
在經過了先前對於 Grafana Alerting 與 Prometheus AlertManager 的介紹後,我們對於告警事件系統的觀念已經有了基本的認識,這對我們認識 Grafana Alerting 的設定有很大的幫助。
接下來我們將會以 Grafana Alerting 為核心,探討告警事件管理上需要注意的痛點與最佳實踐。這些通用的觀念絕大部分也適用於其他告警事件管理系統,如 Prometheus AlertManager 等,畢竟兩者皆是基於 Prometheus 為基礎設計的告警事件解決方案。
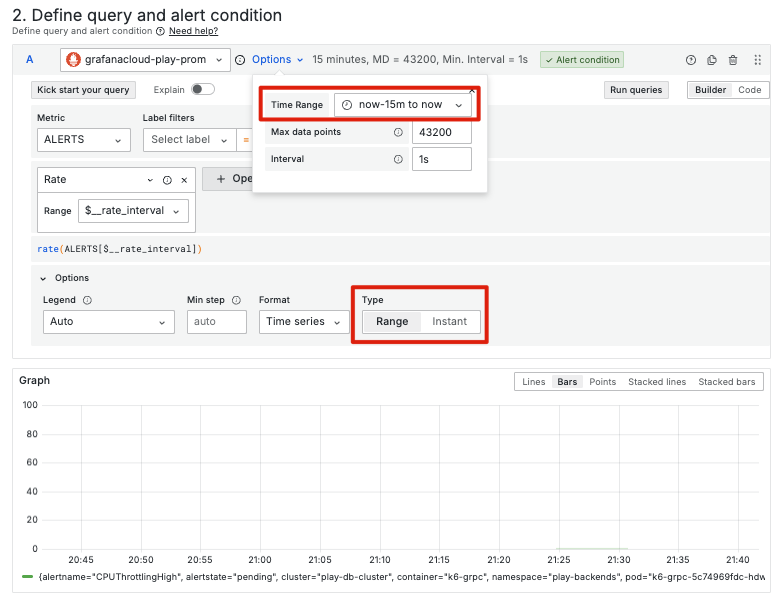
在 Grafana Alerting 中,設定告警時需要明確指定告警規則的查詢類型,分別為:Instant Query 與 Range Query。每個查詢類型都有其適用的場景。相較之下,Prometheus 的告警規則只支援 Instant Query,而 Grafana Alerting 則提供了更靈活的選擇。
以下是兩者的差異:
而以上的查詢類型,都會在我們設定的 Time Range 中進行評估。我們必須特別注意 Time Range 是否設定恰當。假如我們只需要每 5 分鐘評估一次 CPU 使用率,那我們就應該將 Time Range 設定為 5 分鐘,而不是更長或更短的區間。
在設置 Grafana Alerting 的告警規則時,為每個查詢賦予適當的名稱是一個值得關注的細節。這樣做的好處在於,當我們在通知模板中使用變量 {{ $value }} 來帶出查詢結果時,可以更清晰地反映資料的意義,增強通知內容的可讀性和參考價值。
假如我們的告警規則是檢查某個實例的 CPU 使用率,我們可以將告警規則命名為:
CPU usage for {{ index $labels "instance" }} has exceeded 80% for the last 5 minutes: {{ $value }}
結果將會是:
