "string",
"default": "unknown_person"
},
{
"name": "email",
"type": "string",
"default": "unknown@example.com"
},
{
"name": "created_at",
"type": {
"type": "string",
"logicalType": "timestamp-micros"
},
"default": "1970-01-01T00:00:00.000000Z"
},
{
"name": "is_active",
"type": "boolean",
"default": false
}
]
}
我們可以選用 AVRO 和 Schema Registry 來管理資料的結構和格式。Kafka 產製者將資料以 AVRO 格式序列化,並將 schema 儲存到 Schema Registry,這樣消費者可以依據 Schema Registry 來解析資料,並驗證資料結構。甚至可以取用 schema 來進行 ELT 流程的程式碼修改,確保資料運補的順暢及資料完整性。
這樣的設計能幫助大型系統架構下,管理複雜的資料結構或格式變更,減少資料流轉時發生解析錯誤,或是跨團隊間疏於溝通造成的格式不相容問題。