CPU usage for instance1 has exceeded 80% for the last 5 minutes: [ var='A' labels={instance=instance1} value=81.234 ]
這樣的命名方式不僅清晰地描述了告警的內容,還包含了實例名稱和 CPU 使用率的具體數值,使得通知內容更具體和有價值。
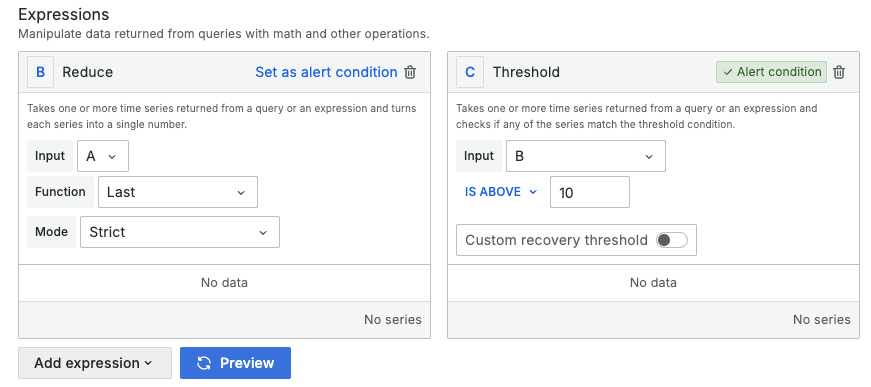
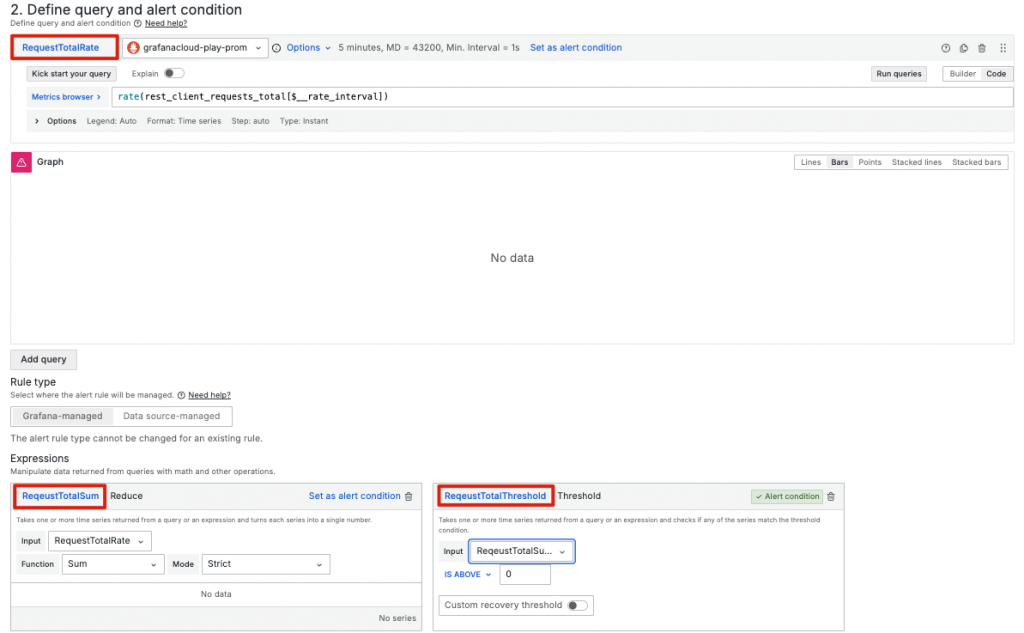
設置告警條件時,要考慮如何構建精確且有意義的條件組合。Grafana 提供了多條件組合的功能,允許使用者在一條告警規則中使用多個查詢結果,來當作觸發告警規則的依據(alert condition)。
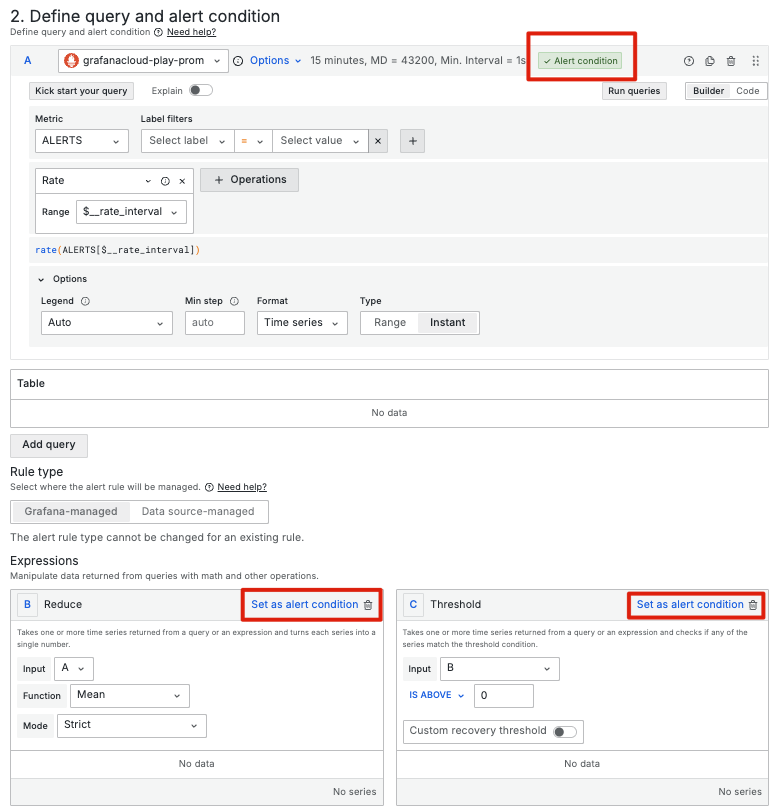
但需要注意的是,如果在 Grafana Alerting 中設定了三個查詢(refId: A、refId: B 和 refId: C),但在 Alert Condition 中僅指定了 A,那麼只有查詢 A 的結果會用於告警評估。在這種情況下,其他查詢(B 和 C)的處理將不會直接影響告警的觸發。不過在進階場景中,我們依然可以在通知模版中使用其他查詢結果,豐富我們的告警通知上下文。

在 Grafana 中,Folder 作為一個核心概念,不僅用於組織 Dashboard 層級,還在 Grafana Alerting 中扮演著重要角色。這種設計體現了 Grafana 對資源管理的統一思考:
通過這種設計,Grafana 實現了從 Dashboard 組織、告警規則分組到告警標籤的一致性。精心設計 Folder 結構和標籤體系,可以有效地連接和管理 Grafana 中的各類資源,包括儀表板、告警規則和通知策略等,從而提供一個統一、直觀且易於管理的監控和告警體系。我們會在後面介紹到,這樣的設計可以讓我們在通知策略中更方便地使用這些標籤來過濾和分組告警通知。
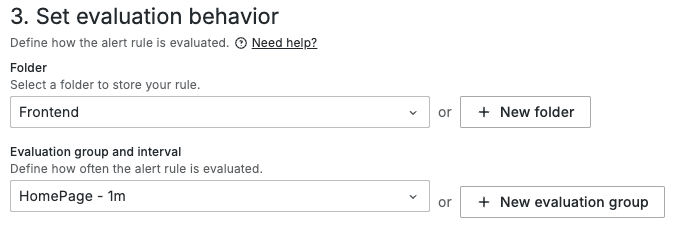
如同我們先前介紹過的,Grafana Alerting 的告警規則評估是基於 evaluation group 的,並且這個 evaluation group 是歸屬於指定的 Folder 之下。所以我們對於 evaluation group 的命名設計,可以貫徹我們對原本 Folder 的設計理念,如: Team > Service > Environment 的設計,將其視為我們在其中一層 Folder 中的附屬資源。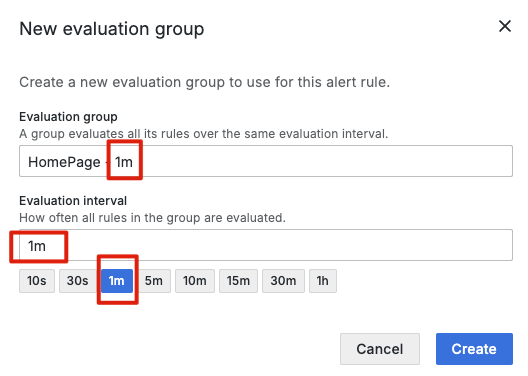
而每個 evaluation group 都有一個設定的評估間隔(evaluation interval),這個間隔決定了該組內所有告警規則的評估頻率。所以我們在設定 evaluation group 的命名時,可以加上評估間格的這個維度,如:
將需要相同評估頻率的告警規則放在同一個 evaluation group 中。這樣可以確保每個 evaluation group 的評估間隔是合理且高效,同時有不失彈性的操作空間。
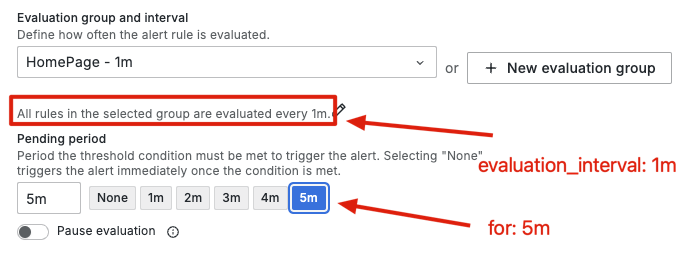
在 Alerting 中的 evaluation interval 和 pending period 可以拿來與 Prometheus 的 evaluation_interval 和 for 設定做對應。前者是告警規則的評估間隔,後者則是告警規則的 pending 狀態持續時間。兩者與告警規則的生命週期息息相關,我們也可以從先前的 Prometheus 告警規則生命週期範例中,看到這兩者的設定是如何影響告警規則的狀態轉換。此外,Grafana Alerting
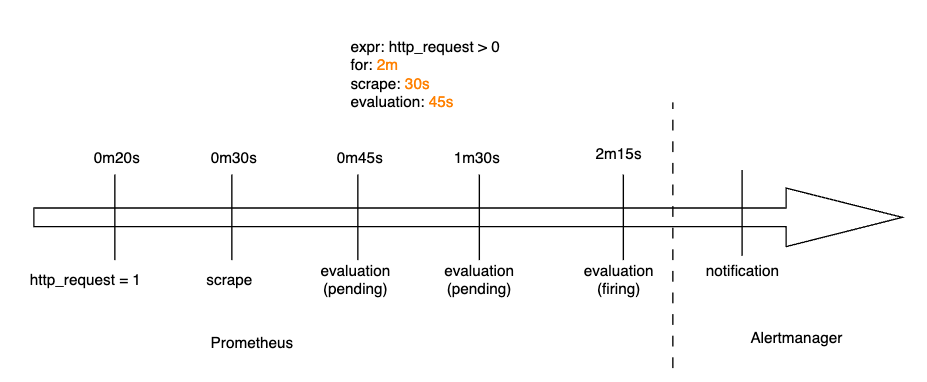
經過複習後,現在我們可以非常清楚的理解,evaluation interval 和 pending period 的設定會直接影響到告警事件被發送到告警通知元件前的狀態轉換。
告警暫停(Pauses)允許你暫時忽略特定的告警規則,直到特定時間點。但他與我們在前面介紹過的告警靜默(Silences)不同,告警靜默是暫時忽略需發送的告警事件,而告警暫停是直接忽略一段時間的告警規則評估,這在以下情況下非常有用:
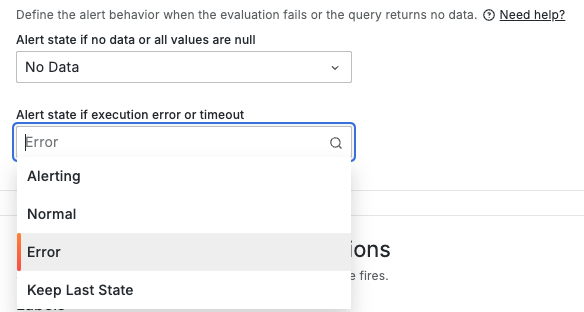
在 Grafana 中,我們可以透過設定 No Data 和 Error 的處理方式,來決定在遇到 No Data 和 Error 時,所需反應的預設行為。可以使用以下方法:
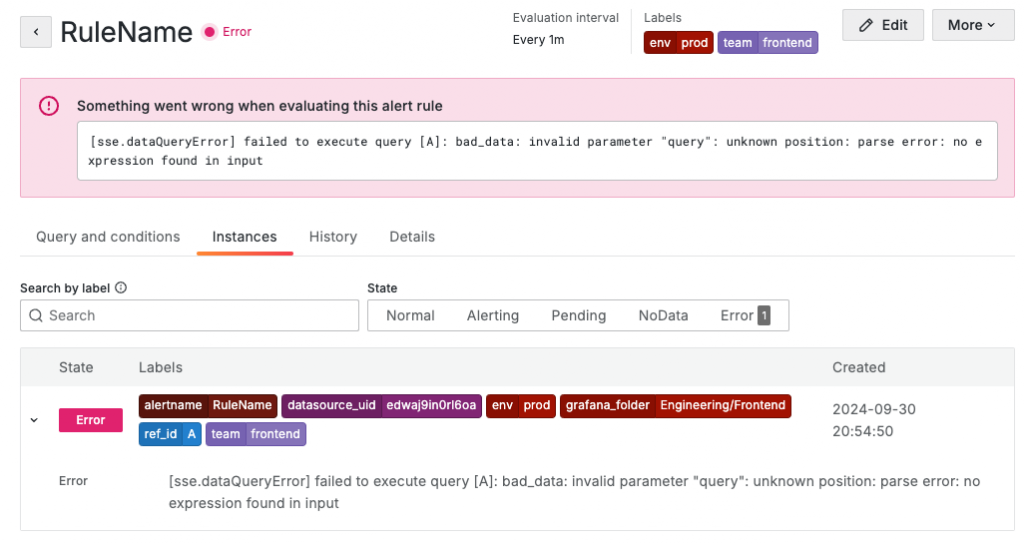
告警處於不明確狀態時,grafana_state_reason 註解會在通知中提供詳細原因。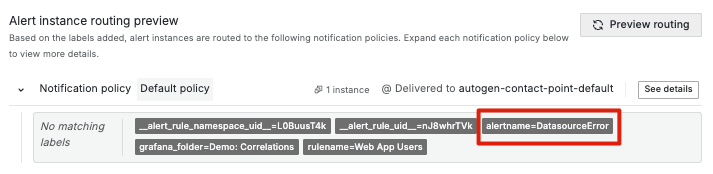
當評估產生 "No Data" 或 "Error" 狀態時,Grafana 會生成一個新的告警實例,包含特定的標籤,如 alertname(DatasourceNoData 或 DatasourceError)和 datasource_uid。這些告警可以像普通告警一樣進行管理,例如設定靜默或使用通知策略。
經過對 Grafana Alerting 的深入探討,我們不僅學習了告警規則的查詢類型、註釋和標籤的設定方法,還了解了如何利用 Evaluation Group 和告警規則評估間隔(evaluation interval)來優化告警策略。我們也討論了如何通過設置告警暫停(Pauses)來處理計劃維護、緊急維護和問題排查等情況,並掌握了在 No Data 和 Error 狀態下的處理方式。
Grafana Alerting 提供了靈活且強大的告警管理功能,允許我們以更直觀的方式組織和分類告警規則。透過良好的命名和標籤設計,可以有效地將告警事件和監控資源連結起來,使得整個監控和告警體系更加一致、易於管理。

